深度学习中的过拟合、梯度消失与RNN深入理解
140 浏览量
更新于2024-08-30
收藏 236KB PDF 举报
"过拟合、梯度消失、RNN进阶"
在机器学习和深度学习领域,过拟合和欠拟合是两个常见的概念,它们关乎模型的泛化能力。过拟合指的是模型在训练数据上表现优异,但在未见过的测试数据上表现糟糕,这通常是因为模型过于复杂,过度学习了训练数据中的噪声和细节。欠拟合则是模型无法很好地捕捉训练数据的规律,导致训练误差较高。这两种情况可以通过调整模型复杂度和增加训练数据来改善。损失函数是衡量模型性能的关键工具,如均方误差适用于线性回归,而交叉熵损失函数常用于softmax回归。
验证集是用于在模型训练过程中评估模型性能的独立数据集,不参与模型的训练过程,用于防止模型在训练数据上过拟合。K折交叉验证是一种有效的数据利用策略,尤其在数据量有限的情况下,它可以更有效地估计模型的泛化性能。
过拟合的解决方法包括权重衰减(等价于L2范数正则化)和丢弃法。权重衰减通过在损失函数中添加L2范数惩罚项,抑制权重过大,防止模型过于复杂。丢弃法则是在训练过程中随机忽略一部分神经元,增加模型的鲁棒性。
梯度消失和梯度爆炸是深度神经网络中常见的问题,尤其是对于循环神经网络(RNN)而言。梯度消失意味着深层网络中反向传播的梯度变得极小,导致深层节点的权重更新缓慢;梯度爆炸则相反,梯度值变得过大,可能导致权重的不稳定。随机初始化模型参数有助于避免这种问题,确保每个神经元在前向传播时有独立的响应,并在反向传播时获得不同的梯度更新。
循环神经网络(RNN)是一种能处理序列数据的神经网络结构,但由于其长期依赖的问题,常常遇到梯度消失的挑战。为了解决这个问题,后来发展出了长短期记忆网络(LSTM)和门控循环单元(GRU),它们引入了门控机制,更好地保存和控制信息流,从而缓解了梯度消失问题。
环境因素如协变量偏移、标签偏移和概念偏移是现实世界中影响模型性能的常见问题。这些偏移可能导致模型在新的环境中表现不佳,需要持续的数据收集和模型更新以适应不断变化的环境条件。
理解和解决过拟合、梯度消失以及RNN的相关问题对于构建有效的深度学习模型至关重要。通过合理选择模型复杂度、应用正则化技术、优化初始化策略,以及采用先进的RNN变体,我们可以提升模型的泛化能力和稳定性能。
过拟合、梯度消失、过拟合、梯度消失、RNN进阶进阶
一、一、过拟合和欠拟合过拟合和欠拟合
训练误差训练误差:指模型在训练数据集上表现出的误差。
泛化误差泛化误差:指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。(ML应关注此应关注此
项项)
如何计算训练误差或者泛化误差,可以用损失函数损失函数。【损失函数:均方误差(线性回归)、交叉熵损失函数(softmax回归)】
验证集的作用验证集的作用:进行模型选择。
K折交叉验证折交叉验证:由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显得太奢侈。一种改善的方法是
K折交叉验证(K-fold cross-validation)。在K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们
做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验
证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
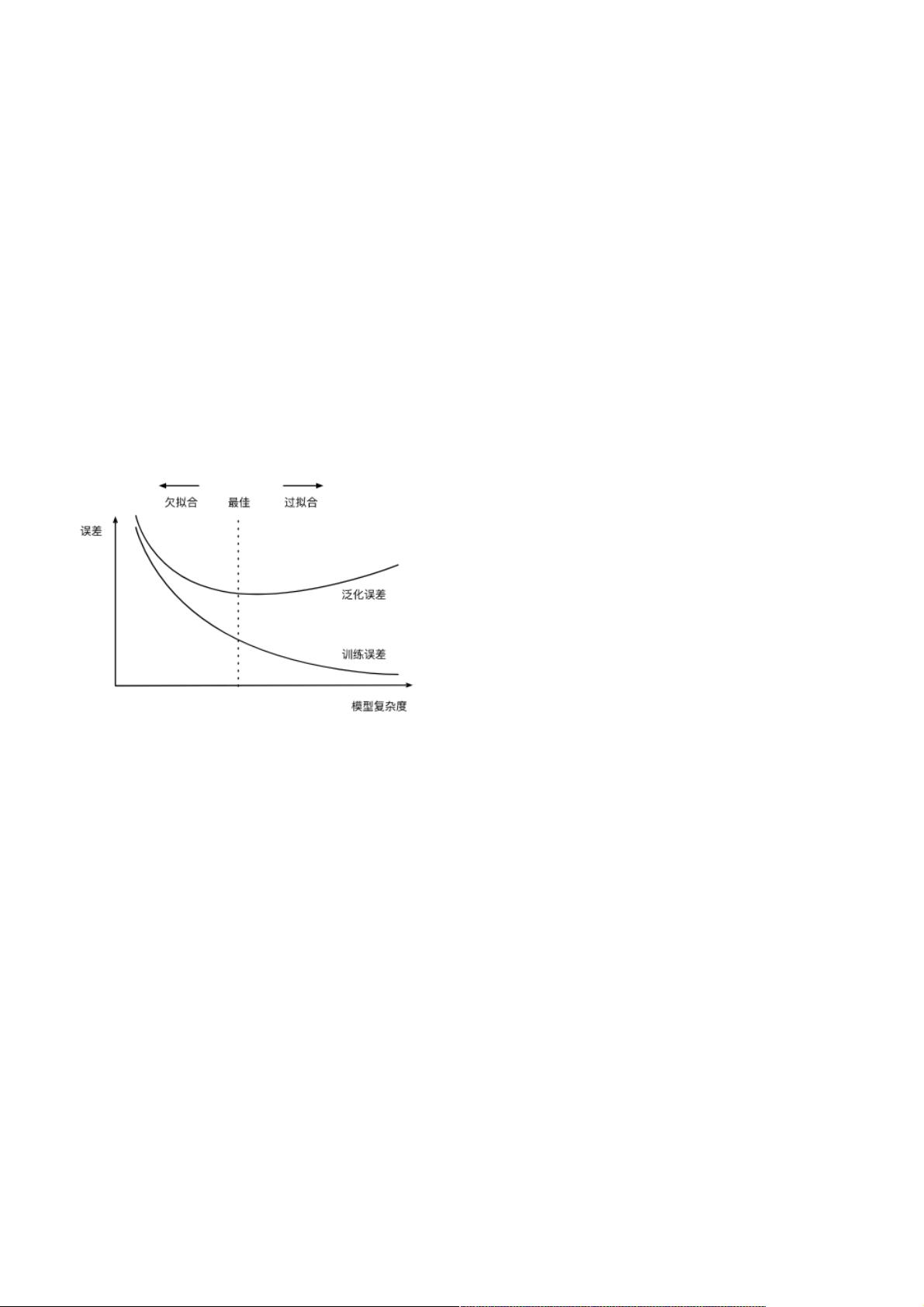
过拟合过拟合:模型的训练误差远小于它在测试数据集上的误差。(解决方法:权重衰减、丢弃法)
欠拟合欠拟合:模型无法得到较低的训练误差。
造成这两种拟合问题的因素有很多,其中两种分别是:模型复杂度模型复杂度和训练数据集大小训练数据集大小。
权重衰减权重衰减:等价于L2范数正则化。(应对过拟合的手段)
L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。
权重衰减通过通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制。
二、梯度消失、梯度爆炸二、梯度消失、梯度爆炸
当神经网络的层数较多时,模型的数值稳定性容易变差。
随机初始化模型参数随机初始化模型参数:
为什么在神经网络中通常需要随机初始化模型参数?为什么在神经网络中通常需要随机初始化模型参数?
假设输出层只保留一个输出单元o1(删去o2和o3以及指向它们的箭头),且隐藏层使用相同的激活函数。如果将每个隐
藏单元的参数都初始化为相等的值,那么在正向传播时每个隐藏单元将根据相同的输入计算出相同的值,并传递至输出层。在
反向传播中,每个隐藏单元的参数梯度值相等。因此,这些参数在使用基于梯度的优化算法迭代后值依然相等。之后的迭代也
是如此。在这种情况下,无论隐藏单元有多少,隐藏层本质上只有1个隐藏单元在发挥作用。因此,正如在前面的实验中所做
的那样,我们通常将神经网络的模型参数,特别是权重参数,进行随机初始化。
环境因素环境因素:协变量偏移、标签偏移、概念偏移。
三、三、RNN进阶进阶
RNN::
RNN存在的问题:梯度较容易出现衰减或爆炸(BPTT)。
控循环神经络:捕捉时间序列中时间步距离较的依赖关系。
下载后可阅读完整内容,剩余3页未读,立即下载
232 浏览量
221 浏览量
188 浏览量
439 浏览量
2021-01-20 上传
335 浏览量
3027 浏览量
935 浏览量
点击了解资源详情

weixin_38744435
- 粉丝: 373
 我的内容管理
展开
我的内容管理
展开







最新资源
- Visual C# 2008初学者教程:微软官方指南
- Weblogic服务器基础配置:工作目录与DB2数据源设置
- FusionCharts详尽教程:创建动态图表与应用指南
- Java变压器模式详解:适配与组合的静态结构模式
- Java实现网页动态统计曲线发布
- iBATIS DataMapper 2.0 开发者指南
- 精通Transact-SQL编程:高级技巧与实战指南
- PKCS#12标准详解:个人信息交换语法
- C#编程:DateTime与常用函数详解
- Python PIL 图像处理快速入门指南
- 编译原理习题解析:变量表与文法规则
- 智能卡应用设计与编程指南:Wolfgang Rankl 著
- HTTP状态码详解:从400到505的错误信息解读
- Java Servlet 2.5 规范详解
- JSTL 1.1官方文档:Java Server Pages标准标签库详解
- FastReport3.0程序员手册:设计与运行报表指南
