Hadoop MapTask源码解析:关键类与输出流程
需积分: 10 154 浏览量
更新于2024-09-13
收藏 114KB DOC 举报
"Hadoop源代码分析 - MapTask辅助类第三部分,主要探讨MapTask在处理key和value输出时的内部机制,包括输出缓冲区管理、key-value的串行化以及如何处理非连续的缓冲区情况。"
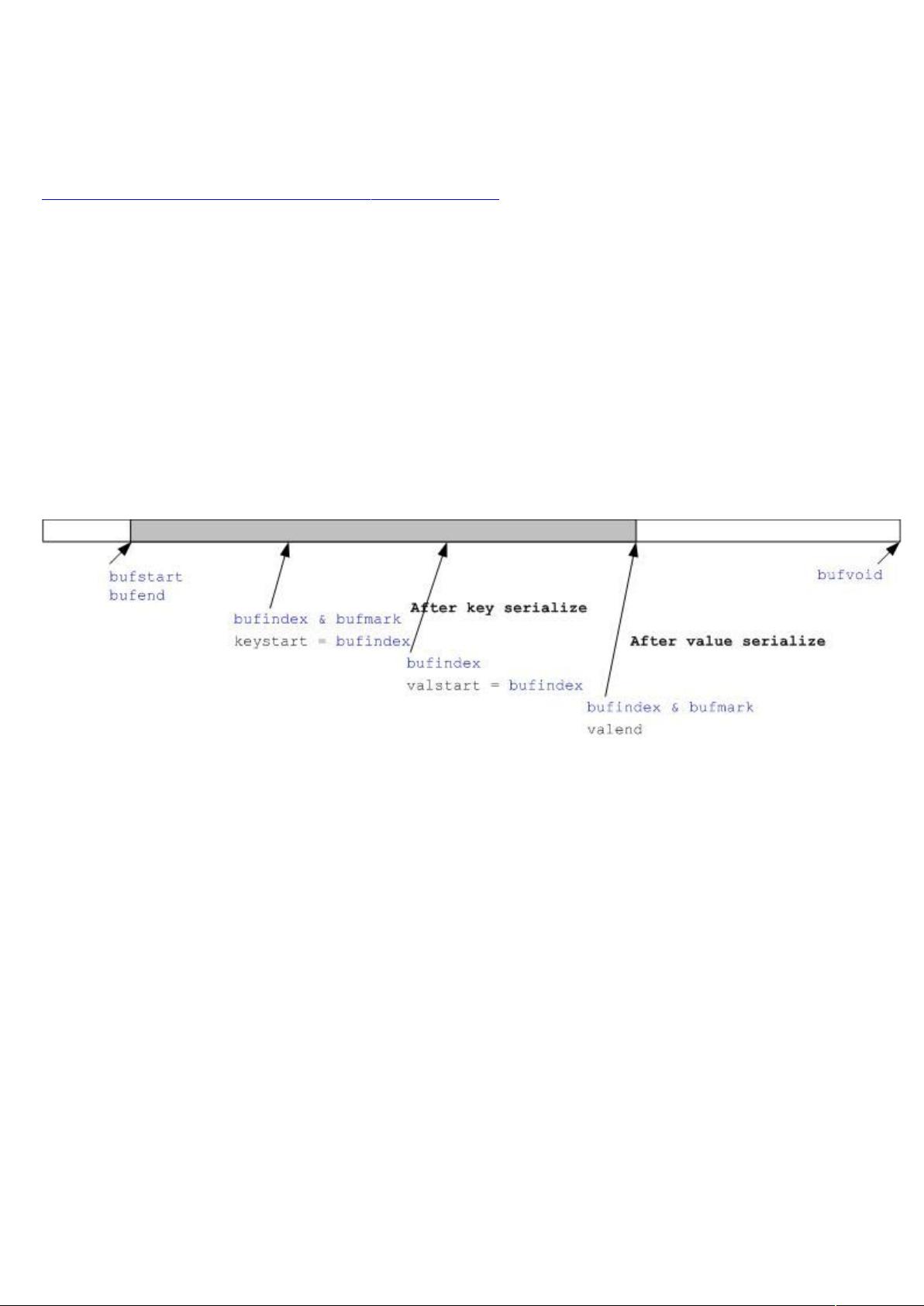
在Hadoop MapReduce框架中,MapTask是一个关键组件,负责处理Mapper阶段的输出数据。在MapTask执行过程中,数据会被序列化并存储到一个输出缓冲区中,等待溢写(spill)到磁盘。这个过程涉及到几个重要的变量和方法,如kvstart、kvend、kvindex、bufstart、bufend、bufmark以及bufvoid。
首先,kvstart、kvend和kvindex是用于追踪当前正在处理的key-value对的开始、结束和索引位置。而bufstart、bufend和bufmark则与输出缓冲区的管理紧密相关,它们分别表示缓冲区的起始、结束和标记位置。bufvoid则指示了实际使用的缓冲区的末尾。
在序列化key和value时,可能会遇到key的长度不固定,导致key的串行化结果不连续。为了确保在spill过程中能对key进行正确的排序,Hadoop使用了BlockingBuffer类来处理这种情况。如果发现key的串行化结果不在缓冲区的连续部分,BlockingBuffer的reset方法会被调用。该方法将bufvoid设为bufmark,将缓冲区中的数据向后移动,确保key的序列化结果在缓冲区的开头。
但是,这种方法有个前提,即缓冲区的剩余空间(从bufstart到bufindex)足够容纳整个key的序列化结果。如果不够,系统会将bufindex重置为0,并直接调用out的write方法,触发spill过程。spill会将当前缓冲区的内容写入磁盘,并创建一个新的溢写文件,这样可以确保所有数据都能正确地按照key排序。
Buffer.write方法在此过程中起到了核心作用,它负责将序列化后的key-value数据写入缓冲区。如果缓冲区满或者达到溢写阈值,write方法会触发spill操作,将数据写入磁盘并释放内存空间,以便继续接收新的数据。
Hadoop MapTask通过精心设计的缓冲区管理和序列化策略,确保了key-value数据的有效处理和排序,为后续的Reduce阶段提供有序的数据输入。这些底层实现细节对于优化Hadoop集群的性能和理解其工作原理至关重要。
Hadoop
源代码分析( MapTask
辅助类, III )
接下来讨论的是 , 的输出,这部分比较复杂,不过有了前面 ,
和 配合的分析,有利于我们理解这部分的代码。
输出缓冲区中,和 , 和 对应的是 , 和
。这部分还涉及到变量 ,用于表明实际使用的缓冲区结尾(见后面
分析),和变量 ,用于标记记录的结尾。这部分代码需要
,是因为 或 的输出是变长的,(前面元信息记录大小是常量,就不需
要这样的变量)。
最好的情况是缓冲区没有翻转和 串行化结果很小,如下图:
先对 串行化,然后对 做串行化,临时变量 , 和 分别
记录了 结果的开始位置, 结果的开始位置和 结果的结束位置。
串行化过程中,往缓冲区写是最终调用了 方法,我们后面再分析。
如果 串行化后出现 !"!,那么会调用 的 方
法。原因是在 # 的过程中需要对",$排序,这种情况下,传递给
%&# 的必须是连续的二进制缓冲区,通过 方法,解决
这个问题。下图解释了如何解决这个问题:
下载后可阅读完整内容,剩余4页未读,立即下载
2016-06-09 上传
2016-06-12 上传
2023-09-11 上传
2023-05-22 上传
2023-06-08 上传
2023-05-28 上传
2023-11-17 上传
2023-04-11 上传
2023-04-14 上传

frank_20080215
- 粉丝: 166
- 资源: 1781
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
