Python链表解析:变量标识本质与链表操作
需积分: 0 17 浏览量
更新于2024-08-29
收藏 445KB PDF 举报
本文主要介绍了Python中的链表数据结构以及Python变量的本质,通过实例展示了链表的创建、遍历和添加操作。
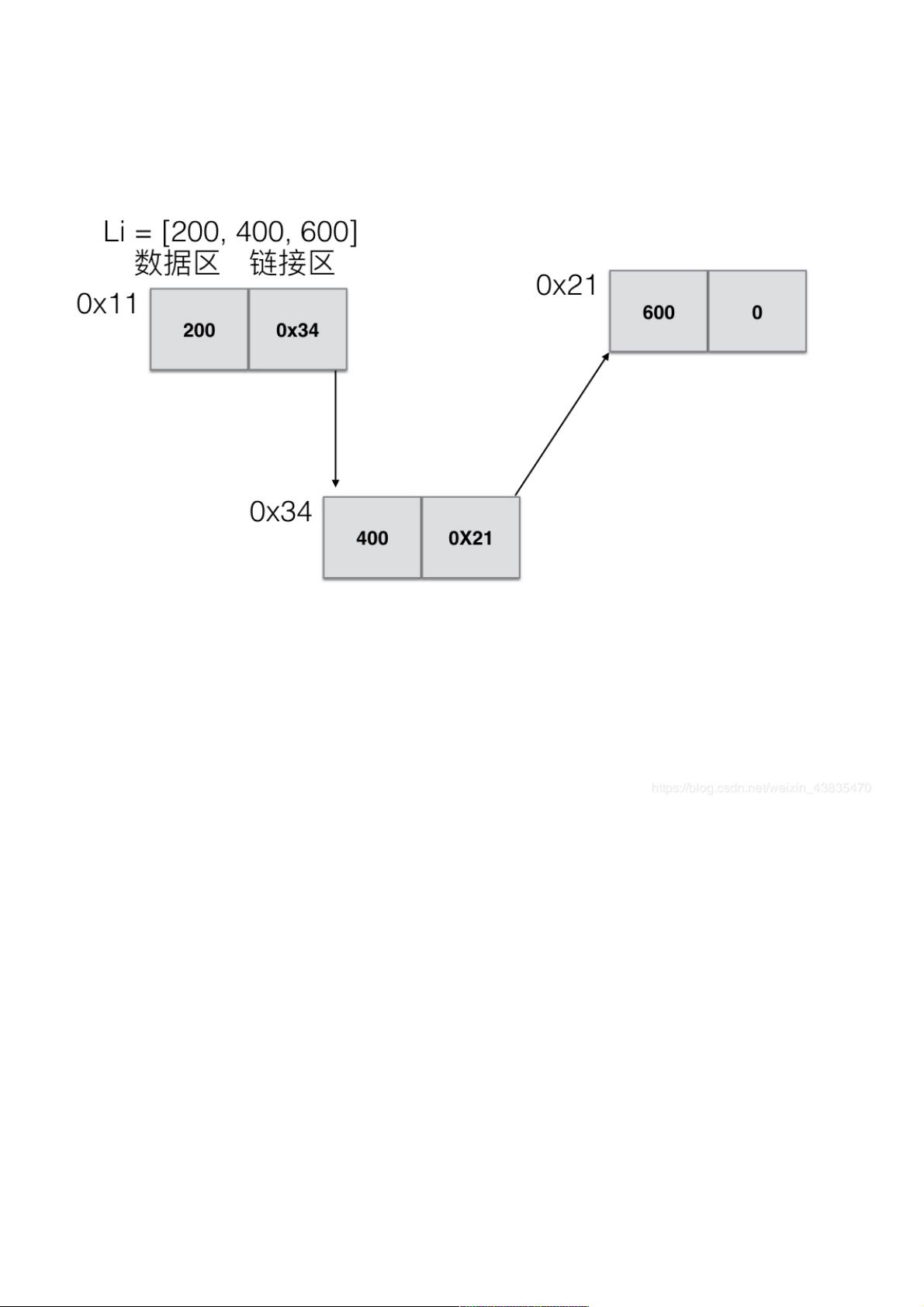
在Python中,链表是一种重要的数据结构,它不同于数组,数组中元素在内存中是连续存储的,而链表的每个元素(节点)由两部分组成:数据区和链接区。数据区存储实际的数据,链接区存储指向下一个节点的引用。由于Python不直接支持指针操作,因此在实现链表时,我们通常使用对象的引用来模拟链接区的功能。
Python变量的实质并不像C++或Java等语言中的指针那样直接存储内存地址。当我们声明`a = 10`时,`a`并不是10的内存地址,而是一个指向存储10的内存位置的引用。这意味着,当我们改变`a`的值,例如`a = 20`,实际上是改变了`a`引用的内存位置,而不是直接修改了`a`本身。这种机制使得Python中的变量赋值和对象引用变得相对简单,同时也使得链表的实现有了可能。
在Python中实现链表,通常会定义一个Node类来表示链表的节点,包含数据和指向下一个节点的引用。然后定义一个链表类,其中包含一个指向链表头节点的属性。例如:
```python
class Node:
def __init__(self, elem):
self.elem = elem
self.next = None
class SingleLinkList:
def __init__(self, node=None):
self._head = node # 私有属性,用于指向链表的第一个节点
def is_empty(self):
return self._head == None
def length(self):
cur = self._head # 游标,用于遍历节点
count = 0
while cur != None:
count += 1
cur = cur.next
return count
```
在这个例子中,`SingleLinkList`类的`_head`属性用于存储链表的第一个节点。`is_empty`方法检查链表是否为空,`length`方法通过遍历链表计算其长度。在实际操作链表时,还可以实现插入、删除等方法。
链表操作的关键在于理解节点之间的引用关系。例如,要在一个链表尾部添加新节点,我们需要遍历到链表的最后一个节点,然后将该节点的`next`属性设置为新节点。如果要在指定位置插入节点,需要找到插入点的前一个节点,更新它的`next`属性。
总结起来,Python中的链表操作虽然不直接涉及内存地址,但通过对象引用可以实现链式结构。理解Python变量的本质有助于更好地理解和实现链表这样的数据结构。
【【Python学习】【数据结构】之链表(学习】【数据结构】之链表(python变量标识本质、链表操变量标识本质、链表操
作)作)
【【Python学习】【数据结构】之链表(学习】【数据结构】之链表(python变量标识本质、链表操作)变量标识本质、链表操作)链表Python变量标识本质链表操作
链表链表
一个简单的链表形式如下:
一个节点分为数据区和链接区,数据区存储数据好说,而链接区需要的是存储地址,Python没有加*即表示变量的存储地址的操作,那么如何表示
链接区指向下一个节点的地址呢?
Python变量标识本质变量标识本质
下载后可阅读完整内容,剩余5页未读,立即下载
2018-11-30 上传
2021-08-20 上传
点击了解资源详情
2020-12-25 上传
2020-09-19 上传
2021-01-20 上传
2021-01-21 上传
2023-09-13 上传
2020-09-21 上传

weixin_38743391
- 粉丝: 9
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- 几乎所有的findIndex练习:Springboard软件工程职业生涯跟踪子单元8.2的练习
- pyg_lib-0.2.0+pt20cpu-cp310-cp310-linux_x86_64whl.zip
- Gravity-Game
- LiveCue-开源
- shield-db::shield_selector:Shield DB,Dot Shield使用的广告和跟踪器的数据库
- swift-boilerplate:使用文件和项目模板节省创建Swift应用程序的时间
- espriturc:预订土耳其语课程的网站
- ANNOgesic-0.7.29-py3-none-any.whl.zip
- angular-remove-diacritics:角度服务可消除字符串中的重音符号
- 减去图像均值matlab代码-PCA-Image-Compression:PCA-图像压缩
- test-msw
- chipster-web
- smart-contract-tutorial:该存储库包含我们的文章https中使用的完整代码
- xderm-mini
- Inventory_management:Etsy小型企业的库存管理
- HFTuner:免提吉他调音器!
