Python模拟登录豆瓣爬取《寄生虫》影评分析
165 浏览量
更新于2024-08-29
3
收藏 847KB PDF 举报
"这篇教程主要介绍了如何使用Python模拟登录豆瓣并爬取电影《寄生虫》的影评,以便进行数据分析和制作词云。作者在分析了豆瓣登录页面的网络请求后,通过requests库实现了模拟登录,并利用其他库如jieba进行分词,matplotlib和wordcloud制作词云。整个过程分为模拟登录、爬取影评、批量获取数据、生成词云等步骤。"
在Python中,模拟登录网站是爬虫技术中常见的一种方法,目的是为了获取登录后的权限,访问需要登录才能看到的数据。在这个例子中,作者通过requests库的Session对象来处理登录过程中的Cookie信息,确保后续的请求能够带有登录状态。在登录过程中,通常需要分析网页的HTTP请求,找出登录所需的POST参数,包括用户名、密码以及其他可能的验证信息。
`jieba`库是一个强大的中文分词工具,它可以帮助我们对爬取的影评内容进行词频分析,为制作词云做准备。在词云的制作中,使用了`matplotlib`和`wordcloud`库。`matplotlib`是一个强大的Python绘图库,可以用来创建各种图形,包括词云的背景;而`wordcloud`库则是专门用于生成词云的,它可以接受分词结果并生成具有视觉效果的词云图。
在爬取数据时,作者可能采用了递归或循环的方式,逐页获取影评内容,这样可以获取更多的评论数据,而不是仅限于未登录时的10页短评。爬取到的评论数据会被保存到文本文件中,以便后续分析。
在制作词云时,有两步值得注意:一是生成普通词云,二是制作具有特定形状(如电影海报形状)的词云。后者需要一个图像文件作为背景,并使用`ImageColorGenerator`从背景图像中提取颜色,使词云与背景融合,增加视觉效果。
整个过程涉及到了网络请求、HTML解析、数据存储、文本处理和可视化等多个环节,展示了Python在数据爬取和分析领域的强大功能。对于想学习网络爬虫和数据分析的初学者来说,这是一个很好的实战案例,涵盖了多个关键知识点。
运用运用python模拟登录豆瓣爬取并分析某部电影的影评分析模拟登录豆瓣爬取并分析某部电影的影评分析
前段时间奉俊昊的《寄生虫》在奥斯卡上获得不少奖项,我也比较喜欢看电影,看过这部电影后比较好奇其他人对这部电影的看法,于是先用R爬取了部分豆瓣影评,jieba分词后做
了词云了解,但是如果不登录豆瓣直接爬取影评只可以获得十页短评,这个数据量我认为有点少,于是整理了python模拟登录豆瓣,批量爬取数据,制作特别样式词云的方法。
一、一、 用到的用到的Python库库
import os ##提供访问操作系统服务的功能
import re ##正则表达式
import time ##处理时间的标准库
import random ##使用随机数标准库
import requests ##实现登录
import numpy as np ##科学计算库,是一个强大的N维数组对象ndarray
import jieba ##jieba分词库
from PIL import Image ##python image library 库,python3多用pillow库
import matplotlib.pyplot as plt ##绘图
plt.switch_backend('tkagg')
from wordcloud import WordCloud, ImageColorGenerator##词云制作
关于每个库的运用要熟悉挺久,我也只是入门级
二、思路二、思路
1. 模拟登录豆瓣模拟登录豆瓣
2. 爬取一页影评爬取一页影评
3. 批量爬取影评批量爬取影评
4. 制作普通词云制作普通词云
5. 制作图片形状背景的词云制作图片形状背景的词云
三、代码实现三、代码实现
1. 模拟登录豆瓣模拟登录豆瓣
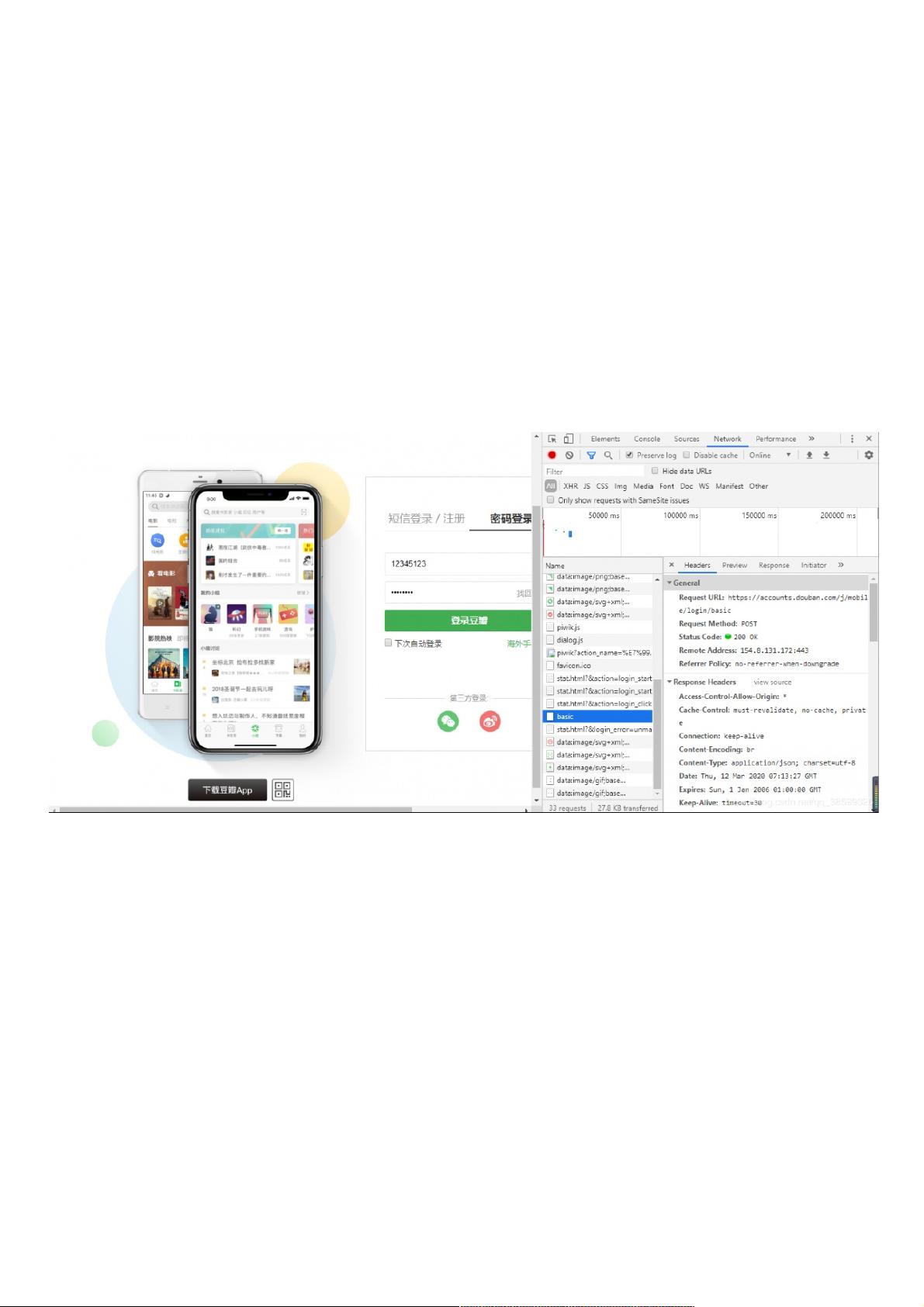
首先需要分析豆瓣的登录页面
点击鼠标右键进入“检查”,在登录窗口里输入错误的登录信息,进入Network下名为basic中,这里有许多有用的信息,如
Request URL,User-Agent,Accept-Encoding,等等
还需要看看请求登录时携带的参数,将调试窗口往下拉查看Form Data。
下载后可阅读完整内容,剩余4页未读,立即下载
2020-04-01 上传
2024-01-08 上传
2024-04-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38622962
- 粉丝: 3
- 资源: 903
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
