Apache Beam架构详解:统一处理模型与实战应用
版权申诉
Apache Beam是一种开源的统一数据处理框架,由Google开发并维护,旨在提供一种模块化的方法来编写在批处理和流数据处理之间无缝切换的代码。它旨在解决传统数据处理框架在批处理与实时流处理之间的界限,并为开发者提供了一种通用的编程模型,以便于构建高度可扩展、可移植和灵活的数据处理应用。
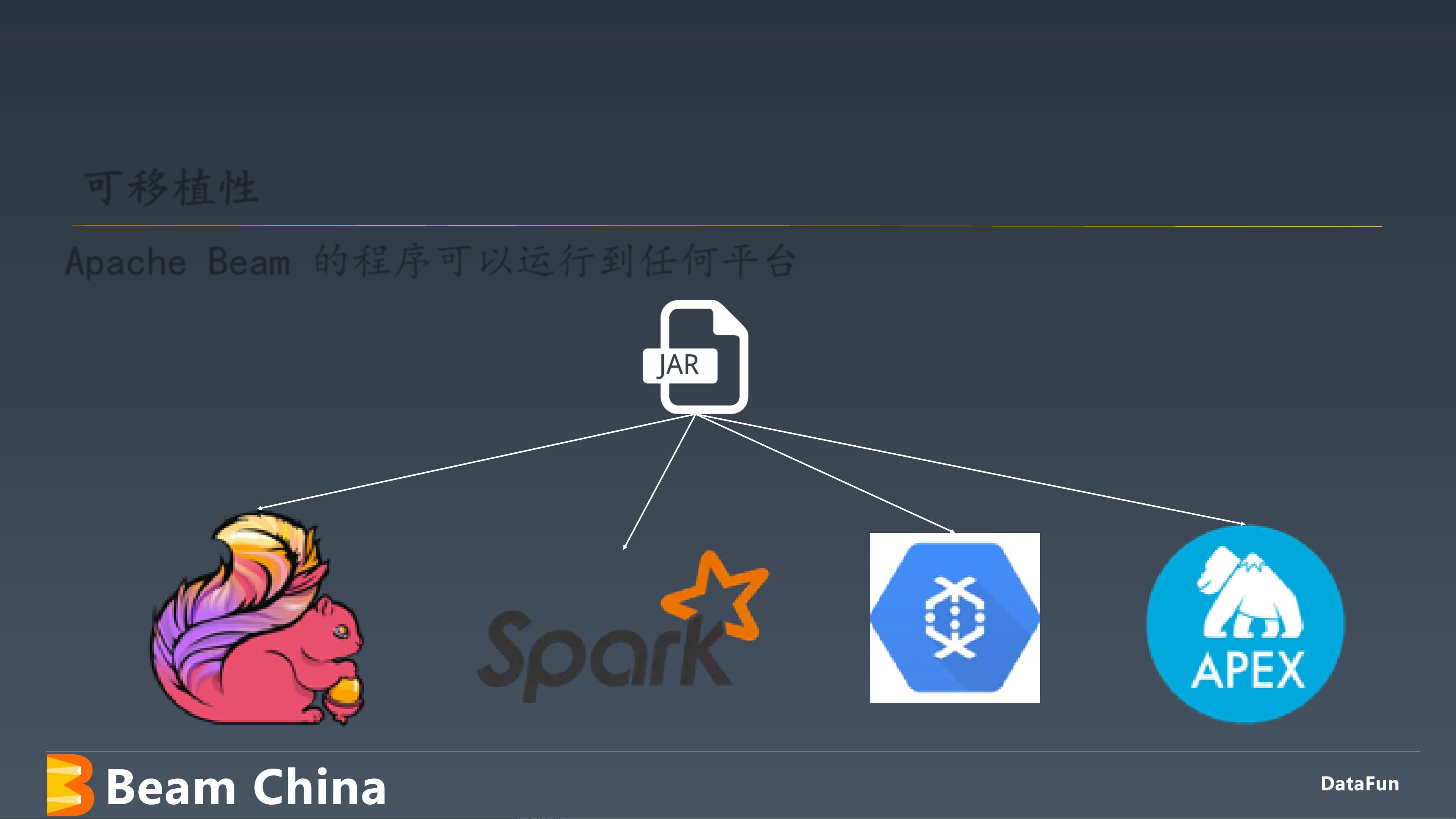
首先,Apache Beam的核心在于它的设计理念,即“一次编写,到处运行”(Write Once, Run Anywhere)。这意味着使用Apache Beam编写的处理逻辑可以在多个后端平台上运行,包括Apache Apex、Apache Flink、Apache Spark和Google Cloud Dataflow等。这使得开发者能够选择最适合他们场景的计算引擎,而无需为不同的处理模式单独编写代码。
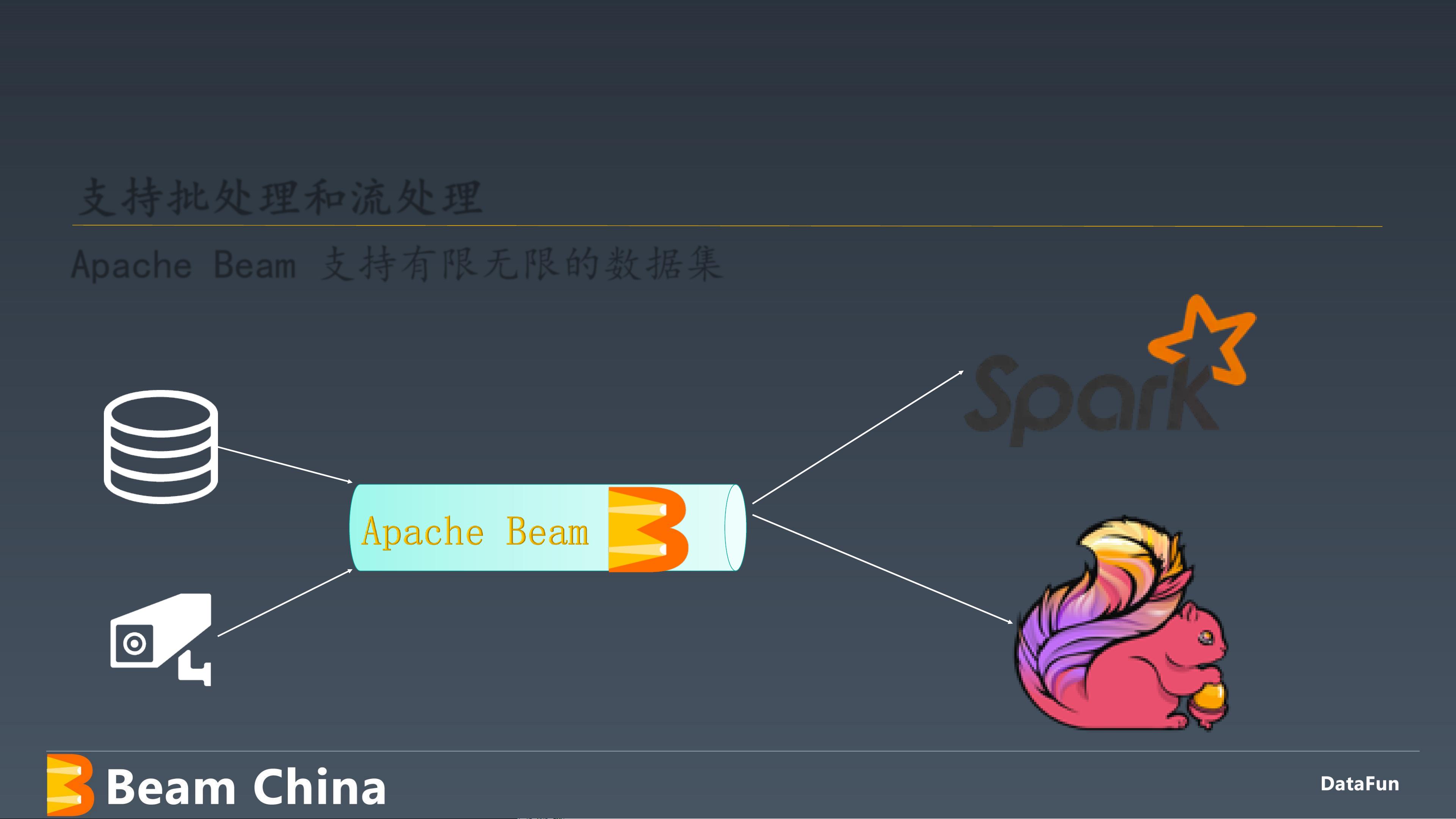
在架构设计上,Apache Beam采用了数据流模型,将数据处理视为一系列连续的处理阶段,每个阶段都由数据元素(称为“元素”或“PCollections”)通过一系列处理函数(如映射、过滤、组合)进行转换。这种设计使得处理逻辑易于理解和维护,同时也允许高效地进行并行和分布式执行。
核心组件包括以下几个方面:
1. SDKs (Software Development Kits):Apache Beam提供多种语言的SDK,如Java、Python、Go和Scala等,使得开发者可以根据自己的喜好和项目需求选择最合适的编程语言进行开发。
2. Pipeline API:这是一种统一的编程接口,开发者可以使用它来构建处理管道,定义数据的输入、处理步骤和输出。无论是在批处理还是流处理模式下,这种API保持一致,简化了代码的编写。
3. Transformations:这些是处理函数,如map、filter、groupByKey等,它们构成了数据处理流程的核心部分。开发者可以组合这些函数以构建复杂的处理逻辑。
4. I/O支持:为了实现数据的输入和输出,Apache Beam提供了广泛的数据源支持,包括文件系统、数据库、消息队列等,保证了对各种数据源的统一处理。
5. 分布式执行:由于其可移植性和可扩展性,Apache Beam能够利用底层平台的分布式计算能力,自动管理数据并行和任务调度,使得大规模数据处理变得更加高效。
在实际应用中,特别是在构建实时数据处理的AI微服务时,Apache Beam可以帮助企业构建实时分析和预测模型,快速响应业务变化。例如,通过Google Cloud Dataflow结合Apache Beam,可以实现实时数据流处理,驱动实时决策支持系统(Real-time Decision Support Systems)。
Apache Beam作为现代数据处理的重要工具,通过其统一的编程模型、强大的分布式执行能力和跨平台兼容性,为开发者提供了高效、灵活的数据处理解决方案,适用于各种规模的企业级应用场景。

2020-02-14 上传
2022-03-04 上传
2022-03-18 上传
2017-11-22 上传
2023-05-15 上传
2021-05-13 上传
367 浏览量

普通网友
- 粉丝: 12w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
