SHARK:大数据开发平台架构与实战揭秘
需积分: 15 181 浏览量
更新于2024-07-09
1
收藏 4.34MB PDF 举报
本文档深入探讨了大数据开发平台的架构与实践经验,以一点资讯为例,该公司的DAU达到7000万,展示了在大数据领域的广泛应用和复杂性。平台的核心特点是基于大数据的生命周期管理,涵盖了数据的采集(Dump)、实时计算、血缘关系管理以及数据调度系统的构建。关键组件包括:
1. **数据采集与实时计算**:通过Kafka实现数据的高效传输和实时处理,支持高吞吐量的实时流处理。
2. **元数据管理**:元数据子系统对于数据的结构和关系至关重要,确保数据的一致性和可理解性,如Kafka元数据和PALO等工具的使用。
3. **查询引擎**:用于执行数据分析和查询任务,可能是基于Hive或自研的查询系统,确保数据的快速检索和分析。
4. **数据质量和血缘关系**:平台设有数据质量巡检平台,关注数据的完整性和准确性,同时血缘关系管理有助于追踪数据的来源和演变。
5. **离线计算**:Hadoop和HBase等技术用于大规模数据的批处理和存储,如HDFS和YARN作为核心分布式计算框架。
6. **存储系统**:除了HDFS,还有自研的Lynx存储平台和PaloDB等高性能数据库,满足不同场景的数据存储需求。
7. **容器化部署**:采用Mesos和Kubernetes (K8s)进行容器化管理,提升资源利用率和灵活性。
8. **实时计算平台**:如Storm和Flink,用于处理实时数据流,实现低延迟的数据处理。
9. **机器学习和数据分析**:提供机器学习平台,支持多维分析和OLAP,如Lynx存储平台和数据分析工具。
10. **用户画像与服务**:通过人机结合,创建用户画像平台,个性化推送“有趣更有用”的内容。
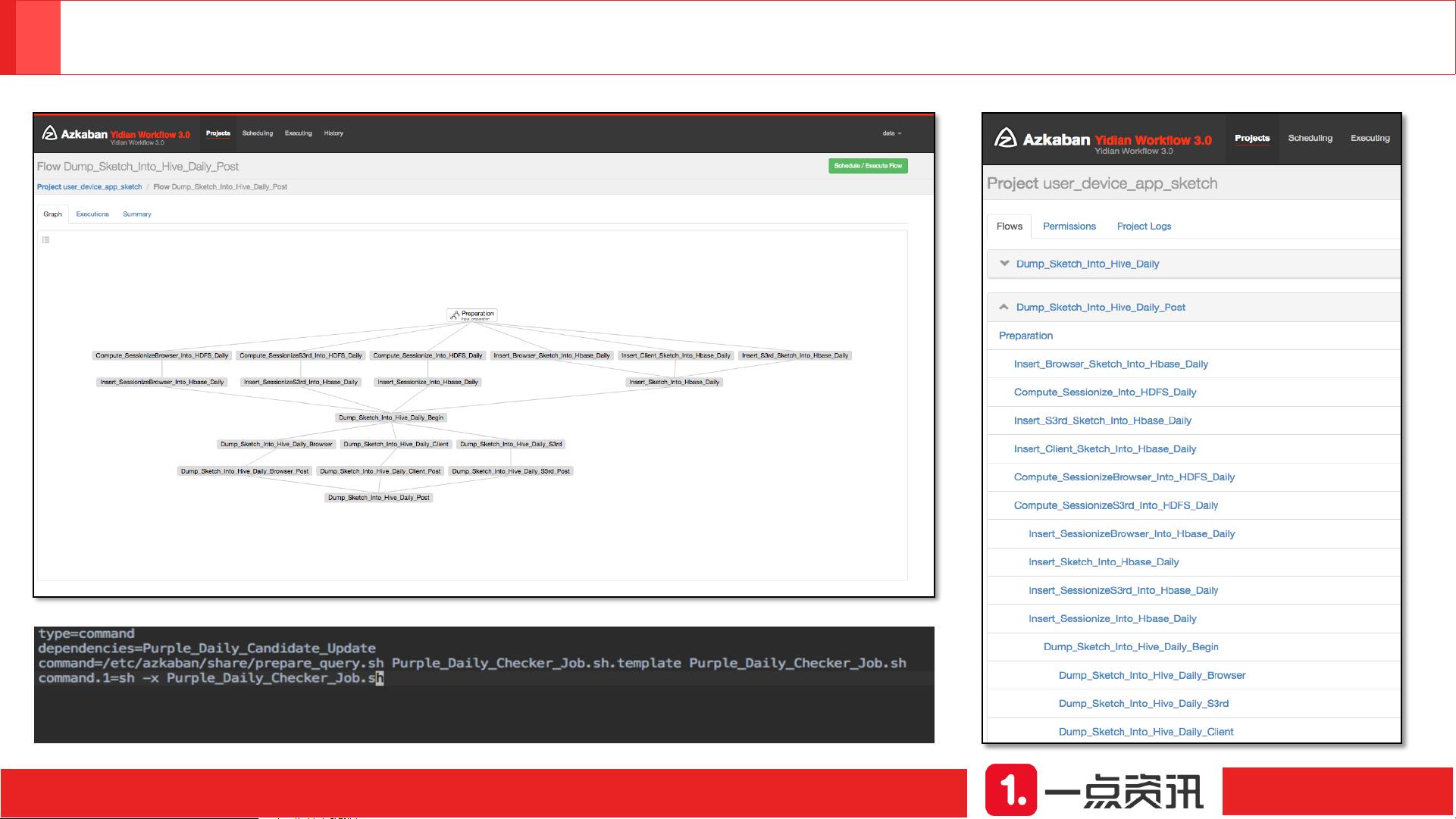
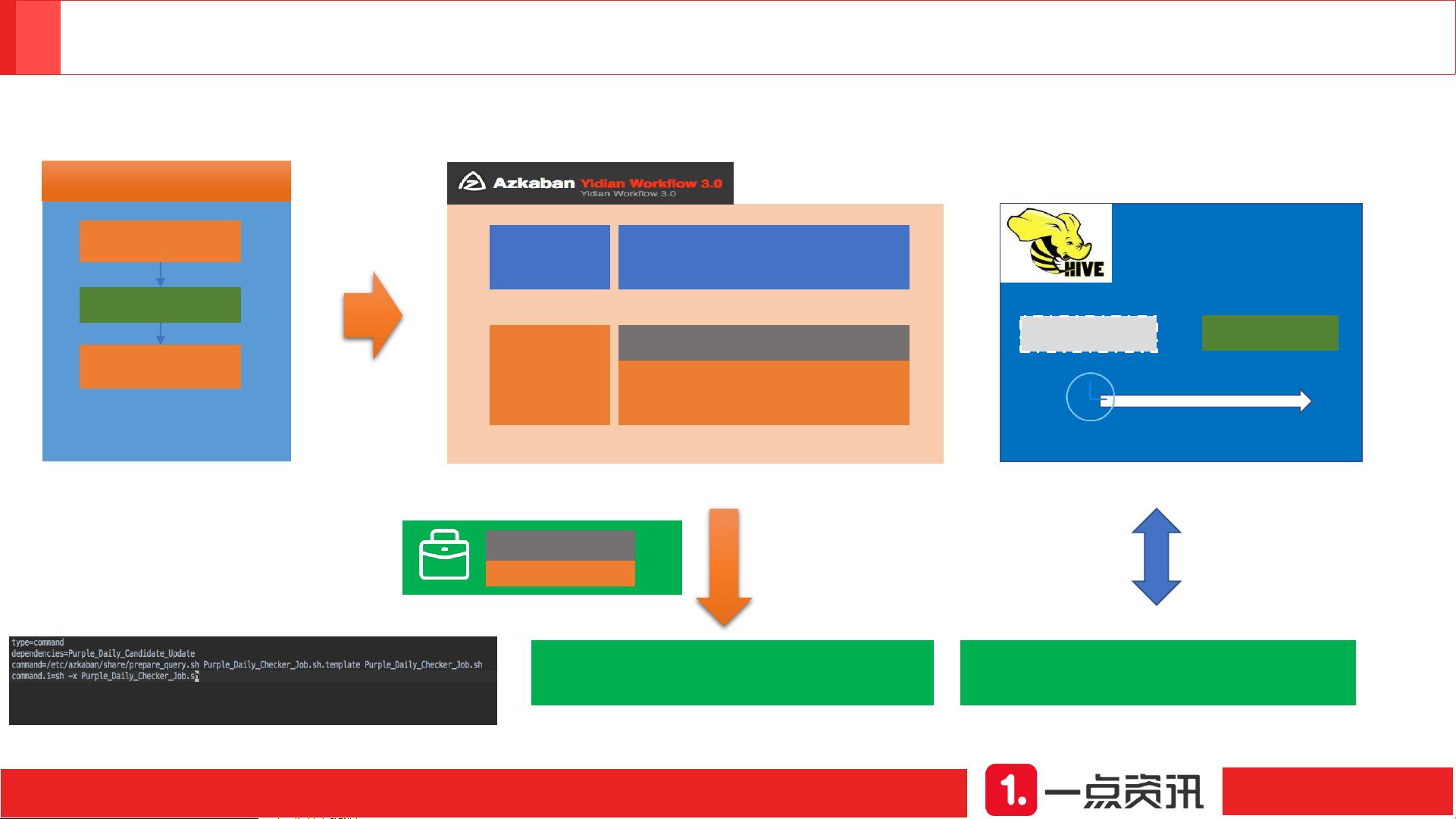
11. **系统扩展与管理**:AzkabanExecutor用于任务调度,依赖于HDFS、YARN等技术实现作业管理和高可用性,如跨Project和跨集群依赖处理,以及数据库主从复制等。
12. **Azkaban扩展**:对Azkaban工作流管理系统进行优化和改造,提升作业的自动化和可靠性,包括作业提交、管理、故障处理等功能。
整个平台规模庞大,拥有超过1200个项目、2300个流水线和1500个数据表,数据量达到30PB至42PB,日增量高达300TB以上。这样的架构和实践不仅适用于大型企业,也为其他组织提供了宝贵的学习参考,展示了大数据开发平台如何在实际环境中应对海量数据和复杂业务场景。

点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-03-18 上传
2021-07-04 上传
2021-07-04 上传
2021-10-14 上传
2021-10-13 上传
2021-10-14 上传

xiaoSUM
- 粉丝: 6
- 资源: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- CSS+DIV常用方法说明
- 《深入浅出Ext+JS》样章.pdf
- sudo应用的详细阐述
- sql金典.pdf sql金典.pdf
- tomcat配置手册
- webwork开发指南
- Ajax In Action 中文版
- 数据挖掘论文.。。。。
- Visual Studio 2008 可扩展性开发4:添加新的命令.doc
- Visual Studio 2008 可扩展性开发3:Add-In运行机制解析(下).doc
- Visual Studio 2008 可扩展性开发3:Add-In运行机制解析(上).doc
- 蚁群分区算法C#实现
- Visual Studio 2008 可扩展性开发2:Macro和Add-In初探
- C、C++高质量编程指导
- BIND9 管理员参考手册
- MiniGUI用户手册
