2018年高级逻辑综合:大数据与人工智能驱动的创新
下载需积分: 9 | PDF格式 | 6.76MB |
更新于2024-07-18
| 104 浏览量 | 举报
《高级逻辑综合2018》是一本由André Inácio Reis和Rolf Drechsler合编的专业书籍,关注于逻辑综合领域的最新发展。逻辑合成作为一项关键的计算机科学技术,随着大数据时代和人工智能的崛起,正朝着更深层次的研究方向迈进。书中特别强调了利用数据中心的强大计算能力,这使得处理大规模数据和应用认知功能成为可能。
在2018年的这一版本中,作者探讨了如何将人工智能的最新进展,如深度学习和图形数据结构的并行处理技术,融入逻辑综合的设计流程中。这不仅包括了算法的优化,还涵盖了硬件与软件的协同工作,以及在云计算环境下的系统设计,如cyber-physical systems(CPS)的构建。
书中详细介绍了逻辑综合的高级方法论和技术,如基于门级设计、高阶综合、静态时序分析以及针对复杂电路的优化策略。编辑们可能还讨论了如何通过集成自动化工具和人工智能技术来简化设计过程,提升效率,减少设计时间和成本。
此外,本书可能会包含关于硬件描述语言(HDL)的最新进展,以及如何将它们与机器学习算法相结合,以实现自适应和自优化的设计。对于那些对逻辑设计感兴趣的工程师、研究人员和研究生来说,这本著作提供了一个深入了解当前前沿技术和未来趋势的平台。
值得注意的是,版权方面,《高级逻辑综合2018》受到Springer International Publishing AG的保护,所有权利均保留,未经许可,不得进行任何形式的复制、转印、广播或电子传播,除非符合版权法的例外规定。对于想要在逻辑综合领域深化研究或教学的人来说,查阅此书需确保遵守版权条款。读者可以通过ISBN 978-3-319-67294-6(纸质版)或978-3-319-67295-3(电子版)获取,或者访问DOI: <https://doi.org/10.1007/978-3-319-67295-3> 获取在线资源。
《高级逻辑综合2018》是一本不容错过的资料,它反映了逻辑综合领域在2018年的重要突破,以及人工智能和云计算如何推动这一领域向更高效、智能的方向发展。
1 EDA3.0: Implications to Logic Synthesis 7
0
2
4
6
8
10
12
14
16
18
20
Tb
1
22nm Micro
Scratch
User
Analysis
Phys Design
Verification
Logic
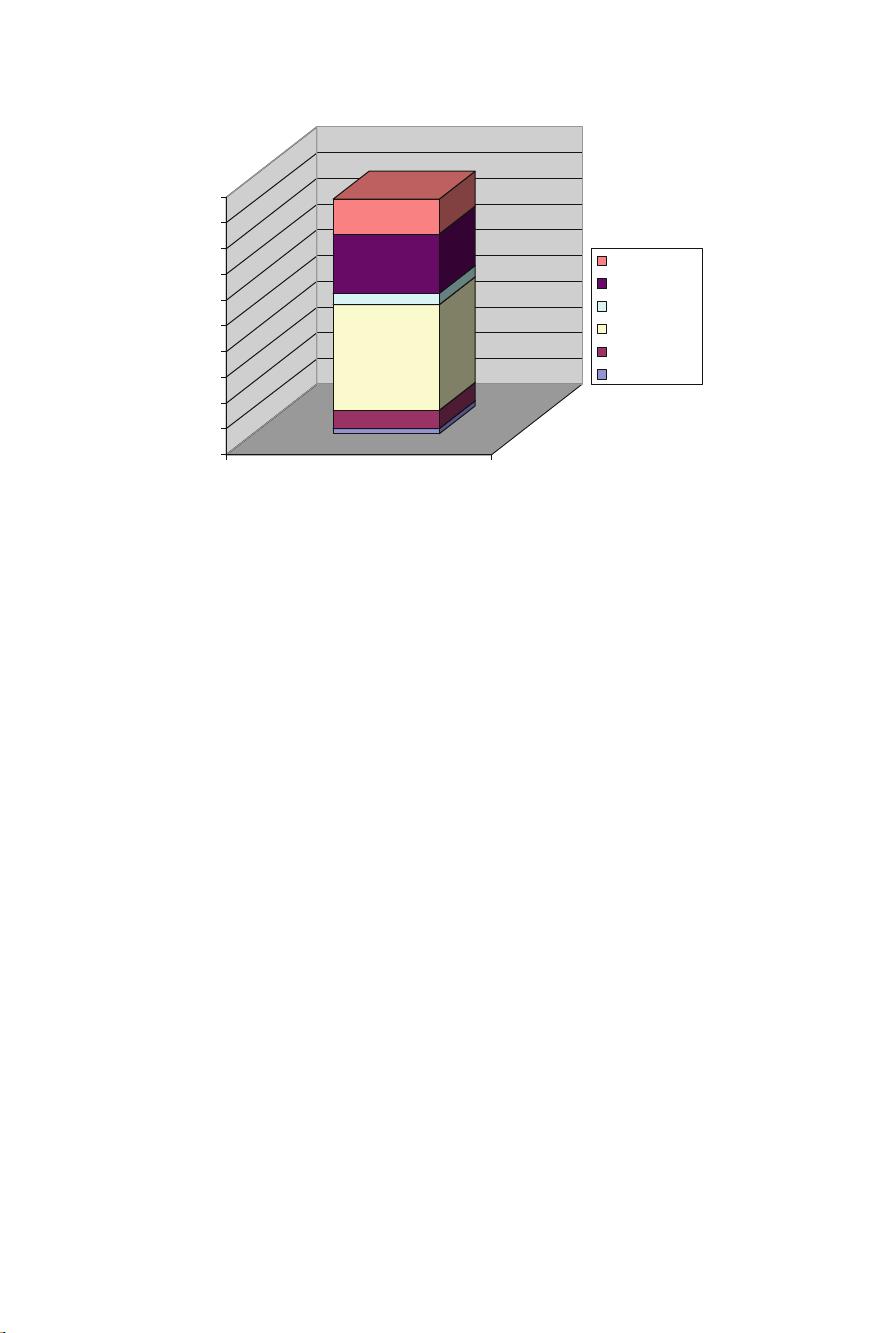
Fig. 1.2 Design data for a 10 C B transistor 22 nm chip
It is not uncommon for design teams to write 1–2 millions of lines of Skill
or Python scripts to create library cells and IP blocks. A complete design and
verification flow can quickly add up to 1–2 million lines of TCL to control the
tools and deal with the setup and environment in which IP and models are stored.
And once the design flow is up and running, a large number of Python and Perl
scripts are written to extract the key information from the terabytes of reports and
design data. It is often difficult to know how many of these scripts exist in a design
environment since they are often owned by individual designers. In addition to all
the configuration and control files a large amount of data gets generated and stored.
Let us look at the amount of data produced by a design team designing a 10BC
transistor processor in 22 nm technology as shown in Fig. 1.2. It takes about 12 Tb to
store the entire golden data (including incremental revisions). Logic and verification
setup takes about 2 Tb, the physical design data about 8–9 Tb and another 1–2 Tb
for analysis reports. In addition, individual users keep another 6 Tb of local copies in
user and scratch spaces. For functional verification, approximate 1.5 Tb of coverage
data is collected daily. This data is very transient and about 2 weeks worth of data
(21 Tb) is kept in a typical verification process.
After the design is finished, the physical data get compressed and streamed out
to about 3Gb of OASIS. The product engineering team blows this up to around 1 Tb
during mask preparation operations. Finally, another 5 Tb of test and diagnostics
data gets generated in the post-silicon process.
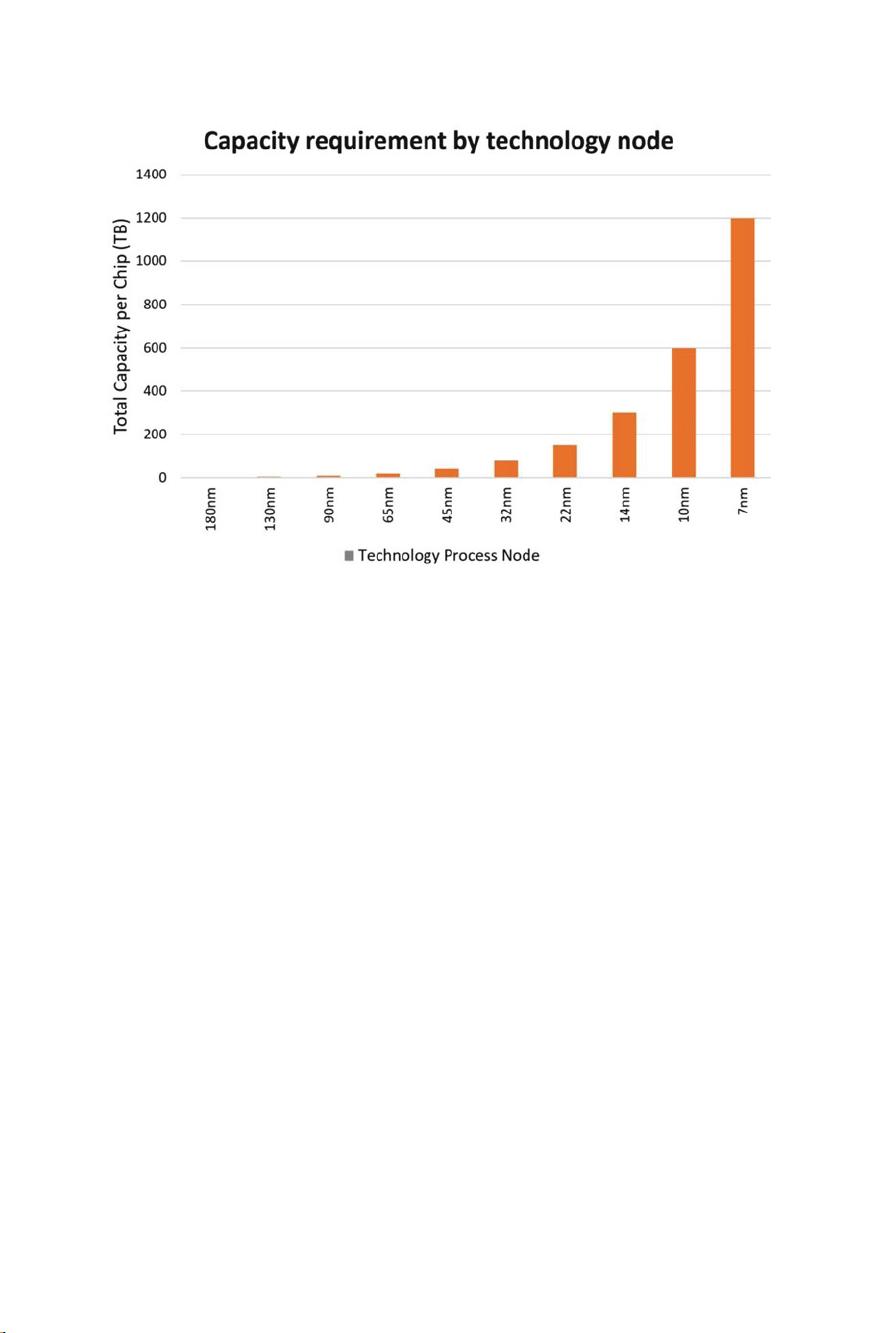
This looks like a significant amount of data but it tops out at 50 Tb for a multi-
year design and manufacturing project. Recently a study [17] was published that
produced the table in Fig. 1.3. It seems to project the 22 nm chip storage needs



剩余235页未读,继续阅读
相关推荐






Pamela_ouyang
- 粉丝: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小型宽带微带天线设计与进展
- QTP 8.0 中文教程:自动化测试与脚本操作详解
- OPC UA基础解析 - 概述与概念RC中文版
- Proteus入门教程:无需实验板的51单片机仿真指南
- Java面试必备:核心知识点详解
- 万方视景科技:虚拟现实内容与项目专家
- Dialogic CTI技术入门到精通:系统工程师指南
- OBJ文件详解:格式、特点与基本结构
- ntop简易安装教程:快速部署流量监控
- Oracle初始化参数深度解析
- WebSphere MQ for z/OS 消息与代码手册
- JFreeChart 1.0.9 开发指南:免费资源与付费版本对比
- 使用Java与WebSphereMQ v6.0交互
- Win32下MinGW与MSYS安装指南
- Linux软件安装指南:从新手到高手
- ADO技术详解:高效数据访问接口
