深入理解Hive:高级编程与优化
需积分: 5 55 浏览量
更新于2024-07-20
1
收藏 1.13MB PDF 举报
"该资源是关于Hive高级编程的学习资料,涵盖了Hive组件、MapReduce、HiveQL、Hive优化以及SQL优化等主题。资料可能包含一个PDF文档,提供了对大数据处理工具Hive深入的理解,包括其在Facebook中的应用、与HDFS的交互、Hive命令行接口(HiveCLI)的使用、数据定义语言(DDL)、查询执行、元数据存储(MetaStore)、Thrift API、序列化反序列化(SerDe)等内容。此外,还涉及了MapReduce的工作流程以及Hive如何通过HiveQL进行JOIN操作的示例。"
Hive是一个基于Hadoop的数据仓库工具,它允许使用类SQL查询语言(HiveQL)来管理和分析存储在Hadoop分布式文件系统(HDFS)上的大型数据集。Hive的主要组件包括:
1. **Hive CLI**: 提供了一个命令行界面,用户可以在这个界面上执行HQL语句。
2. **DDL**: Hive支持数据定义语言,用于创建、修改和删除数据表等数据库对象。
3. **MetaStore**: 存储有关Hive表和分区的元数据,如表名、列名、列类型、表分区等。
4. **Thrift API**: 用于外部应用程序与Hive通信,支持多种编程语言,使得非Java应用也能访问Hive。
5. **SerDe**: 序列化和反序列化库,用于将不同格式的数据转换为Hive可以理解的格式。
**MapReduce** 是Hadoop的核心计算框架,Hive在执行查询时,会将HQL转化为一系列的MapReduce任务。Map阶段将输入数据拆分成键值对,Reduce阶段则将相同键的数据聚集到一起进行处理。
**HiveQL** 是Hive的查询语言,类似SQL,但有其特殊性,比如JOIN操作。在HiveQL中,JOIN操作通常会在MapReduce中实现,例如上述示例展示了如何通过JOIN将`page_view`和`user`表连接成新的`pv_users`表。JOIN操作在Map阶段将键值对分发,Shuffle阶段根据键进行排序和聚合,最后Reduce阶段处理每个键对应的值。
**Hive优化** 包括SQL优化和执行优化。SQL优化主要关注如何更高效地编写HQL,减少不必要的计算和数据传输。执行优化则涉及到如何配置Hive以提高查询性能,比如通过调整MapReduce的参数,或者使用更高效的执行引擎如Tez或Spark。
这份Hive高级编程资料将帮助读者深入了解Hive的工作原理,掌握高级查询技巧,并了解如何优化Hive的性能,从而更好地利用Hive处理大数据问题。
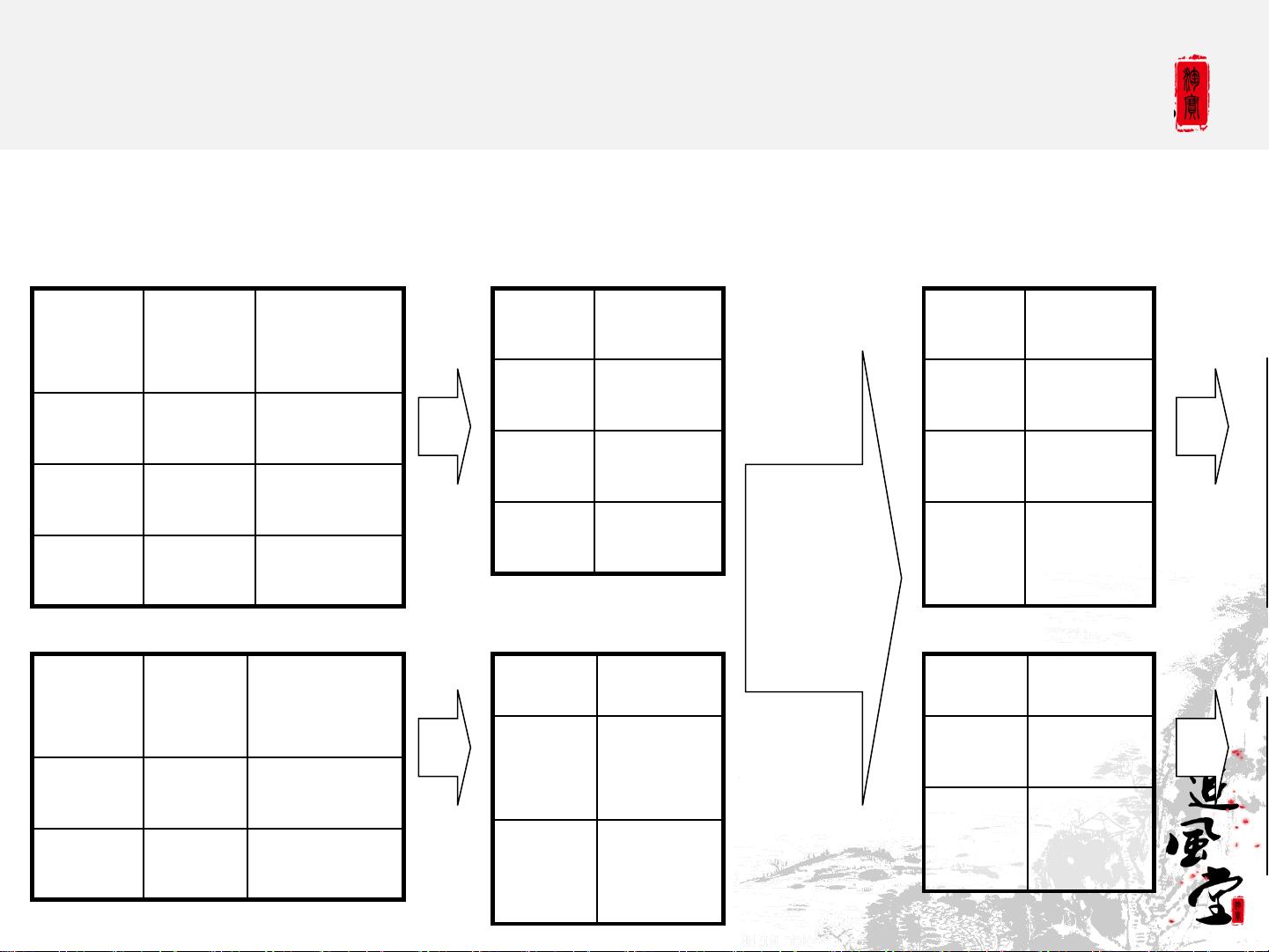
Hive QL – Join in Map Reduce
key value
111 <1,1>
111 <1,2>
222 <1,1>
pagei
d
useri
d
time
1 111 9:08:01
2 111 9:08:13
1 222 9:08:14
useri
d
age gender
111 25 female
222 32 male
page_view
user
key value
111 <2,25
>
222 <2,32
>
Map
key value
111 <1,1>
111 <1,2>
111 <2,25
>
key value
222 <1,1>
222 <2,32
>
Shuffle
Sort
pagei
pagei
Reduce
剩余26页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
167 浏览量
2021-12-25 上传
点击了解资源详情
点击了解资源详情

郭龙_Jack
- 粉丝: 265
- 资源: 57
 我的内容管理
展开
我的内容管理
展开







最新资源
- vml+asp实现投票系统
- delphi 7程序设计与开发技术大全.pdf
- Getting-Started-with-Grails-Chinese.pdf
- Grails+快速开发+Web+应用程序.pdf
- 新型DVB码流监测仪的设计与实现.pdf
- Dem与遥感影像制作三维效果教程
- 操作系统针对性练习题精选
- 使用PowerDesigner 进行数据建模
- Visual Studio 2005快捷键
- ZK简明教程.doc
- linux 101 hacks
- STL中map用法详解
- Web_Service开发指南
- c#自己的用的总结的函数
- 面试管理系统说明书,使用于面试管理系统
- DWR中文文档,实现Ajax无动态刷新
