Hadoop2.0分布式HA环境部署与Zookeeper协调机制
需积分: 10 43 浏览量
更新于2024-09-07
收藏 312KB DOCX 举报
"Hadoop2.0分布式HA环境部署涉及了高可用性(HA)机制的增强,通过Zookeeper实现NameNode的主备切换,确保集群稳定性。"
在Hadoop1.0时代,集群的主要问题在于单点故障(Single Point of Failure, SPOF),因为NameNode作为元数据管理的核心节点,一旦宕机,整个集群的服务会受到影响,需要人工干预恢复。为了解决这个问题,Hadoop2.0引入了HA机制,允许有多个NameNode同时运行,其中一个作为Active状态提供服务,另一个作为Standby状态备用。这种设计显著提高了系统的可用性和可靠性。
Hadoop2.0的HA机制基于Zookeeper,一个分布式协调服务,用于监控NameNode的状态。Zookeeper集群负责检测NameNode的健康状况,并在Active NameNode出现问题时,触发FailoverController进行主备切换,确保服务的连续性。这个过程是自动的,无需人工操作,大大降低了系统中断的风险。
Hadoop2.0的集群架构还支持NameSpace Federation,即多个独立的命名空间可以组合成一个大的联盟集群,每个命名空间都有自己的元数据节点,这进一步提升了系统的扩展性和管理效率。每个命名空间内的元数据节点通过JournalNode进行数据同步,确保Active和Standby NameNode之间的数据一致性。
在Hadoop2.0集群中,有以下几个关键特点:
1. 共享存储:JournalNode作为数据共享的媒介,使得Active和Standby NameNode能实时同步元数据变更。
2. 数据上报:DataNode节点会同时向两个NameNode报告块信息,确保NameNode对集群状态的全面了解。
3. 应用监控:Zookeeper提供同步锁机制,监控心跳等信息,确保健康运行。
4. 防止脑裂:通过Zookeeper的仲裁机制,确保任何时候只有一个NameNode对外提供服务,避免了数据不一致的情况。
5. 客户端隔离和DataNode隔离:客户端和DataNode只与当前的Active NameNode交互,避免了混乱。
在部署Hadoop2.0分布式HA环境时,还需要在Linux虚拟机上进行一系列的准备工作,例如安装JDK 1.8、创建专门的用户(如`work`)、安装必要的软件(如`fuser`),并设置相应的文件目录结构,将配置文件放在指定的位置(如`/application`)。在整个过程中,推荐使用非root用户进行日常操作,以增加系统的安全性。
在实际部署过程中,需要仔细配置Hadoop的相关参数,如Zookeeper的地址、JournalNode的设置、NameNode的HA配置等,确保所有组件能够协同工作。同时,测试Failover流程是至关重要的,以验证在NameNode故障时,系统能够无缝切换到备用节点,保持服务的不间断。
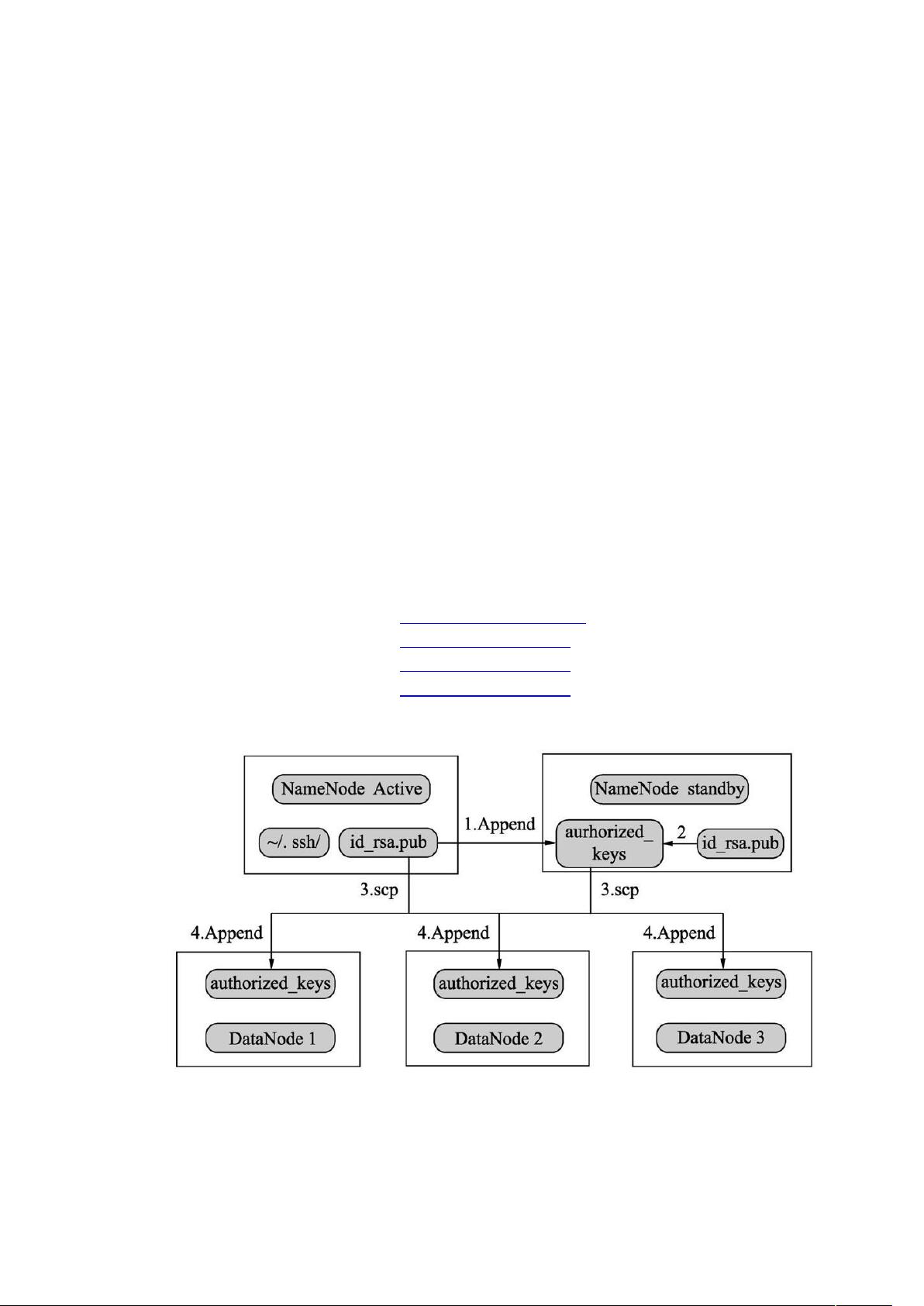
安装 免密登录
创建密钥
6171
输入上述命令后,下面操作只需要按回车键,不用设置任何信息
命令结束会在82 62目录生成对应的私钥和公钥等文件(9 9 !)
认证授权
公钥文件追加到 6:9 文件,操作如下:
82 629 !;;82 626:9
"文件赋权
在 / 账户下,需要给 6:9 赋予 ) 权限,否则会因为权限导致登
录失败,操作如下:
6)82 626:9
#其他节点创建密钥
使 用 / 用 户 , 分 别 在 其 他 服 务 器 上 创 建 密 钥 , 然 后 将 各 个 节 点 的 公 钥
(9 !)文件中内容追加到 节点的 6:9 操作如下:
6/< 82 629 !;;82 626:9
6/< 82 629 !;;82 626:9
6/< 82 629 !;;82 626:9
6/< "82 629 !;;82 626:9
将最终生成的 6:9 文件分发到每台服务器的82 62文件目录下。
82 626:9 /< =82 62
82 626:9 /< =82 62
82 626:9 /< =82 62
82 626:9 /< "=82 62
执行( 6服务名)切换,如: 6
第一次需要输入密码,之后就可以正常登陆了,各个节点 关系分布图如下:
.关闭防火墙(或端口限制)
>/ 查看防火墙是否关闭
>/ 关闭防火墙
由于 34 服务器版本相关命令不一致,可网上搜索关闭的方式
剩余11页未读,继续阅读
2013-12-23 上传
2021-09-29 上传
2021-09-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

开心农场208
- 粉丝: 14
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
