
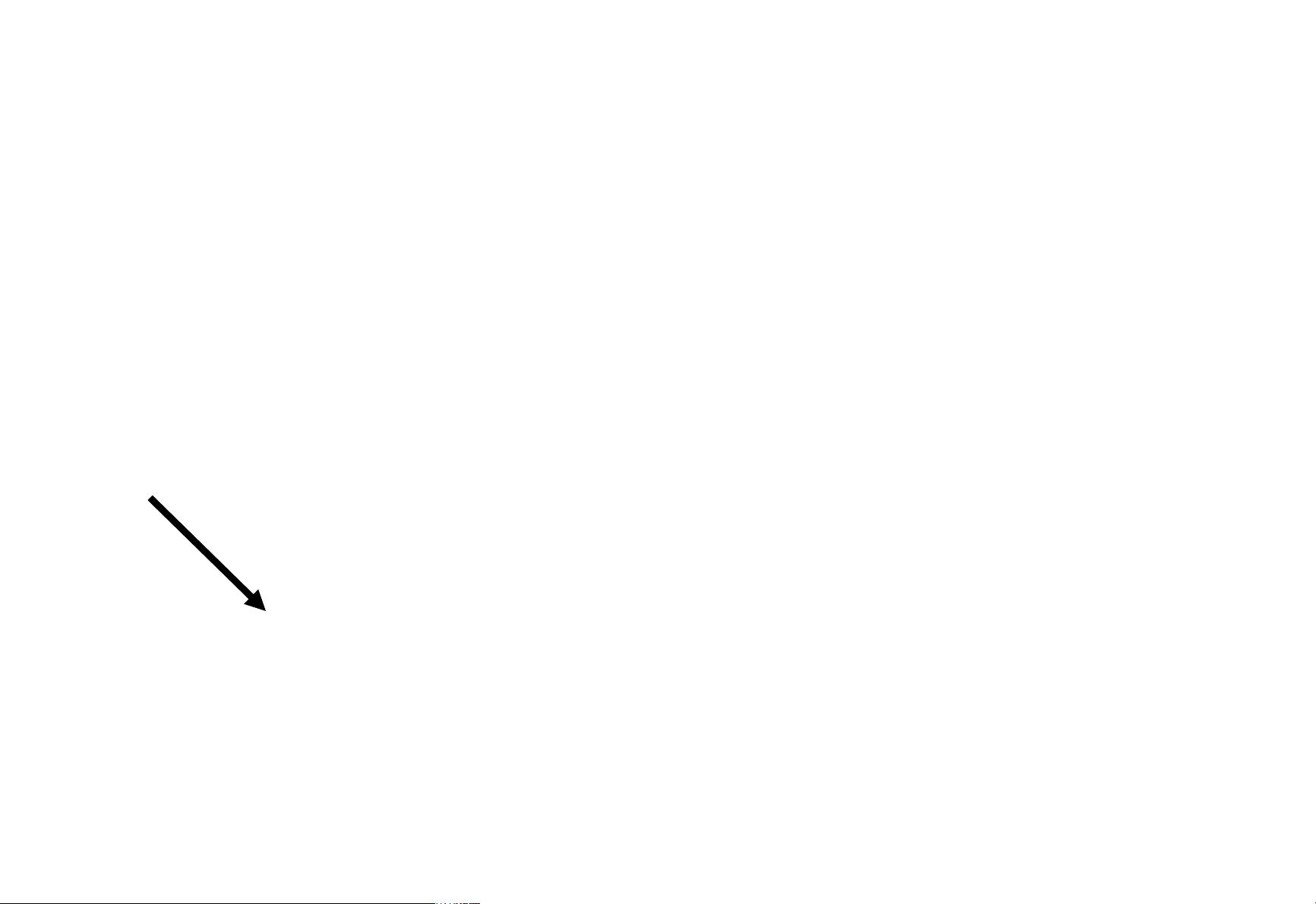
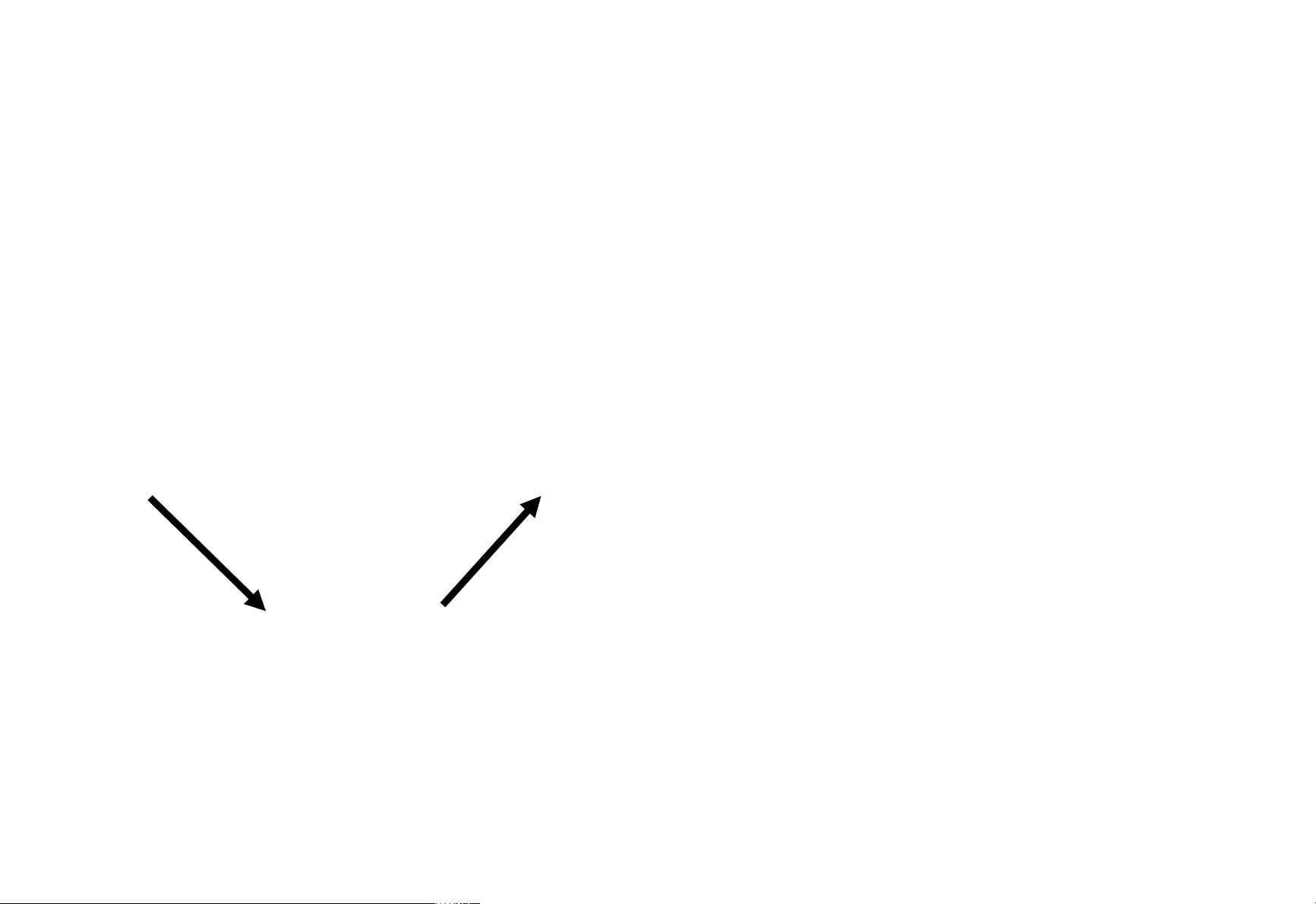
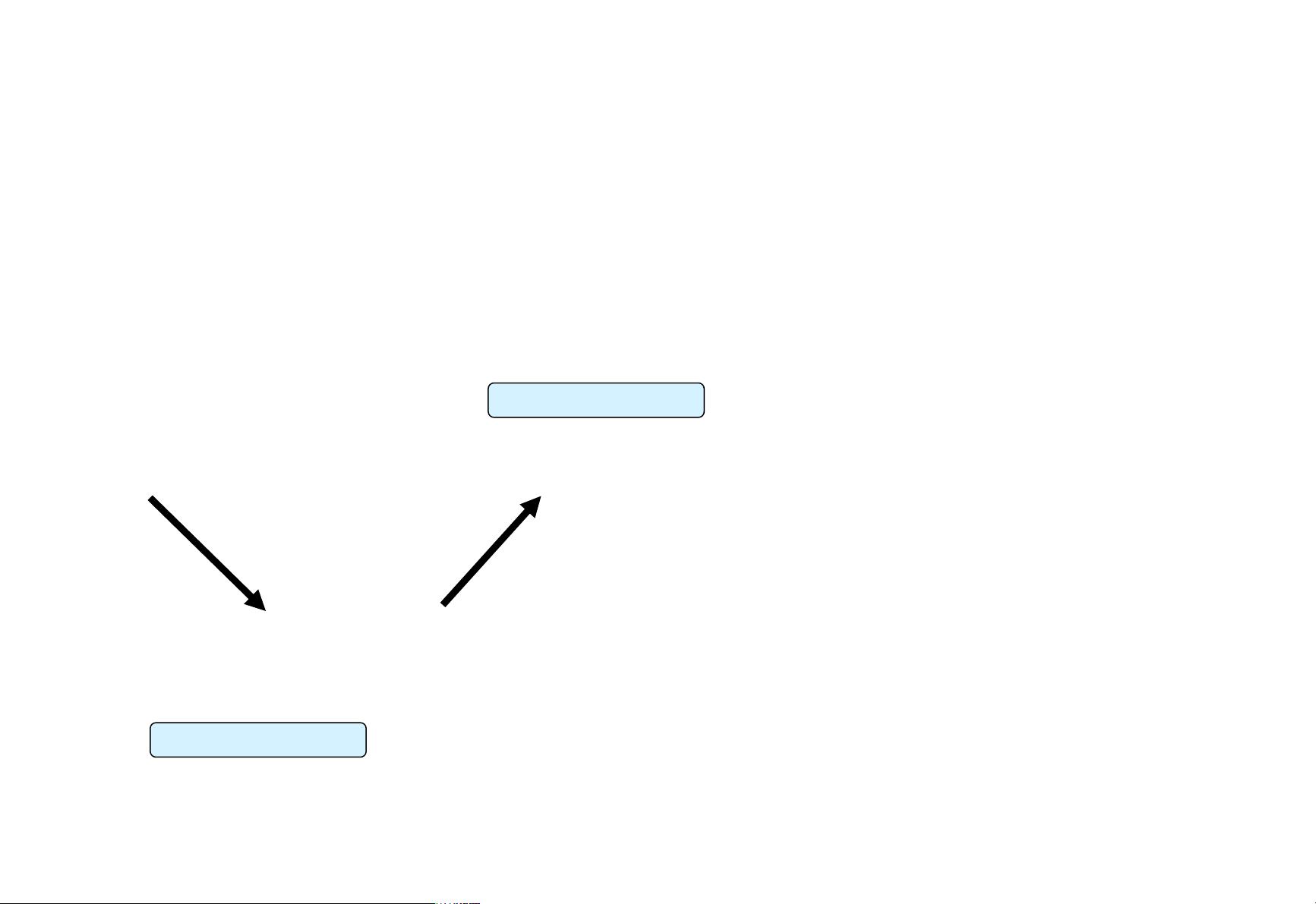
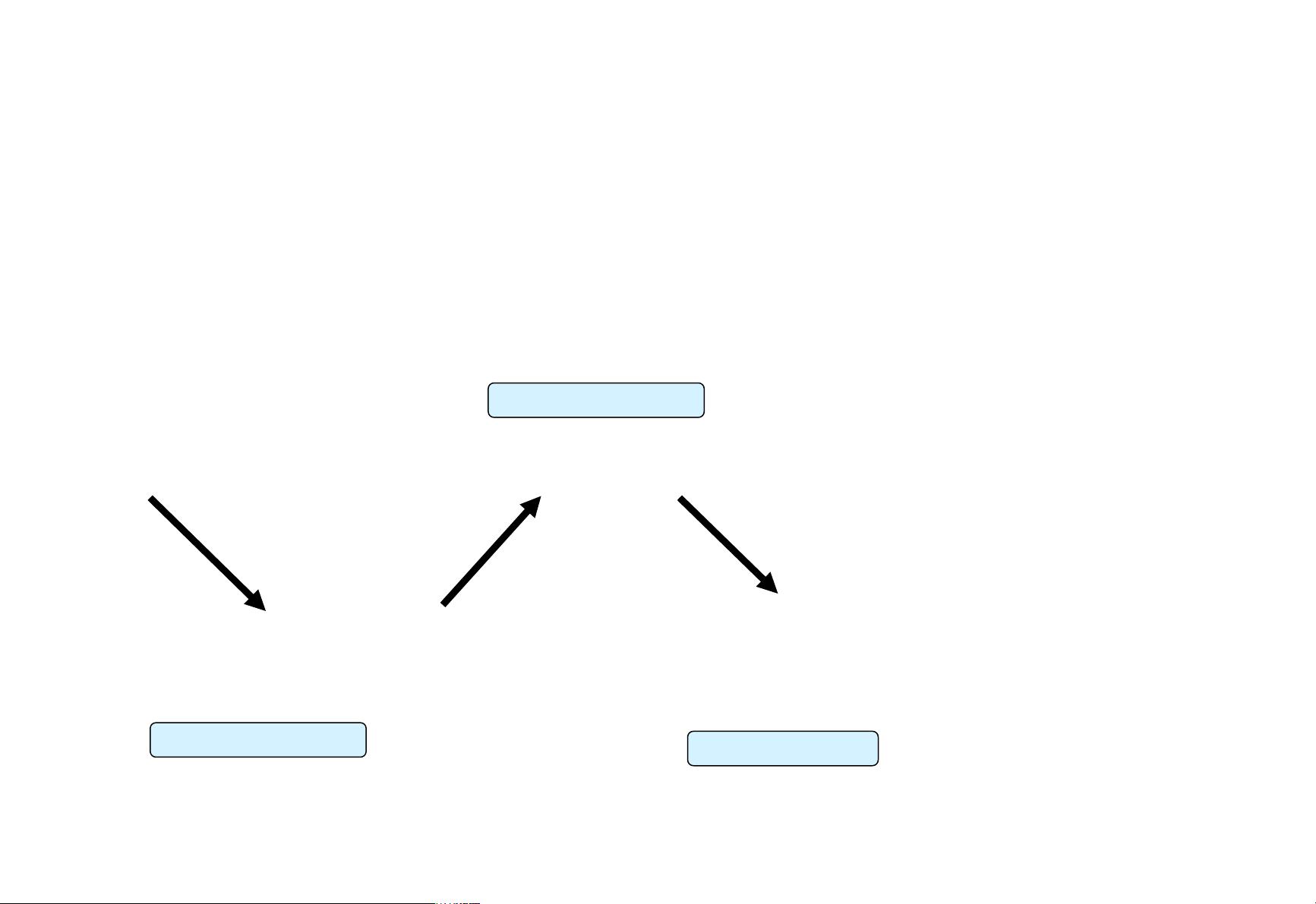
The Problem with Semi-Supervised Bootstrap
Learning
Paris
Pittsburgh
Seattle
Cupertino
mayor of arg1
live in arg1
剩余141页未读,继续阅读

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- 最优条件下三次B样条小波边缘检测算子研究
- 深入解析:wav文件格式结构
- JIRA系统配置指南:代理与SSL设置
- 入门必备:电阻电容识别全解析
- U盘制作启动盘:详细教程解决无光驱装系统难题
- Eclipse快捷键大全:提升开发效率的必备秘籍
- C++ Primer Plus中文版:深入学习C++编程必备
- Eclipse常用快捷键汇总与操作指南
- JavaScript作用域解析与面向对象基础
- 软通动力Java笔试题解析
- 自定义标签配置与使用指南
- Android Intent深度解析:组件通信与广播机制
- 增强MyEclipse代码提示功能设置教程
- x86下VMware环境中Openwrt编译与LuCI集成指南
- S3C2440A嵌入式终端电源管理系统设计探讨
- Intel DTCP-IP技术在数字家庭中的内容保护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


