探索数据爆炸时代的频繁模式挖掘方法与关联规则
需积分: 50 108 浏览量
更新于2024-07-24
收藏 1.14MB PDF 举报
本文主要介绍了频繁模式挖掘在大数据分析中的重要性和几种常见的方法,特别是针对初学者设计的教程。数据挖掘在当今信息化时代显得尤为重要,随着全球数据量的爆炸式增长,如何从海量数据中提取有价值的信息变得愈发关键。数据挖掘的目标是发现数据中的潜在规律,如商品间的关联关系,这有助于理解消费者的购买行为、预测市场趋势以及在医疗领域发现疾病与基因的关联。
频繁模式(Frequent Pattern)是数据挖掘的核心概念,它指的是在数据集中频繁出现的项集,如商品组合或事件序列。常见的频繁模式挖掘算法有Apriori和FP树。Apriori算法是一种分层搜索的方法,通过“先闭合”策略减少候选集的搜索空间,提高了效率。FP树,全称为Frequency-Preserving Tree,它将频繁项集组织成树形结构,既节省空间又便于查询。
在Apriori算法的例子中,Agrawal等人在1993年的SIGMOD大会上提出了关联规则的概念,如啤酒和尿布之间的关联。支持度是衡量关联规则强度的一个指标,表示某项规则在数据集中出现的频率。比如,如果在5个交易记录中有3次都出现了啤酒和尿布,那么这两个商品的关联规则支持度就是3/5。
Market Basket Analysis(购物篮分析)是频繁模式挖掘的一个典型应用场景,通过对顾客购物记录的分析,找出经常一起购买的商品组合,如上述的啤酒、尿布和婴儿爽身粉等。这种分析有助于商家进行商品推荐、促销活动策划和库存管理。
在挖掘过程中,核心任务是确定哪些项集是频繁的,然后基于这些频繁项集生成关联规则。关联规则的目的是预测消费者的购买行为或者发现其他可能的关联,比如购买微机后可能会购买电脑配件,或者某种特定的DNA片段可能与某种药物反应。
频繁模式挖掘是一种强大的工具,它可以帮助我们从海量数据中发现有价值的规律,为决策提供依据。无论是商业智能、市场营销还是科学研究,理解并掌握频繁模式挖掘的方法都是现代数据分析师必备的技能。
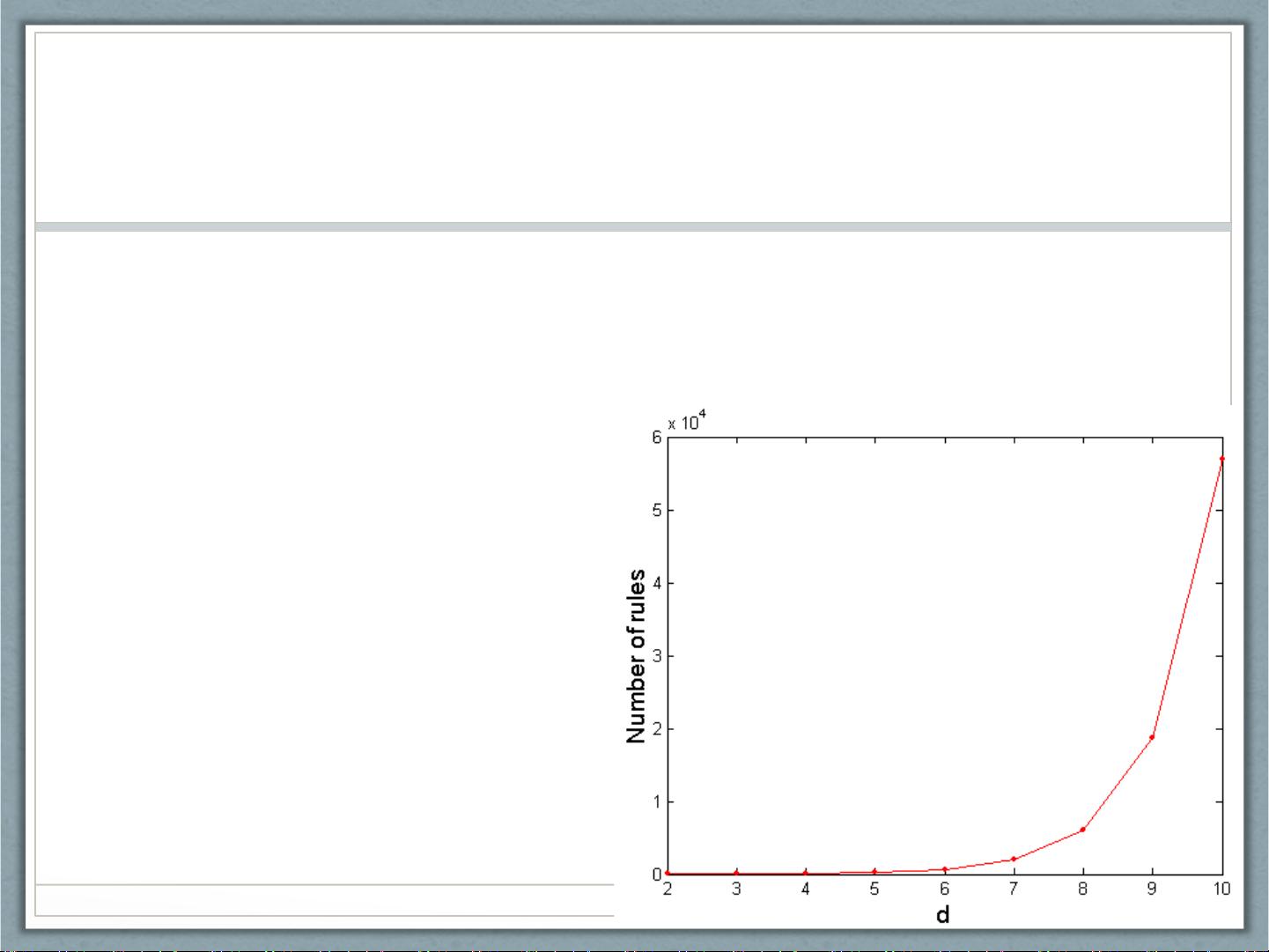
计算复杂性分析
• 给定 d 个不同项,项集数目等于 2
d
• 可能的关联规则总数 R
123
1
1
1 1
+−
=
−
×
=
+
−
=
−
=
∑ ∑
dd
d
k
kd
j
j
kd
k
d
R
若 d=6 则 R = 602
剩余89页未读,继续阅读
2015-01-30 上传
2021-11-10 上传
2018-10-28 上传
2010-05-11 上传
点击了解资源详情
2018-04-24 上传
2021-05-03 上传

xyp1994101
- 粉丝: 3
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
