深度学习驱动的图像超分辨率重建:特征融合与注意力机制
版权申诉
105 浏览量
更新于2024-06-27
1
收藏 1.51MB DOCX 举报
本文主要探讨了基于特征融合注意网络的图像超分辨率重建技术,特别是针对单图像超分辨率(Single Image Super-Resolution, SISR)的研究。近年来,SISR技术因其在医学成像、遥感卫星成像和视频监控等多个领域的应用而备受关注。超分辨率技术主要包括基于插值、基于重建和基于学习的三大类方法。基于学习的方法,尤其是深度学习,已经成为当前的研究重点。
2014年,Dong等人提出的SRCNN(Super-Resolution Convolutional Neural Network)开创了利用深度学习进行SISR的先河,该模型直接学习LR和HR图像间的映射关系。随后,FSRCNN(Fast Super-Resolution Convolutional Neural Network)进一步优化了网络结构,提高了运算速度。VDSR(Very Deep Super-Resolution)通过引入ResNet的残差学习,使得网络能更深入,从而提升超分辨率效果。DRRN(Deep Recursive Residual Network)利用深度递归残差结构,减少了参数量,增强了性能。LapSRN(Laplacian Super-Resolution Network)借鉴了拉普拉斯金字塔,通过多级上采样和残差预测实现不同尺度的超分辨率任务。
这些方法揭示了网络深度对于图像重建质量的关键作用,但深度增加也会带来内存和计算需求的增长。文章指出,单纯增加卷积层可能导致效率下降。因此,提出了一种基于特征融合注意网络的新方法,该方法可能更加注重在提高网络性能的同时,有效地管理和利用资源,以达到更好的超分辨率重建效果,同时减轻对计算资源的需求。
这种方法的核心思想可能是利用注意力机制来动态融合不同层次的特征,使网络能够更好地捕获图像的细节信息,提高重建图像的质量,同时避免深度增加带来的问题。通过特征融合和注意力机制,网络可以在不显著增加计算负担的情况下,增强对关键信息的捕捉,从而实现高效且高质量的图像超分辨率重建。这为未来超分辨率技术的发展提供了新的研究方向和优化思路。
下载: 全尺寸图片 幻灯片
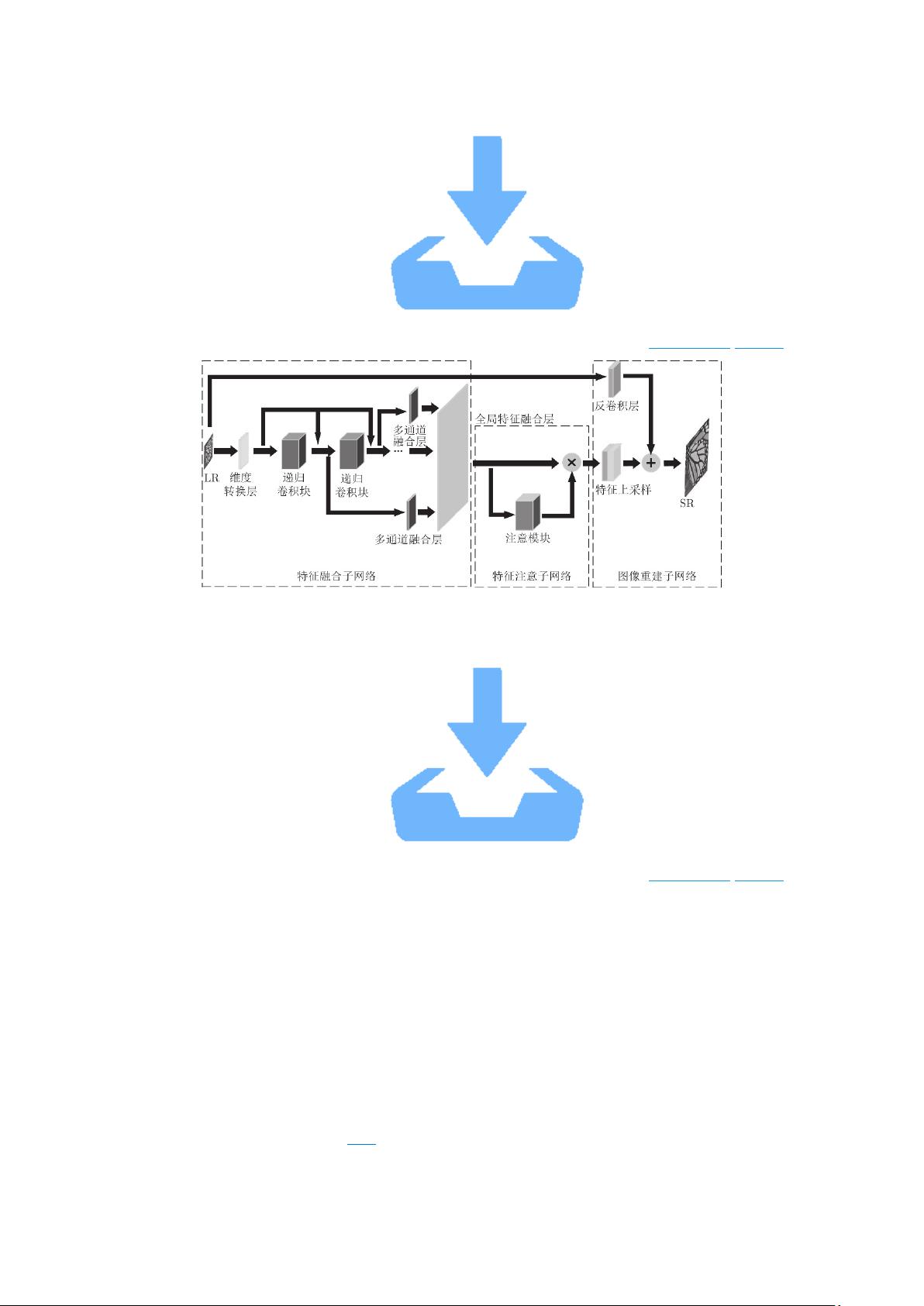
图 2 超分辨率子网络内部结构
Fig. 2 Internal structure of super-resolution subnetwork
下载: 全尺寸图片 幻灯片
1.1 特征融合子网络
本文的特征融合子网络由维度转换层、递归卷积块、多通道融合层, 以及全局特征融
合层 4 个部分组成. 维度转换层为一个 3×3 的卷积层, 将输入的 LR 图像转换到高维特征,
并过滤掉一部分低频信息
H0=F0(ILR,W0)H0=F0(ILR,W0)
(1)
其中, ILRILR 是输入的 LR 图像, F0F0 是维度转换层的映射函数, W0W0 是 F0F0 的权
重矩阵参数, H0H0 是 F0F0 的输出特征. H0H0 输入到 8 个顺序连接的递归卷积块, 每个卷
积块包含 5 个的卷积层, 参见图 3. 递归卷积块对 H0H0 进一步进行特征提取
Hi=Fi(Hi−1,Wi)+H0,i=1,2,⋯,8Hi=Fi(Hi−1,Wi)+H0,i=1,2,⋯,8
(2)
剩余14页未读,继续阅读
2022-06-10 上传
2021-09-20 上传
2022-12-01 上传
2022-11-28 上传
2023-02-23 上传
2022-12-15 上传

罗伯特之技术屋
- 粉丝: 4427
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
