堆叠集成ELM与PLS加权策略:非线性多元标定新方法
需积分: 14 43 浏览量
更新于2024-07-10
收藏 3.51MB PDF 举报
"堆叠集成极限学习机结合基于偏最小二乘的加权策略进行非线性多元标定"
本文探讨了一种改进的机器学习方法,用于解决化学计量学中的非线性多元校准问题。极限学习机(ELM)作为一种单隐藏层前馈网络,因其简单高效而受到关注。然而,为了提升ELM的泛化能力和鲁棒性,研究人员引入了堆叠泛化技术,从而提出了堆叠集成极限学习机(SE-ELM)。SE-ELM的核心思想是对光谱数据的不同子区域分别应用ELM,生成多个子模型,然后通过特定的加权策略来组合这些子模型的预测结果。
文章中,作者尝试了三种不同的加权策略:赢家通吃(WTA)加权策略、约束非负最小二乘(CNNLS)加权策略和偏最小二乘(PLS)加权策略。其中,PLS加权策略被选为最优方法,因为它能够有效处理子模型预测之间的多重共线性问题。PLS是一种统计方法,通过分解数据的相关性来提取主要成分,从而降低变量间的复杂关系。
为了验证SE-ELM模型的性能,研究者在六个实际光谱数据集上进行了实验,并将其与传统的ELM、反向传播神经网络(BPNN)和径向基函数神经网络(RBFNN)进行了对比。实验结果通过Wilcoxon签署了rank.test的统计检验,表明SE-ELM模型在整体上表现出更好的鲁棒性和准确性。特别是基于PLS的加权策略,在统计上至少不逊于且通常优于WTA和CNNLS加权策略。
这项工作展示了堆叠集成与PLS加权策略如何有效地增强ELM模型的性能,对于化学计量学和其他领域中的非线性问题提供了有力的解决方案。这种结合方法不仅提高了预测精度,还增强了模型对数据变化的适应性,为未来的相关研究提供了有价值的参考。
[β
i1
, ⋯, β
in
]
T
is the output weight vector connecting the ith hidden
node and the output nodes.
The N equations can be rewritten compactly as:
Hβ ¼ Y ð2Þ
where
H ¼
h x
1
ðÞ
⋮
h x
N
ðÞ
2
4
3
5
¼
G ω
1
x
1
þ b
1
ðÞ⋯ G ω
L
x
1
þ b
L
ðÞ
⋮⋯⋮
G ω
1
x
N
þ b
1
ðÞ⋯ G ω
L
x
N
þ b
L
ðÞ
2
4
3
5
NL
ð3Þ
β ¼
β
T
1
⋮
β
T
L
2
4
3
5
Ln
and Y ¼
y
T
1
⋮
y
T
N
2
4
3
5
Nn
ð4Þ
H is called the hidden layer output matrix; the ith column of H is the
ith hidden node output with respect to inputs x
1
, x
2
, … , x
N
,theith row
of H is the hidden layer feature mapping with respect to the ith input x
i
.
β and Y represent the output weight matrix and output matrix,
respectively.
In general, the output weight matrix β is solved by minimizing the
approximation error in the squared error sense:
min
β∈R
Ln
Hβ−Ykk
F
ð5Þ
The optimal solution to Eq. (5) is given by
^
β ¼ H
þ
Y ð6Þ
where H
+
is the Moore–Penrose generalized inverse of the matrix H.
2.3. Proposed stacked ensemble ELM
Stacked generalization is a widely used and effective ensemble tech-
nique to combine (usually linearly) several different prediction sub-
models to improve predictive performance. In stacked generalization,
some ver sion of cross validation of sub-models is performed and the
predictions of sub-models during cross validation are stacked (denoted
as stacked X). The corresponding reference values of y are also stacked
(denoted as stacked y). A regression between stacked X and y can be
performed to determine the optimal weighted combination of predic-
tions from a library of candidate sub-models. Optimality is defined by
a user-specified objective function, such as minimizing the root mean
squared error of cross-validation (RMSECV) for the obtained final
model.
The proposed stacked ensemble ELM (SE-ELM) is very simple and
actually an application of ELM in the frame of stacked generalization.
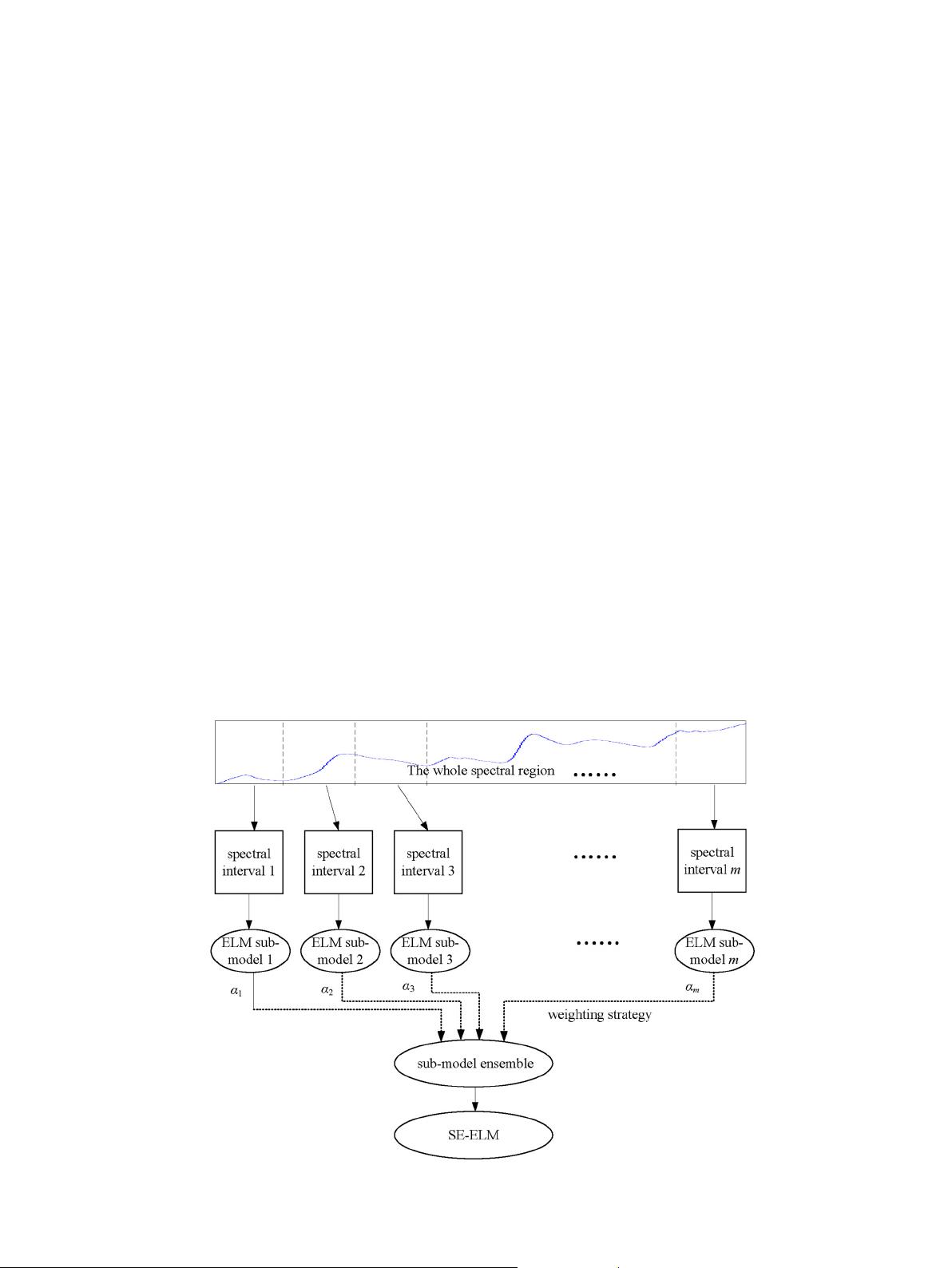
Fig. 2 shows the basic framework of SE-ELM model. The SE-ELM consists
of two key stages: sub-model generation and sub-model combination.
When SE-ELM is in the stage of sub-models generation, spectral interval
division is the key [31,32]. Firstly, original spectral matrix X is firstly
split into m disjoint intervals X
k
(k =1,2,… , m) of equal width (of p/
m variables). Then ELM based sub-models are generated to mine the
nonlinear relationship between each of the m intervals X
k
(k =1,2,…
,m) and the target property vector y. The number of intervals m can
be seen as a parameter to generate many sub-models. That is, the sub-
models are generated from the whole training set sampling from a pa-
rameter space. At the end of the entire cross-validation process of
each ELM sub-model, m different Monte Carlo cross-validated predicted
outputs
^
y
ELM‐MCCV
i
ði ¼ 1; ⋯; mÞ is obtained and then assembled to form a
matrix F ¼
^
y
ELM‐MCCV
1
;
^
y
ELM‐MCCV
2
; ⋯;
^
y
ELM‐MCCV
m
hi
. It is worth noting
that SE-ELM uses different number of hidden notes for all sub-interval
models. Namely, sub-interval models from different spectral region
have a different model complexity.
Once a collection of appropriate ELM based sub-models are gener-
ated from the whole calibration set, the subsequent step is to combine
these sub-models into an integrated model in an appropriate weighting
strategy. Generally, weighting strategi es include two kinds, linear
weighting methods and nonlinear weighting methods, in which the for-
mer are simple and most favored by users. Given this, we choose linear
Fig. 2. The basic framework of SE-ELM model.
99P. Shan et al. / Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy 215 (2019) 97–111
剩余14页未读,继续阅读
2021-11-15 上传
2023-02-23 上传
2021-10-04 上传
2019-05-22 上传
2019-05-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38697063
- 粉丝: 6
- 资源: 956
 我的内容管理
展开
我的内容管理
展开







