Java实现哈夫曼编码与译码技术探索
需积分: 20 27 浏览量
更新于2024-07-19
3
收藏 1.43MB DOCX 举报
"Java哈夫曼编码译码器是一个实现数据压缩和解压缩的程序,主要基于哈夫曼编码理论。该程序允许用户对文件进行哈夫曼编码,以减小文件大小,同时提供译码功能,能将编码后的文件恢复成原始内容。"
哈夫曼编码是一种高效的无损数据压缩方法,它依赖于哈夫曼树,这是一种特殊的二叉树结构。哈夫曼树的构建是基于字符出现的频率,频率高的字符对应较短的编码,而频率低的字符则对应较长的编码。这种编码方式可以使得编码后的数据平均长度降低,从而达到压缩效果。
在哈夫曼编码的过程中,首先需要读取文件内容并统计每个字符出现的频率。然后,通过这些频率构建哈夫曼树。构建哈夫曼树的方法是使用优先队列(通常用堆实现)来合并频率最低的两个节点,直到只剩下一个节点,即为哈夫曼树的根节点。每个叶子节点代表一个字符,而内部节点不存储任何信息。
编码阶段,从根节点出发,沿着路径走到叶子节点,路径上左分支代表0,右分支代表1,这样就得到了每个字符的哈夫曼编码。编码后的文本通常会更短,从而节省存储空间。
译码阶段,接收到的是按照哈夫曼编码规则编码的二进制序列。通过哈夫曼树,可以反向解析这个二进制序列,恢复出原始的字符序列。译码过程是从二进制序列开始,根据0和1的路径遍历哈夫曼树,到达叶子节点时,记录对应的字符,然后返回根节点,继续解析剩余的二进制序列。
此Java实现的哈夫曼编码译码器还包含了一些附加功能,如图形用户界面,支持文件的打开和保存,以及对整个文件的加密和解密操作。在设计时,程序可能包括以下部分:
1. 数据结构:使用优先队列(堆)来构建哈夫曼树,以及哈夫曼树的节点结构。
2. 关键问题解决:如何有效地构建和遍历哈夫曼树,以及如何处理编码和译码过程中的边界条件。
3. 系统开发环境:指定编程语言(Java)、开发工具和可能的运行平台。
4. 程序流程:包括读取文件、统计频率、构建哈夫曼树、编码和译码的步骤。
5. 主要源代码:实现上述功能的具体Java代码。
6. 运行结果:展示编码和译码后的效果,以及哈夫曼树的可视化。
7. 结论:对项目实现的总结和可能的改进方向。
参考文献可能包括关于哈夫曼编码的理论资料和技术实现的相关论文或教程。通过这样的哈夫曼编码译码器,用户可以体验到数据压缩的便利,同时理解哈夫曼编码的原理及其在实际问题中的应用。
沈阳理工大学课程设计专用纸 No3
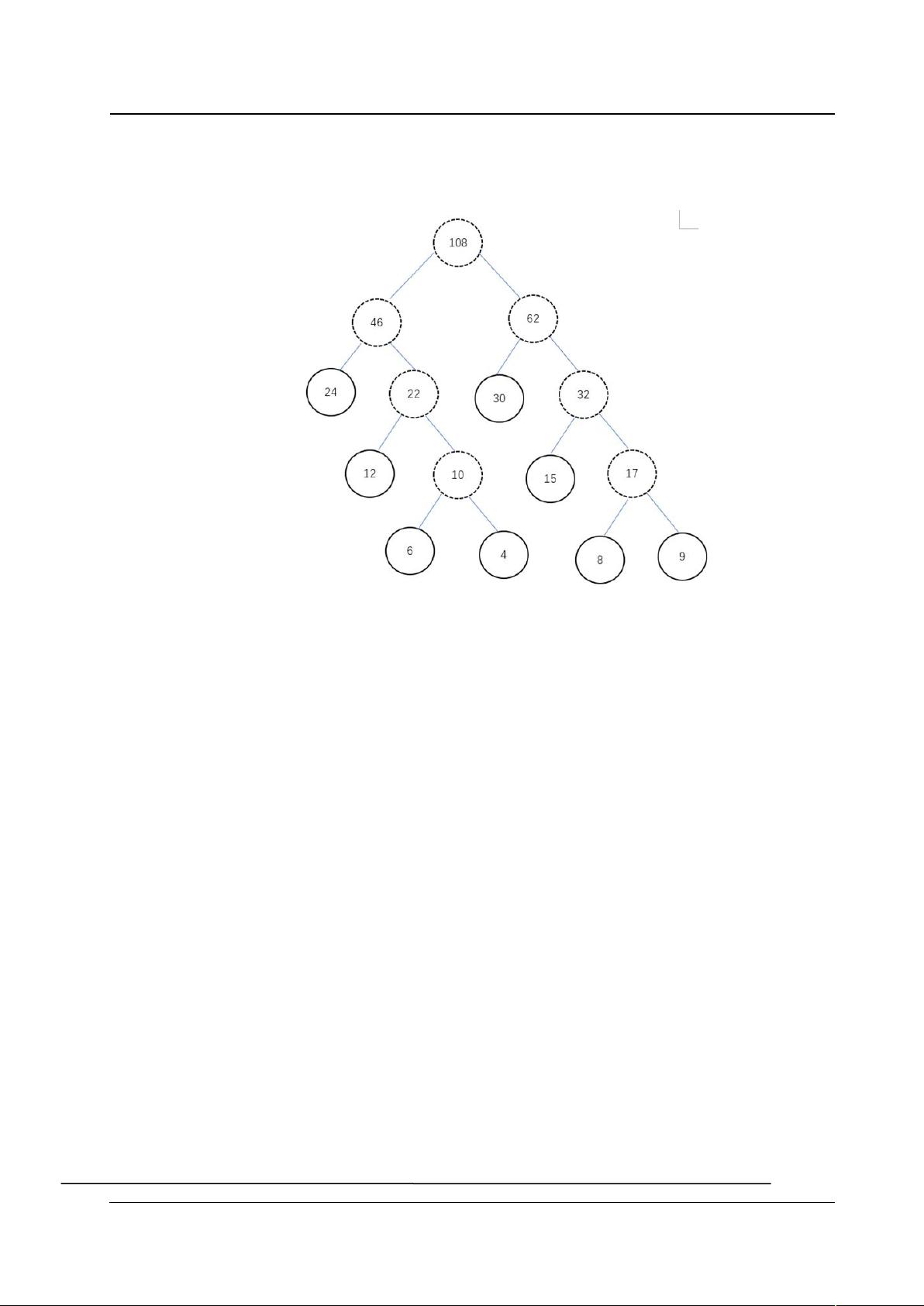
根据上述过程可以知道该编码译码器的关键在于字符统计和哈弗曼树的创建以及编码
解码,分步说明如下:
哈弗曼树理论创建过程如下:
以字符统计的频率为权值构建哈弗曼树,现在假设 n 个权值分别为{w1,w2,…,wn},
则
1)由已知给定的 n 个权值{w1,w2,…,wn},构造一个由 n 个二叉树所构成的森林
F={T1,T2,…,Tn}, 其 中每一棵二 叉 树只有一个根 节 点 ,并且根 节 点 的权 值分别为
w1,w2,…,wn。
2)在二叉树森林 F 中选取根节点的权值最小和次小的两棵二叉树,分别把他们作为
左子树和右子树去构造一棵新二叉树,新二叉树的根节点权值为其左右子树根节点的权
值之和。
3)作为新二叉树的左右字树的两棵二叉树从森林 F 中删除,将新产生的二叉树加入
到森林 F 中。
沈阳理工大学

剩余30页未读,继续阅读
2017-12-29 上传
2022-06-09 上传
2023-05-28 上传
2023-05-18 上传
2023-05-19 上传
2023-10-29 上传
2024-06-16 上传
2024-06-24 上传
2024-01-03 上传

王洪义
- 粉丝: 34
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
