SPSS中的聚类分析:从K-Means到系统聚类法
需积分: 15 60 浏览量
更新于2024-07-31
收藏 1016KB PPT 举报
"该资源是一份关于如何在SPSS中执行聚类分析的PPT,主要介绍了快速聚类和系统聚类两种方法,特别强调了系统聚类的详细步骤和参数选择,包括数据标准化、测度方法、聚类方法、以及不同的距离和相似系数。"
在数据分析领域,聚类分析是一种无监督学习方法,用于将数据集中的对象或样本根据它们的特征或属性分组成相似的类别。本资源主要关注聚类分析在统计软件SPSS中的实现,这对理解和应用聚类分析具有很高的实用价值。
1. **快速聚类 (K-Means Cluster)**
快速聚类是一种基于迭代的算法,目标是找到K个中心,使得所有数据点到其最近的中心的距离平方和最小。K值需预先设定,算法会自动分配每个数据点到最近的聚类中心。
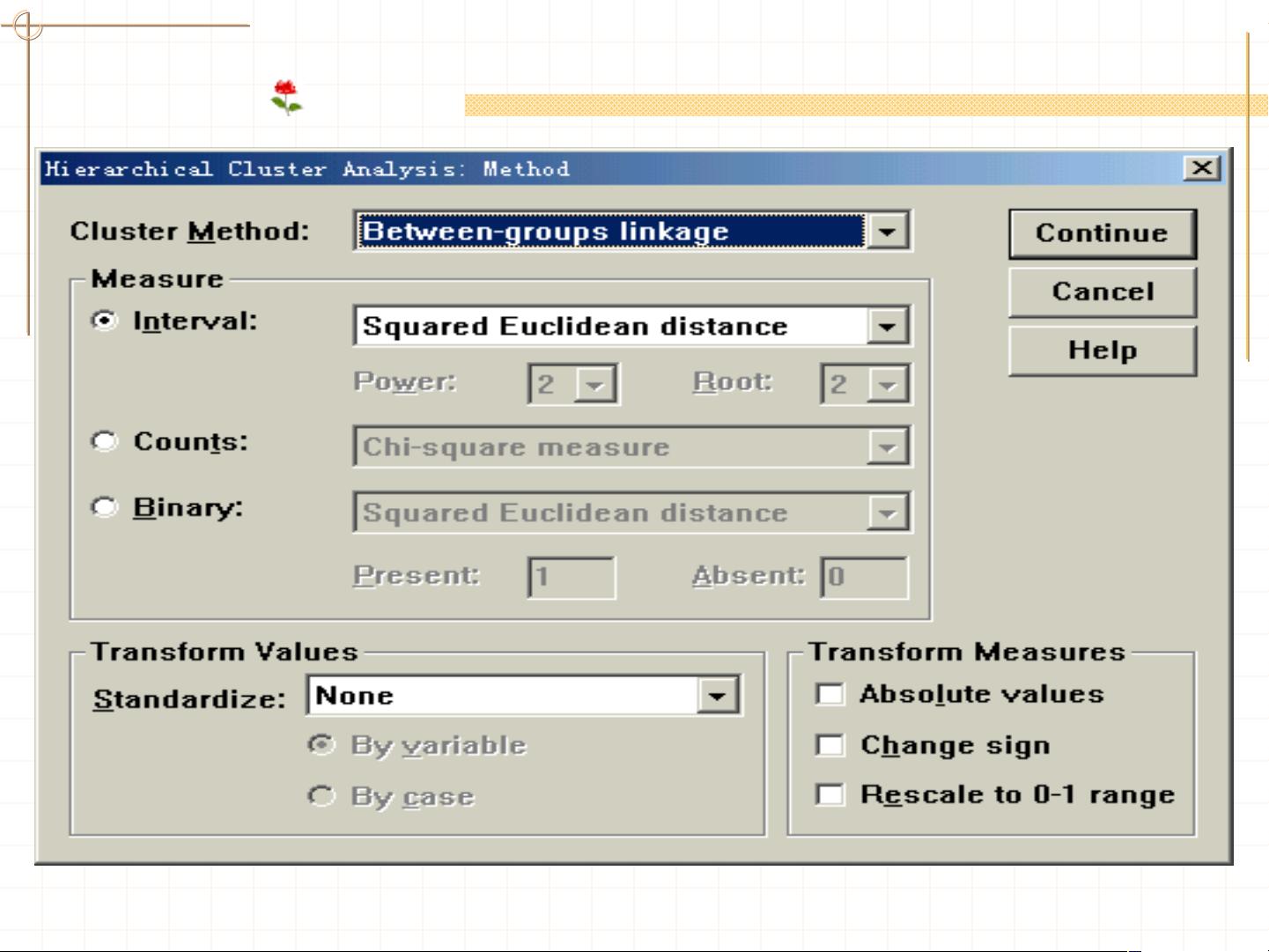
2. **系统聚类 (Hierarchical Cluster)**
系统聚类则分为分解法和凝聚法,可以对样品或变量进行聚类。在SPSS中,系统聚类提供了7种不同的方法,包括:
- **Between-groups linkage**:类间平均法,计算两个类别的总体距离。
- **Within-groups linkage**:类内平均法,计算合并后类别的内部距离。
- **Nearest neighbor**:最短距离法,选择最近的类进行合并。
- **Furthest neighbor**:最长距离法,选择最远的类进行合并。
- **Centroid clustering**:重心法,基于类别的质心计算距离。
- **Median clustering**:中间距离法,基于类别的中位数计算距离。
- **Ward Method**:离差平方和法,减少合并后的总体离差平方和。
3. **数据标准化与测度方法**
在聚类分析前,数据通常需要进行标准化处理,确保所有变量在同一尺度上。测度方法涉及选择合适的距离或相似性度量,例如:
- **平方欧式距离**和**欧式距离**:计算两向量之间的直线距离。
- **夹角余弦**:用于衡量两个非零向量的相似度,值在-1到1之间。
- **皮尔逊相关系数**:度量两个变量线性相关的程度,范围是-1到1。
- **切比雪夫距离**:最大绝对差之和。
- **绝对值距离**和**明考斯基距离**:更一般的距离度量形式,可以根据具体情况调整。
- **自定义距离**:用户可根据需求定义特定的相似度或距离函数。
这份资源通过实例详细介绍了如何在SPSS中进行这些操作,并提供了城镇居民消费支出资料等案例,帮助读者更好地理解和应用聚类分析。无论是初学者还是有经验的数据分析师,都能从中受益。
Method
Method
聚类方法
标准化变换
亲疏关系指标
剩余38页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-10 上传
2013-05-02 上传
2021-10-10 上传
2021-10-10 上传
2009-08-17 上传
2023-09-04 上传

yansuxiaoqing
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chausie提供了可自定义的视图容器,用于管理内容页面之间的导航。 :猫:-Swift开发
- DianMing.rar_android开发_Java_
- Mockito-with-Junit:与Junit嘲笑
- recycler:[只读] TYPO3核心扩展“回收者”的子树拆分
- 分析:是交互式连续Python探查器
- emeth-it.github.io:我们的网站
- talaria:TalariaDB是适用于Presto的分布式,高可用性和低延迟时间序列数据库
- lexi-compiler.io:一种多语言,多目标的模块化研究编译器,旨在通过一流的插件支持轻松进行修改
- 实时WebSocket服务器-Swift开发
- EMIStream_Sales_demo.zip_技术管理_Others_
- weiboSpider:新浪微博爬虫,用python爬取新浪微博数据
- Vue-NeteaseCloud-WebMusicApp:Vue高仿网易云音乐,基本实现网易云所有音乐,MV相关功能,转变更新到第二版,仅用于学习,下面有详细教程
- asciimatics:一个跨平台的程序包,可进行类似curses的操作,外加更高级别的API和小部件,可创建文本UI和ASCII艺术动画
- Project_4_Java_1
- csv合并js
- containerd-zfs-snapshotter:使用本机ZFS绑定的ZFS容器快照程序
