"尚硅谷大数据技术之 Spark第二章运行模式及基础解析"
需积分: 0 4 浏览量
更新于2024-01-15
收藏 4.09MB PDF 举报
尚硅谷大数据技术之Spark是一个基于内存的快速、通用、可扩展的大数据分析引擎。它诞生于2009年,在加州大学伯克利分校AMPLab开始编写,并于2010年开源,成为Apache的孵化项目。2013年6月,它成为Apache的顶级项目。
Spark内置了多个模块,每个模块都有不同的功能。首先是Spark SQL,它用于处理结构化数据,使得用户可以使用SQL查询来操作数据。Spark Streaming是一个用于实时计算的模块,可以处理实时流数据,这对于需要即时响应的应用程序非常重要。Spark Mlib是机器学习模块,提供了各种机器学习算法,可以帮助用户进行数据分析和预测。Spark GraphX是一个用于图计算的模块,可以用于处理大规模的图数据。最后,Spark Core是一个独立的调度器,可以与其他资源管理器(如YARN和Mesos)集成,提供分布式计算的功能。
Spark的优点在于它的内存计算能力,它将数据存储在内存中,因此可以快速访问和处理数据,大大提升了计算的速度。此外,Spark还提供了丰富的API,支持多种编程语言(如Java、Python和Scala),使得用户可以根据自己的需求选择最合适的编程语言进行开发。Spark还支持交互式数据查询和分析,用户可以使用交互式的Shell界面来执行查询,并获得即时的结果。
Spark具有良好的扩展性,它可以与其他大数据技术(如Hadoop、Hive和HBase)集成,提供了更强大的功能。它还支持分布式存储系统(如HDFS和S3),可以处理大规模的数据集。
总之,尚硅谷大数据技术之Spark是一种强大的大数据分析引擎,它具有高速、通用、可扩展的特点,能够处理结构化数据、实时计算、机器学习和图计算等多种任务。它的优势在于内存计算、丰富的API支持和良好的扩展性。如果你对大数据分析和处理感兴趣,Spark将是一个很好的选择。更多相关资料可以在尚硅谷官网上找到。

尚硅谷大数据技术之 Spark 基础解析
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
16
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<finalName>WordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2)编写代码
package com.atguigu
import org.apache.spark.{SparkConf, SparkContext}
object WordCount{
def main(args: Array[String]): Unit = {
//1.创建 SparkConf 并设置 App 名称
val conf = new SparkConf().setAppName("WC")
//2.创建 SparkContext,该对象是提交 Spark App 的入口
val sc = new SparkContext(conf)
//3.使用 sc 创建 RDD 并执行相应的 transformation 和 action
sc.textFile(args(0)).flatMap(_.split(" ")).map((_,
1)).reduceByKey(_+_, 1).sortBy(_._2, false).saveAsTextFile(args(1))
//4.关闭连接
sc.stop()
}
}
3)打包插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>WordCount</mainClass>
</manifest>
</archive>

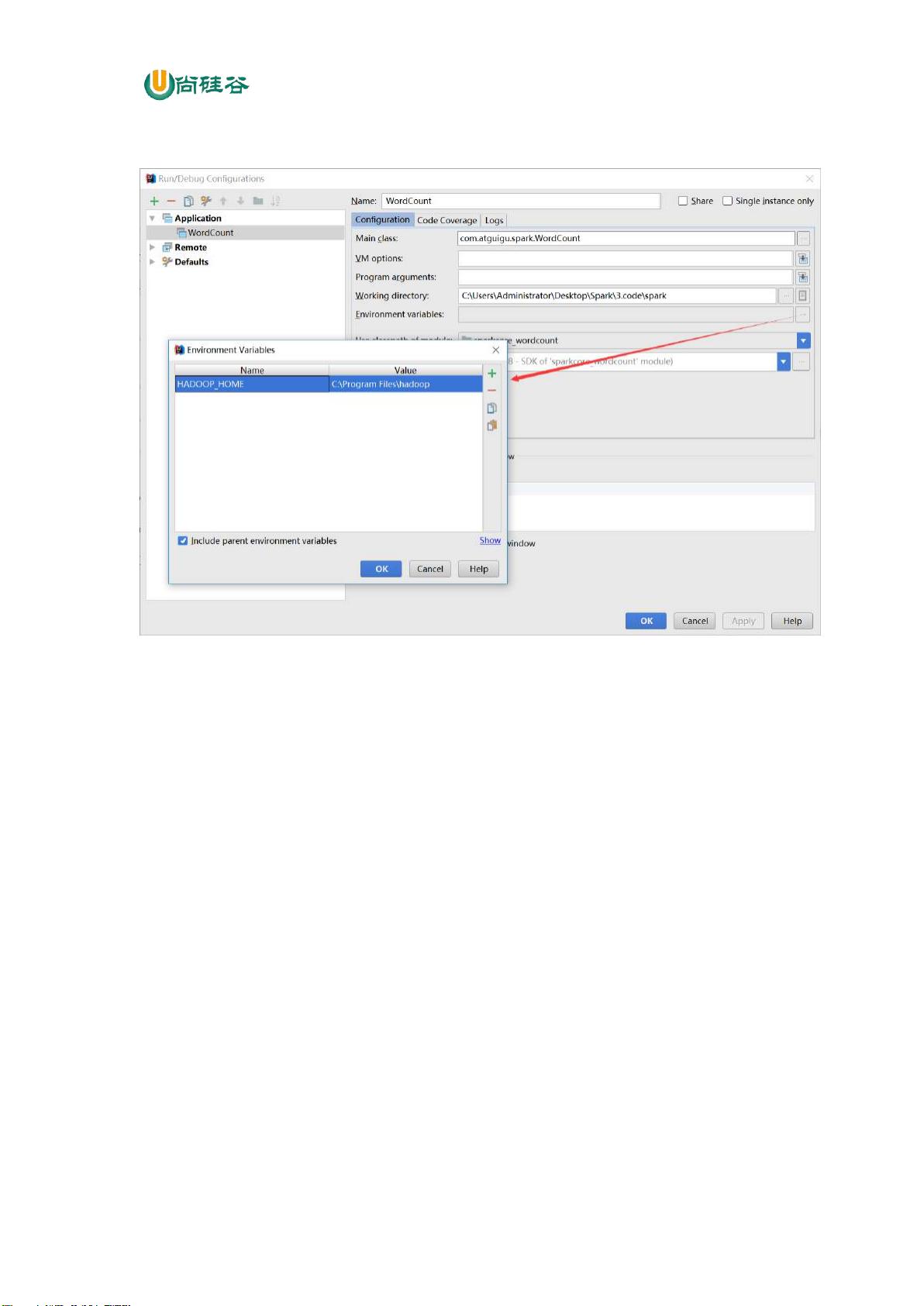


剩余181页未读,继续阅读
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2023-06-06 上传
2023-03-15 上传
点击了解资源详情

城北伯庸
- 粉丝: 34
- 资源: 315
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
