Hive进阶教程:Thrift服务与数据存储格式解析
需积分: 50 35 浏览量
更新于2024-09-08
1
收藏 161KB DOCX 举报
“Hive进阶强化必备:包括Hive Thrift服务启动、数据存储格式、导入数据方式、面试SQL及MySQL应用”
在Hive进阶强化学习中,掌握Hive Thrift服务的启动和管理是至关重要的。Thrift服务允许远程客户端如Beeline连接到Hive服务器执行查询。在Hadoop01节点上,可以通过以下两种方式启动Hive Thrift服务:
1. 启动为前台服务:`bin/hiveserver2`
2. 启动为后台服务:`nohup bin/hiveserver2 > /var/log/hiveserver.log 2> /var/log/hiveserver.err &`
一旦服务启动,其他节点可以通过Beeline连接。有两种连接方法:
- 直接进入Beeline:`hive/bin/beeline`,然后在Beeline命令行中输入`!connect jdbc:hive2://huawei:10000`
- 启动时连接:`bin/beeline -u jdbc:hive2://huawei:10000 -n hadoop`
Hive支持多种数据存储格式,每种格式有其特定用途:
1. TextFile:这是Hive的默认格式,不压缩数据,导致磁盘空间占用大且解析数据时开销较高。可以结合Gzip或Bzip2等压缩格式使用,但这样会导致Hive无法自动切分数据进行并行处理。创建表时指定`stored as textfile`。
2. SequenceFile:这是一种二进制文件格式,便于使用,可分割,且支持压缩。推荐使用BLOCK级别的压缩,因为Record压缩效率较低。启用输出压缩和设置Gzip压缩可以通过以下Hive和MapReduce配置实现:
```
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
```
了解Hive的ETL(提取、转换、加载)过程也是提升Hive技能的关键,这涉及到数据清洗、转换和加载到Hive表的过程。
在面试中,掌握一些SQL套路可以帮助你在技术面试中脱颖而出。例如,了解如何处理分区表以及如何优化查询性能是非常实用的技巧。
在MySQL方面,熟悉基本的数据库操作和建表是基础。比如创建历史信息表、进行表的常用操作,以及解决中文乱码问题。在给出的示例中,有查询非985大学学生信息的需求,通过分析思路和SQL语句可以实现这一目标。
在实际项目中,了解如何根据业务需求设计表结构,如School表和Stu02表,可以帮助你更好地处理和组织数据。例如,分析需求,使用合适的分隔符(如`\u0001`),选择适合的数据存储格式,都是确保数据管理和查询效率的关键。
Hive的进阶强化涉及多个方面,包括服务管理、数据存储、ETL、SQL查询和MySQL操作,这些都需要深入理解和实践,以提升在大数据处理中的专业能力。
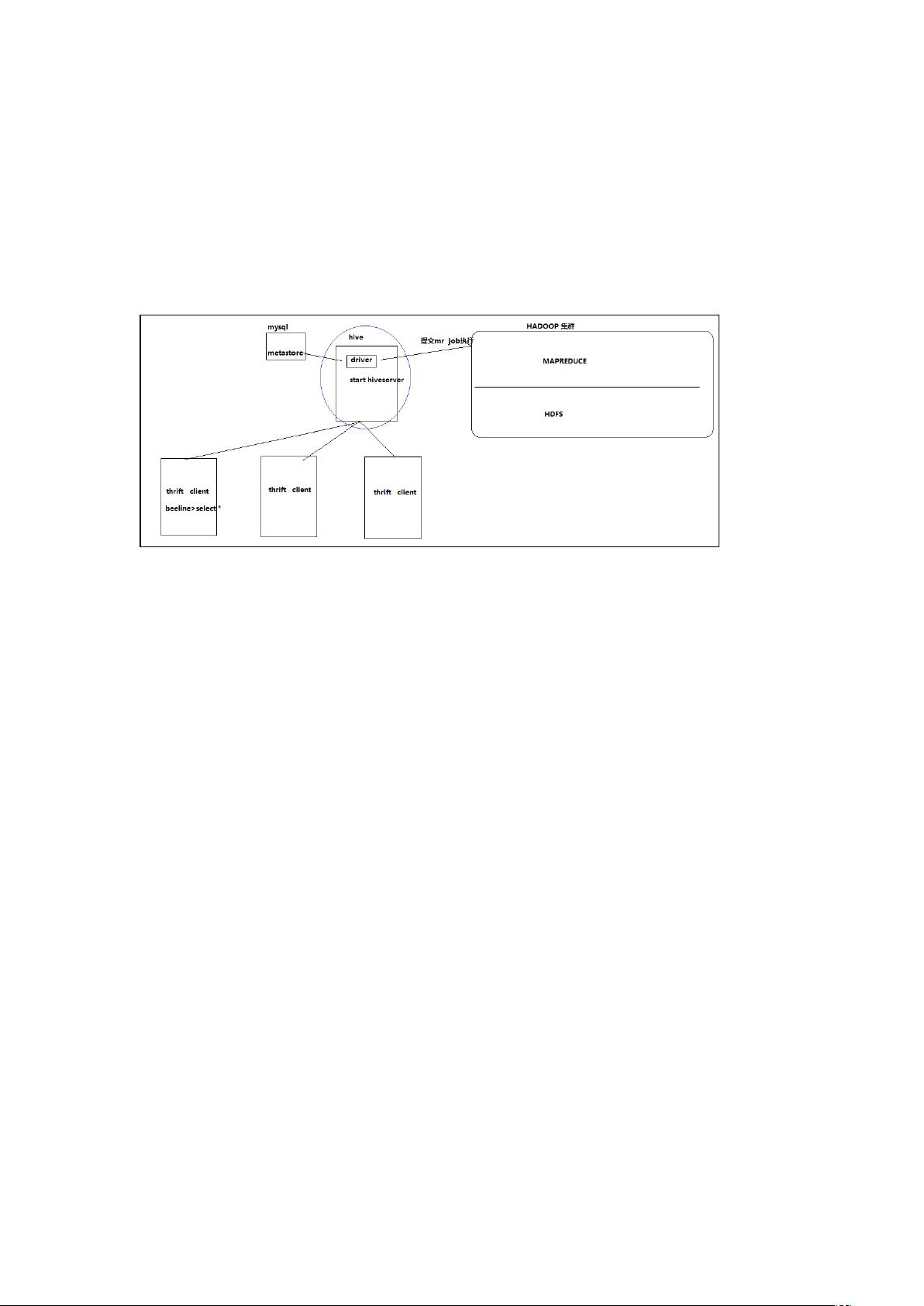
Hive
1. Hive thrift 服务
启动方式,(假如是在 上):
启动为前台:
启动为后台:
启动成功后,可以在别的节点上用 去连接
方式()
回车,进入 的命令界面
输入命令连接
( 是 所启动的那台主机名,端口默认是 )
方式()
或者启动就连接:
接下来就可以做正常 查询了
2. Hive 几种存储数据的格式
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
1015 浏览量
1664 浏览量
138 浏览量
2021-10-14 上传
2021-10-14 上传

linke1183982890
- 粉丝: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 经典J2ME坦克对战游戏:回顾与介绍
- ZAProxy自动化工具集合:提升Web安全测试效率
- 破解Steel Belted Radius 5.3安全验证工具
- Python实现的德文惠斯特游戏—开源项目
- 聚客下载系统:体验极速下载的革命
- 重力与滑动弹球封装的Swift动画库实现
- C语言控制P0口LED点亮状态教程及源码
- VB6中使用SQLite实现列表查询的示例教程
- CMSearch:在CraftMania服务器上快速搜索玩家的Web应用
- 在VB.net中实现Code128条形码绘制教程
- Java SE Swing入门实例分析
- Java编程语言设计课程:自动机的构建与最小化算法实现
- SI9000阻抗计算软件:硬件工程师的高频信号分析利器
- 三大框架整合教程:S2SH初学者快速入门
- PHP后台管理自动化生成工具的使用与资源分享
- C#开发的多线程控制台贪吃蛇游戏源码解析
