深度学习框架:多目标追踪与检测融合
124 浏览量
更新于2024-08-26
收藏 2.49MB PDF 举报
"这篇研究论文聚焦于多目标跟踪这一计算机视觉领域的基本但未得到充分解决的问题。作者提出了一种新颖的学习框架,通过检测来实现多个目标的跟踪。该框架强调了从标注视频数据中学习判别性结构预测模型,以捕捉多个影响因素之间的相互依赖关系。"
在传统的多目标跟踪中,算法往往依赖于启发式方法定义。然而,这篇论文的创新之处在于,它不再依靠人工设计的跟踪算法,而是通过学习来建立一个能区分的结构预测模型。这个模型能够从已标记的视频数据中学习,并捕获多个目标之间的相互影响。具体来说,给定上一时间步的联合目标状态和当前帧的观测结果,可以通过最大化联合概率分数来推断出当前时间步的联合目标状态。
此外,论文还探讨了如何使检测结果受益于跟踪线索。传统的检测算法通常需要非极大值抑制后处理步骤,从全部检测响应中选择一个子集作为最终输出。然而,这种方法容易导致错误的选择,特别是在目标密集或拥挤的场景中。论文提出的框架结合了跟踪信息,提高了检测的准确性,减少了错误选择的发生。
为了实现这一框架,论文可能涉及了深度学习技术,如卷积神经网络(CNN)用于目标检测,以及马尔科夫决策过程(MDP)或者贝叶斯网络来建模目标状态的变化。这样的方法有望提升复杂环境下多目标跟踪的性能,减少丢失目标和误识别的情况。
总体而言,这篇《IEEE Transactions on Neural Networks and Learning Systems》上的论文提供了对多目标跟踪问题的新见解,通过学习和利用目标间的相互依赖,以及整合跟踪与检测的线索,旨在提高计算机视觉系统在追踪多个动态目标时的效率和准确度。这对于监控、自动驾驶、无人机导航等应用具有重要意义。
1062 IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 26, NO. 5, MAY 2015
learned discriminative appearance models for each target to
distinguish between interaction targets. In order to achieve
robust tracking with unreliable detection source, a number
of particle filter-based methods avoid directly using the final
sparse detection output for computing the weights of the
particles. Breitenstein et al. [1] explored to use the continuous
detection confidence as a graded observation model to track
multiple persons. Their approach is based on a combination
of a class-specific pedestrian detector to localize people and
a particle filter to predict the target locations, incorporating
a motion model.
C. Detection Postprocessing
Existing detectors give repeated responses for a single
object, so postprocessing is needed to reconcile the multiple
responses, which is usually implemented by NMS.
Desai et al. [37] proposed a discriminative model to
learn the spatial interaction between different classes of
objects. The model learns statistics that capture spatial
arrangements of various object classes. Alternatively,
Sadeghi and Farhadi [38] decoded detector outputs to produce
final results through designing context-aware feature. They
argued that their feature representation resulted in a fast
and exact inference method. These methods used only static
information to construct their models. To the best of our
knowledge, there is no existing method that systematically
and schematically integrates temporal continuity and
scene structure in videos to conduct the reconciliation
postprocessing.
III. T
RACKING FRAMEWORK
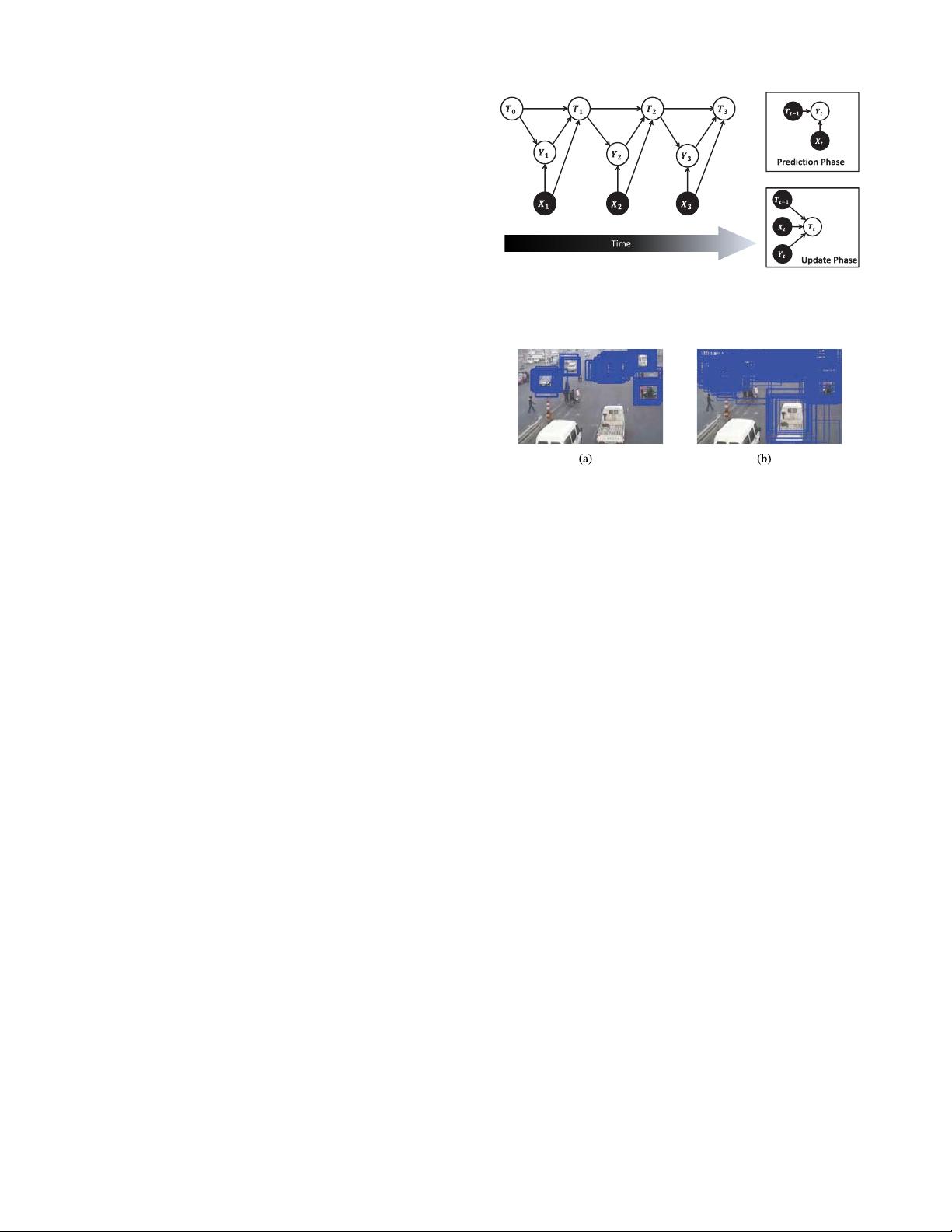
Our algorithm consists of two phases at each time step:
1) prediction and 2) update. At the prediction phase, the
algorithm predicts the labels of the observation based on the
previous tracking state. We use the original detection results
as observation. Some of these results correspond to existing
and newly tracked objects, but there are also repeated detec-
tions and FPs. The prediction operation is therefore required
to distinguish the observation data. Since the output labels
are interdependent, this is a structured prediction problem.
To achieve the necessary robustness, we learn a discriminative
max-margin model from training instead of heuristically defin-
ing a labeling strategy. Given the observation and previous
state as input, the model predicts the observation labels by
maximizing a potential function. At the update phase, the
algorithm uses labeled observation to update the tracking state.
We model the update phase in a first-order Markov chain, i.e.,
the current tracking state only relies on the state of the last
frame and the current observation. Fig. 1 shows the processing
line of our tracking framework.
A. Problem Setting and Notation
We use original detection results as observation. Instead of
proposing a new domain specific detection model, we simply
utilize the code of commonly used part-based model [24].
It should be mentioned that we only need root bounding boxes
Fig. 1. Our tracking processing line. It contains prediction phase and update
phase at each time step. At the prediction phase, the algorithm predicts labels
of the observation. At the update phase, the algorithm updates the tracking
states.
Fig. 2. (a) Threshold 0 is used and only 4/10 objects are successfully detected.
(b) Threshold −0.5 is used and 9/10 objects are successfully detected.
as observation for the following steps. Any other detector
which can return bounding boxes as the detection results is
suitable to take its place. This is a significant advantage over
other methods [4], which need a limb detector or body part
detector. To detect objects in an image, the local detector
evaluates the grid in each position, and each scale, by a filter-
like classifier and returns a detection score. A grid with a
higher score than a threshold will be regarded as a positive
response. Fig. 2(a) and (b) shows the detection responses with
different thresholds.
We collect the detection results above a relatively low
threshold so that all the targets that appear can be observed
most of the time. Each detection response at time t is then
represented as a 5-tube vector
X
i,t
=
x
i,t
, y
i,t
, s
(X)
i,t
, F
i,t
, r
i,t
(1)
where (x
i,t
, y
i,t
) indicates the center position of the detected
bounding box, s
(X)
i,t
indicates the area of the bounding box,
F
i,t
is the appearance descriptor, and r
i,t
is the detection score.
Suppose there are M detection results in total at time t.The
observation is represented by
X
t
={X
i,t
: i = 1 ...M}. (2)
Each tracked object is independently represented as a 6-tube
vector
T
i,t
=
u
i,t
,v
i,t
, ˙u
i,t
, ˙v
i,t
, s
(T )
i,t
, G
i,t
(3)
where (u
i,t
,v
i,t
) indicates its current center position, ( ˙u
i,t
, ˙v
i,t
)
indicates its velocity, s
(T )
i,t
is the area of the bounding box,
and G
i,t
is its appearance descriptor. Suppose there are K
activating trajectories at time t. The joint state is represented as
T
t
={T
i,t
: i = 1 ...K }. (4)
T
0
is initialized to be an empty set.
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-04-29 上传
2022-07-14 上传
2013-09-06 上传
2022-04-28 上传
2022-07-15 上传
点击了解资源详情

weixin_38542148
- 粉丝: 4
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
