R中H2O:数据预测实战——模型选择与性能比较
需积分: 11 57 浏览量
更新于2024-07-18
1
收藏 892KB PDF 举报
本篇文章主要探讨如何使用R语言与H2O库进行机器学习中的价格预测。首先,文章介绍了准备工作,包括加载必要的R包,如`mclust`用于数据预处理和聚类分析,以及`dplyr`提供数据操作功能。在进行预测前,先确保安装了H2O版本5.2.3,并提醒读者在引用该包时需注明版本。
文章的核心部分涉及以下几个步骤和知识点:
1. **数据准备**:使用R的`require()`函数加载所需的包,包括`h2o`,这将使我们能够在H2O平台上进行分布式计算,适合大规模数据处理。
2. **H2O初始化**:通过调用`h2o.init()`命令启动H2O服务器,设置本地运行的HTTP服务器地址,以及推荐的文档查看方式。
3. **模型构建**:
- **线性回归模型**:利用H2O的线性回归功能,对数据进行简单线性关系的建模,适用于预测目标与一个或多个自变量之间的线性关系。
- **对数线性回归模型**:当数据呈现对数正态分布时,对数线性回归可以处理非线性关系,通过H2O实现对数据的转换和拟合。
- **随机森林(Random Forest)**:一种集成学习方法,通过构建多个决策树并取其平均结果,提高预测准确性,H2O中的随机森林可用于特征选择和分类/回归任务。
- **梯度Boosting**:这是一种迭代提升方法,通过不断优化弱学习器来构建强学习器,H2O提供了GBM(Gradient Boosted Machines)算法,用于处理回归和分类问题。
4. **模型评估**:对构建的模型进行性能评估,文章可能涉及到计算ROC曲线(Receiver Operating Characteristic Curve)和AUC值(Area Under the Curve),这两个指标在二分类问题中用于衡量模型的区分性能。
5. **模型选择**:根据ROC和AUC的比较,选择表现最佳的模型作为最终预测模型。通常,AUC值越高,模型性能越好,但具体选择还需结合业务需求和实际问题特性。
6. **潜在的数据处理**:由于`mclust`的引入,文中可能还包括了对数据进行聚类分析,帮助理解数据分布和潜在结构,以进一步优化特征工程和模型性能。
通过这个实例,作者展示了如何利用H2O库在R环境中进行深入的价格预测分析,从数据预处理到模型选择,全面展示了机器学习建模的流程。这对于R用户来说,是一篇实用且具有指导意义的技术文章。
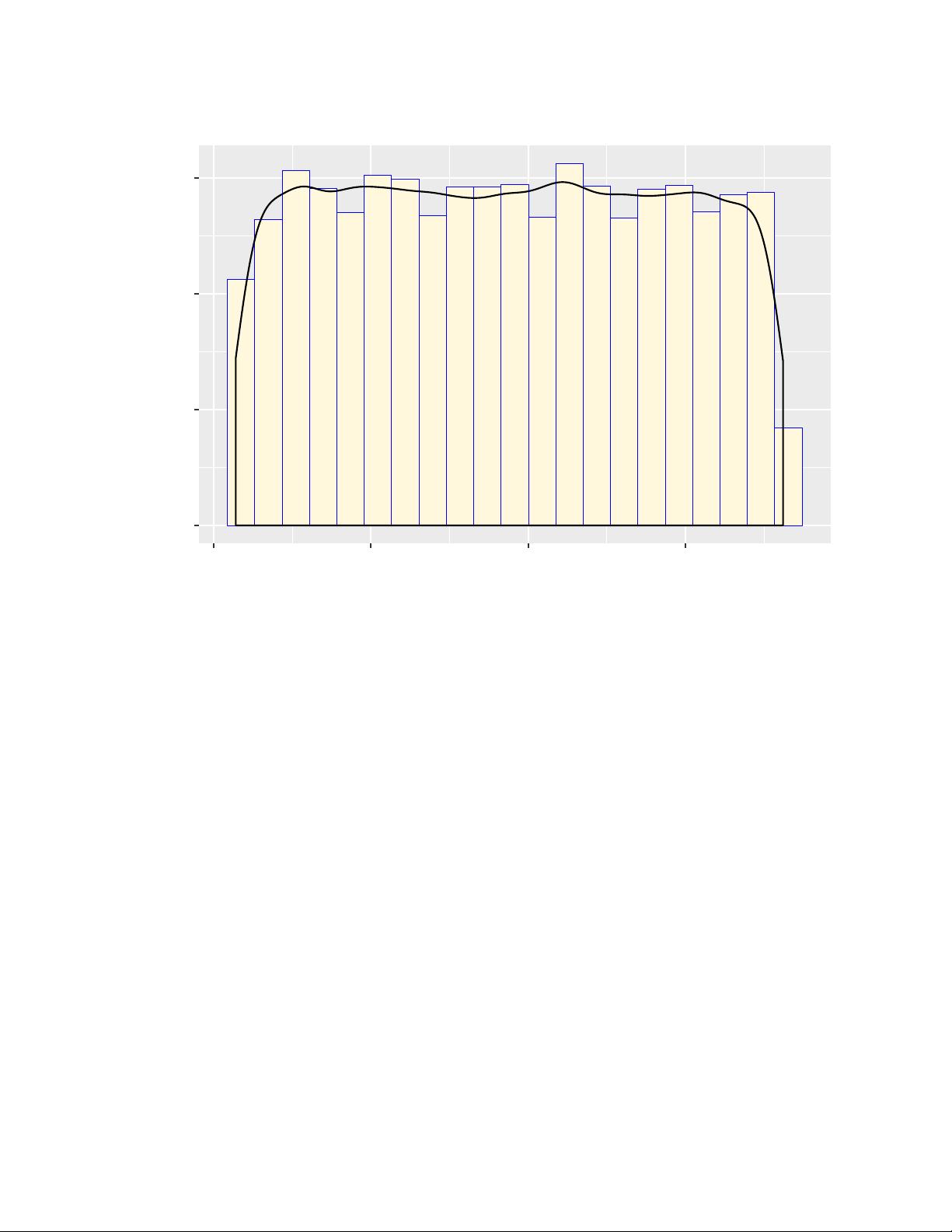
0.000
0.002
0.004
0.006
0
50
100
150
nvisits
density
The distribution of nvisits
## Variable : land_size
7
剩余33页未读,继续阅读
2019-02-23 上传
2015-08-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

风的芸芸
- 粉丝: 19
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Study-Circle:这个跨平台的应用程序是使用Flutter制作的,它可能会起到连接社会学习和共同成长的作用
- 一个简易的智能聊天机器人系统.zip
- MiniChickenFolkloric:TCC-UFAM 2020
- matlab心线代码-Multi-Agent-Navigation:多个代理的免费导航
- Whereby-crx插件
- Windows-NT-Native-API.zip_Windows编程_C/C++_
- the-white-rabbit:White Rabbit是基于Kotlin协程的异步RabbitMQ(AMQP)客户端
- 2Ring Extension for Cisco Finesse v4.1.1-crx插件
- 下一个示例会计笔记本
- Design_Park.rar_CAD_Windows_Unix_
- 瑞金医院MMC人工智能辅助构建知识图谱大赛.zip
- skillfactory
- 课程设计之基于HTML+CSS的网页设计.rar
- jokeapp:Spring5Framwork开玩笑的应用程序
- Monster Cards-crx插件
- 完全以SwiftUI编写的带有滑动手势的入门/滑动器。-Swift开发
