
ABSTRACT
NUMA refers to the computer memory design choice
available for multiprocessors. NUMA means that it will take
longer to access some regions of memory than others. This work
aims at explaining what NUMA is, the background
developments, and how the memory access time depends on the
memory location relative to a processor. First, we present a
background of multiprocessor architectures, and some trends in
hardware that exist along with NUMA. We, then briefly discuss
the changes NUMA demands to be made in two key areas. One
is in the policies the Operating System should implement for
scheduling and run-time memory allocation scheme used for
threads and the other is in the programming approach the
programmers should take, in order to harness NUMA’s full
potential. In the end we also present some numbers for
comparing UMA vs. NUMA’s performance.
Keywords: NUMA, Intel i7, NUMA Awareness, NUMA Distance
SECTIONS
In the following sections we first describe the background,
hardware trends, Operating System’s goals, changes in
programming paradigms, and then we conclude after giving some
numbers for comparison.
Background
Hardware Goals / Performance Criteria
There are 3 criteria on which performance of a multiprocessor
system can be judged, viz. Scalability, Latency and Bandwidth.
Scalability is the ability of a system to demonstrate a proportionate
increase in parallel speedup with the addition of more processors.
Latency is the time taken in sending a message from node A to node
B, while bandwidth is the amount of data that can be communicated
per unit of time. So, the goal of a multiprocessor system is to
achieve a highly scalable, low latency, high bandwidth system.
Parallel Architectures
Typically, there are 2 major types of Parallel Architectures that
are prevalent in the industry: Shared Memory Architecture and
Distributed Memory Architecture. Shared Memory Architecture,
again, is of 2 types: Uniform Memory Access (UMA), and Non-
Uniform Memory Access (NUMA).
Shared Memory Architecture
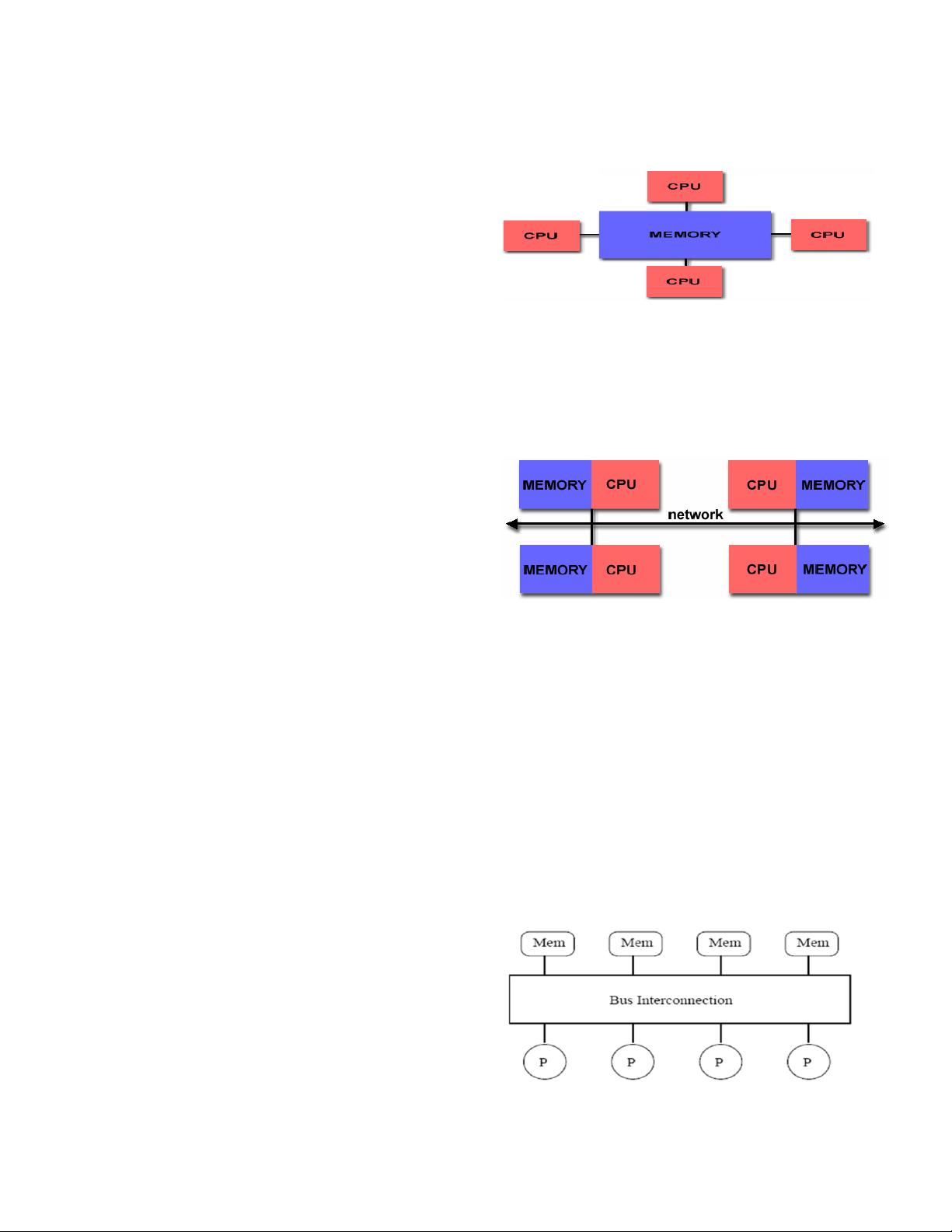
As seen from the figure 1 (more details shown in “Hardware
Trends” section) all processors share the same memory, and treat it
as a global address space. The major challenge to overcome in such
architecture is the issue of Cache Coherency (i.e. every read must
Figure 1 Shared Memory Architecture (from [1])
reflect the latest write). Such architecture is usually adapted in
hardware model of general purpose CPU’s in laptops and
desktops.
Distributed Memory Architecture
In figure 2 (more details shown in “Hardware Trends”
section) type of architecture, all the processors have their own
local memory, and there is no mapping of memory addresses
across processors. So, we don’t have any concept of global
address space or cache coherency. To access data in another
processor, processors use explicit communication. One example
where this architecture is used with clusters, with different nodes
connected over the internet as network.
Shared Memory Architecture – UMA
Shared Memory Architecture, again, is of 2 distinct types,
Uniform Memory Access (UMA), and Non-Uniform Memory
Access (NUMA).
Figure 2 Distributed Memory (from [1])
Figure 3 UMA Architecture Layout (from [3])
Non-Uniform Memory Access (NUMA)
Nakul Manchanda and Karan Anand
New York University
{nm1157, ka804} @cs.nyu.edu
下载后可阅读完整内容,剩余3页未读,立即下载

夏天不热冬天不冷
- 粉丝: 29
- 资源: 29
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


