GPT-4性能革命:OpenAI科学家揭示1000倍提升的秘密
需积分: 0 59 浏览量
更新于2024-08-03
收藏 2.52MB PDF 举报
“OpenAI科学家HyungWon Chung在最新的演讲中指出,GPT-4模型的性能将在不久的将来出现显著提升,预计将达到1000倍的性能增长。他强调了模型规模在人工智能发展中的关键作用,认为只有达到一定规模,模型才能展现出某些特定能力,这种现象称为‘涌现’。他还提到,随着模型规模的扩大,对于AI技术的理解和应用也将发生根本性转变。此外,他还分享了自己在实验中记录失败过程,以便随着模型的更新不断调整认知的方法。GPT-3和GPT-4之间存在显著能力差距,而Transformer架构是目前大规模模型的基础,理解其核心思想和扩展方法对于技术人员至关重要。”
在OpenAI科学家HyungWon Chung的演讲中,他揭示了GPT-4模型即将迎来的性能飞跃。他指出,随着模型规模的不断扩大,AI的能力会出现“涌现”现象,即某些能力只有在模型达到足够规模时才会显现。这一观点挑战了我们对小模型能力的常规认识,因为小模型可能无法处理某些任务,而大型模型则可能突然展现出优秀的性能。Chung鼓励研究者保持开放思维,不要轻易否定大模型的可能性,因为随着规模的扩大,现有的方法可能会在未来变得有效。
Transformer架构是目前构建大规模语言模型的基石,所有的大型模型,如GPT-3和即将推出的GPT-4,都基于此架构。Chung强调,理解Transformer的底层原理对于扩展模型至关重要,而不是仅仅关注其内部细节。他解释,Transformer可以视为一种简洁的序列到序列映射,通过矩阵乘法实现,而扩大Transformer规模意味着在硬件支持下高效执行大量矩阵运算。为了实现这一目标,研究人员使用了如注意力机制分解和分布式计算方法(如GSPMD)来优化并行计算,以应对更大规模的模型训练。
Chung还分享了他的研究方法论,他主张记录实验失败的经验,以便在新的模型推出时重新评估,这有助于持续更新和纠正对AI技术的理解。这种迭代和反思的过程对于适应快速发展的AI领域至关重要。他提醒,尽管当前GPT-3和GPT-4之间存在能力差距,但随着规模和新技术的应用,这些差距有望被逐步缩小。
这场演讲突显了模型规模在AI发展中的决定性作用,以及对Transformer架构深入理解的重要性。同时,它也提倡了一种动态的学习和研究方法,以适应这个快速变化的领域。随着GPT-4等新一代模型的出现,我们可以期待AI性能的显著提升,并在各种应用场景中看到更多创新。
OpenAI科学家最新演讲:GPT-
4即将超越拐点,1000倍性能必定涌现!
Hyung Won
Chung强调的核心点是,「持续学习,更新认知,采取以“规模”为先的视
角非常重要」。
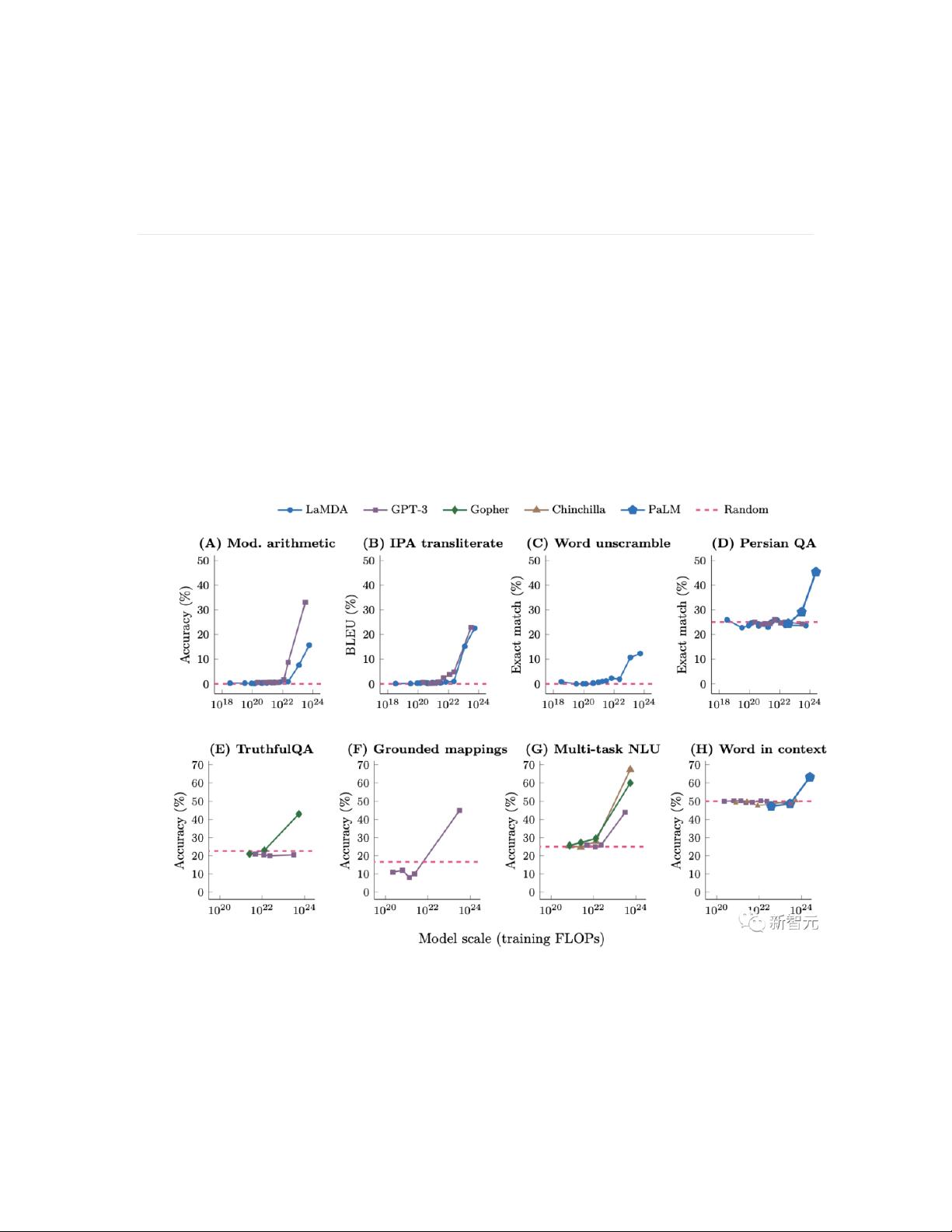
因为只有在模型达到一定规模时,某些能力才会浮现。
多项研究表明,小模型无法解决一些任务,有时候还得需要依靠随机猜测
,但当模型达到一定规模时,就一下子解决了,甚至有时表现非常出色。
因此,人们将这种现象称之为「涌现」。
即便当前一代LLM还无法展现出某些能力,我们也不应该轻言「它不行」
。相反,我们应该思考「它还没行」。
一旦模型规模扩大,许多结论都会发生改变。
下载后可阅读完整内容,剩余9页未读,立即下载
2023-10-26 上传
2023-06-06 上传
2024-04-12 上传
2023-11-14 上传
2023-03-31 上传
2023-09-27 上传
2023-04-01 上传
2023-05-13 上传
2023-05-13 上传

毕业小助手
- 粉丝: 2737
- 资源: 5598
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
