Hadoop二次开发深入解析:Mapper、Reducer与OutputFormat
201 浏览量
更新于2024-08-27
收藏 988KB PDF 举报
"Hadoop二次开发必懂(下)"
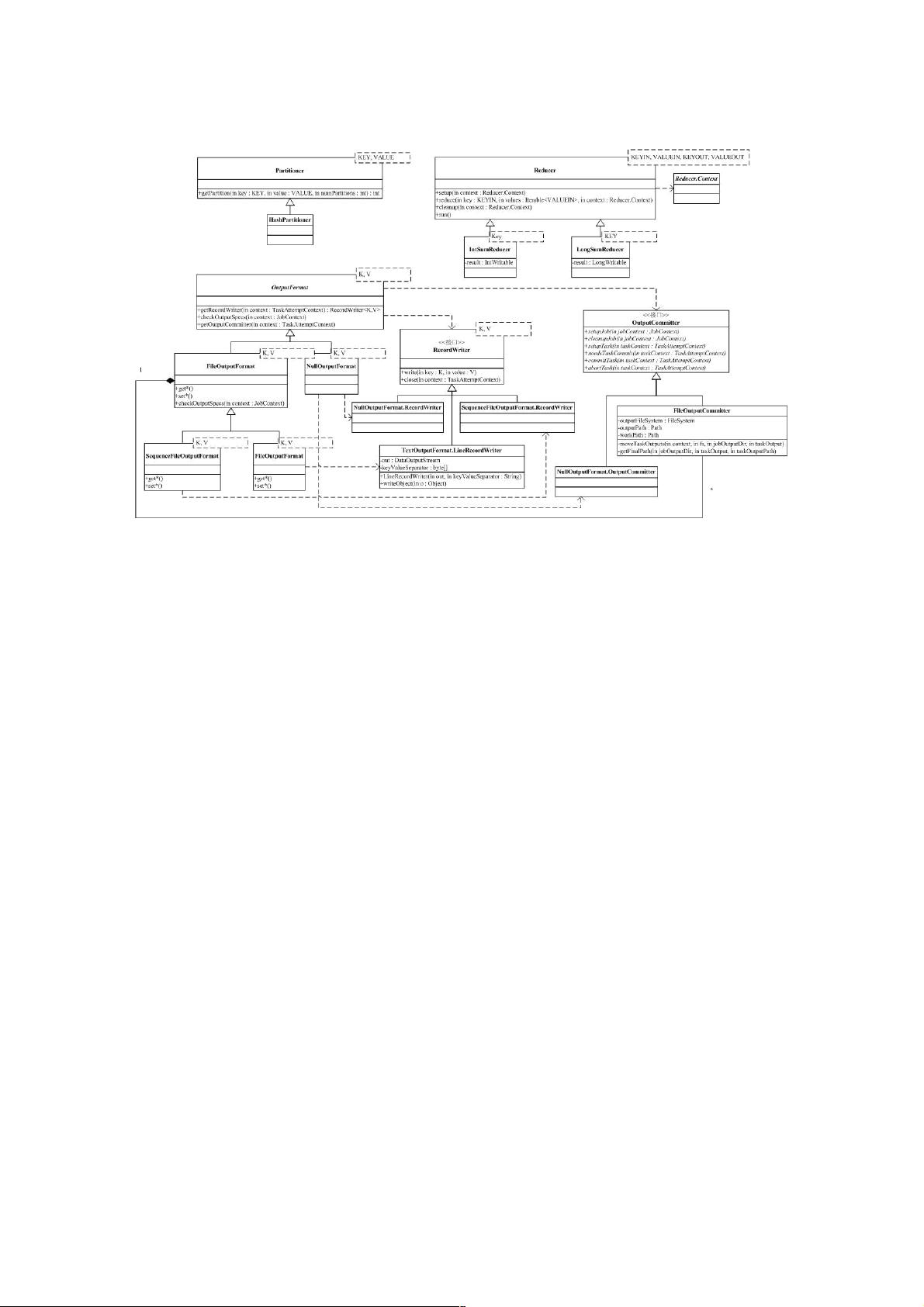
在Hadoop的生态系统中,二次开发是提高效率和优化性能的关键步骤。本节将深入解析MapReduce处理流程中的关键组件,包括Mapper、Combiner、Partitioner、Reducer以及OutputFormat。
Mapper是MapReduce任务的第一阶段,负责对输入数据进行初步处理。Mapper的结果,通常是形如<key, value>的一系列对,这些结果并不会直接写入输出文件,而是先经过可能存在的Combiner阶段。Combiner是一个可选的中间步骤,其功能类似于Reducer,但主要目的是在本地进行部分聚合,减少网络传输的数据量。由于Hadoop没有为Combiner定义专门的基类,而是直接使用Reducer作为Combiner的基础,因此Combiner和Reducer在逻辑上是等价的,只是运行时机和上下文不同。
接下来,Mapper的输出会根据Partitioner进行分布。Partitioner决定了哪些key的映射结果会被发送到特定的Reducer实例。默认情况下,Hadoop使用HashPartitioner,该Partitioner将key的哈希值对Reducer的数量取模,以此决定Reducer的编号。用户可以通过自定义Partitioner来改变key的分发策略,满足特定的业务需求。
Reducer是MapReduce的核心组件,它接收Mapper的输出并对相同key的值进行合并。Reducer类是所有用户自定义Reducer类的基类,具备setup、reduce、cleanup和run方法。setup和cleanup与Mapper中的作用相似,而reduce方法则执行实际的聚合操作,它接收一个key及其对应的value迭代器,然后进行相应的计算。例如,Hadoop内置的IntSumReducer和LongSumReducer分别用于对整型和长整型value求和。
Reducer的输出通过Reducer.Context的collect方法写入到文件系统,这个过程涉及OutputFormat。OutputFormat是一个接口,负责定义如何输出Reducer的结果。它依赖RecordWriter和OutputCommitter两个辅助接口。RecordWriter提供write方法用于写入<key, value>对,并通过close方法关闭输出。而OutputCommitter则允许用户自定义输出阶段的一些特殊操作,如文件确认和清理。
理解并掌握这些核心组件的工作原理对于进行Hadoop的二次开发至关重要,这可以帮助开发者优化性能,减少不必要的数据传输,以及实现更复杂的数据处理逻辑。通过定制Partitioner、Reducer和OutputFormat,开发者可以灵活地调整MapReduce作业以适应不同的大数据处理场景。
Hadoop二次开发必懂(下)二次开发必懂(下)
Map的结果,会通过partition分发到Reducer上,Reducer做完Reduce操作后,通过OutputFormat,进行输出,下面我们就来
分析参与这个过程的类。
Mapper的结果,可能送到可能的Combiner做合并,Combiner在系统中并没有自己的基类,而是用Reducer作为Combiner的
基类,他们对外的功能是一样的,只是使用的位置和使用时的上下文不太一样而已。
Mapper最终处理的结果对<key, value>,是需要送到Reducer去合并的,合并的时候,有相同key的键/值对会送到同一个
Reducer那,哪个key到哪个Reducer的分配过程,是由Partitioner规定的,它只有一个方法,输入是Map的结果对<key,
value>和Reducer的数目,输出则是分配的Reducer(整数编号)。系统缺省的Partitioner是HashPartitioner,它以key的Hash
值对Reducer的数目取模,得到对应的Reducer。
Reducer是所有用户定制Reducer类的基类,和Mapper类似,它也有setup,reduce,cleanup和run方法,其中setup和
cleanup含义和Mapper相同,reduce是真正合并Mapper结果的地方,它的输入是key和这个key对应的所有value的一个迭代
器,同时还包括Reducer的上下文。系统中定义了两个非常简单的Reducer,IntSumReducer和LongSumReducer,分别用于
对整形/长整型的value求和。
Reduce的结果,通过Reducer.Context的方法collect输出到文件中,和输入类似,Hadoop引入了OutputFormat。
OutputFormat依赖两个辅助接口:RecordWriter和OutputCommitter,来处理输出。RecordWriter提供了write方法,用于输出
<key, value>和close方法,用于关闭对应的输出。OutputCommitter提供了一系列方法,用户通过实现这些方法,可以定制
OutputFormat生存期某些阶段需要的特殊操作。我们在TaskInputOutputContext中讨论过这些方法(明
显,TaskInputOutputContext是OutputFormat和Reducer间的桥梁)。
OutputFormat和RecordWriter分别对应着InputFormat和RecordReader,系统提供了空输出NullOutputFormat(什么结果都不
输出,NullOutputFormat.RecordWriter只是示例,系统中没有定义),LazyOutputFormat(没在类图中出现,不分
析),FilterOutputFormat(不分析)和基于文件FileOutputFormat的SequenceFileOutputFormat和TextOutputFormat输出。
基于文件的输出FileOutputFormat利用了一些配置项配合工作,包括mapred.output.compress:是否压缩
mapred.output.compression.codec:压缩方法;mapred.output.dir:输出路径;mapred.work.output.dir:输出工作路径。
FileOutputFormat还依赖于FileOutputCommitter,通过FileOutputCommitter提供一些和Job,Task相关的临时文件管理功能。
如FileOutputCommitter的setupJob,会在输出路径下创建一个名为_temporary的临时目录,cleanupJob则会删除这个目录。
SequenceFileOutputFormat输出和TextOutputFormat输出分别对应输入的SequenceFileInputFormat和TextInputFormat,我
们就不再详细分析啦。
Mapper的输出,在发送到Reducer前是存放在本地文件系统的,IFile提供了对Mapper输出的管理。我们已经知道,Mapper的
输出是<Key,Value>对,IFile以记录<key-len, value-len, key,value>的形式存放了这些数据。为了保存键值对的边界,很自
然IFile需要保存key-len和value-len。
和IFile相关的类图如下:
下载后可阅读完整内容,剩余8页未读,立即下载
2021-03-01 上传
点击了解资源详情
2024-01-08 上传
2024-11-12 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-27 上传
2024-11-27 上传

weixin_38673924
- 粉丝: 4
- 资源: 906
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
