理解主题模型:LDA与文本分析
需积分: 10 166 浏览量
更新于2024-07-18
收藏 1.33MB PPT 举报
"主题模型ppt学习"
主题模型是自然语言处理领域的一种重要算法,主要用于揭示文本数据背后的隐藏主题。这一概念由Blei等人在2003年提出的隐性狄里克雷分配(Latent Dirichlet Allocation, LDA)中正式引入。主题模型的核心思想是通过对文本中的词频进行建模,找出文本中潜在的主题结构。
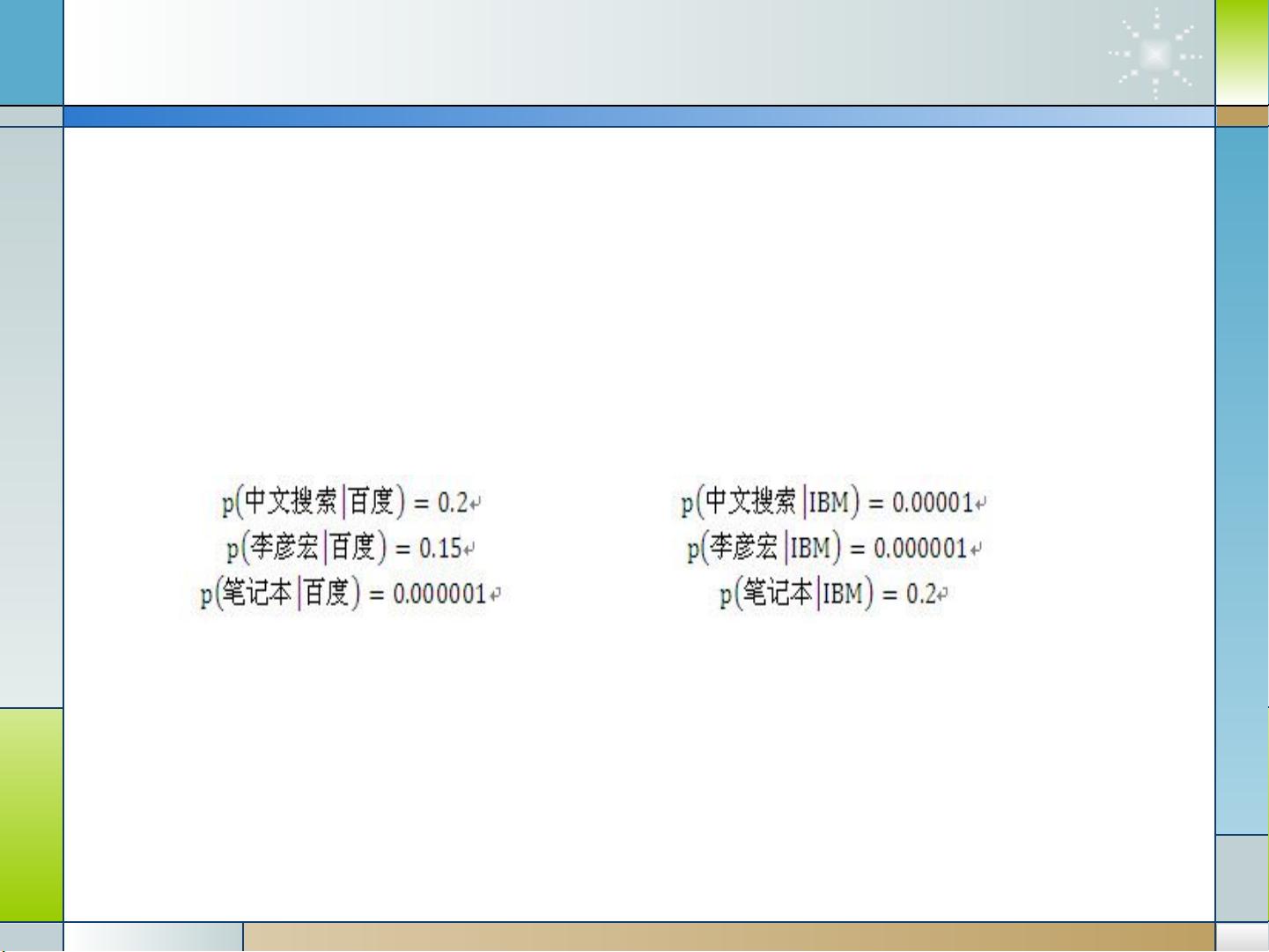
首先,我们要明确什么是主题。主题并非单一的词汇,而是一系列相关词汇的集合,它代表了一篇文章、一段话或者一个句子的中心思想。例如,如果一个文档涉及到“百度”这个主题,那么与之关联的词汇如“中文搜索”、“李彦宏”等可能会频繁出现。主题可以用词汇表上词语的条件概率分布来描述,即与主题密切相关的词语在该主题下出现的概率较高。
主题模型旨在解决两个主要问题:一是如何从文本中提取这些隐藏的主题,二是如何对文章中的主题进行分析和理解。为了实现这一目标,主题模型采用了生成模型的思路。这意味着我们假设每个文档的生成过程是由一系列主题随机选择并决定文档中词语的出现概率。具体来说,每篇文章中的每个词都是先随机选择一个主题,然后从该主题的词频分布中随机选取一个词来生成的。
在数学表达上,文档中每个词的出现概率可以表示为文档-主题分布和主题-词语分布的乘积。这种表示方式可以通过矩阵运算来简化,其中“文档-词语”矩阵表示每个文档中每个单词的词频,即出现的概率;“主题-词语”矩阵描述每个主题中每个单词的出现概率;而“文档-主题”矩阵则表示每个文档中每个主题的相对权重,反映了文档内部主题的混合比例。
主题模型的应用广泛,包括信息检索、文档分类、推荐系统、社区发现等多个领域。通过理解文本数据的主题结构,我们可以更有效地提取关键信息,进行文本摘要,甚至预测用户兴趣。然而,主题模型也存在挑战,如主题解释的模糊性、模型参数的选择以及计算效率等问题,这需要在实际应用中不断优化和改进。主题模型是理解和挖掘大规模文本数据的重要工具,对于信息处理和分析具有深远的影响。
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-05 上传
2021-10-08 上传
2021-10-11 上传
2021-10-05 上传
2021-10-07 上传
2021-10-03 上传

渣渣的坚持
- 粉丝: 2
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- CSS+DIV常用方法说明
- 《深入浅出Ext+JS》样章.pdf
- sudo应用的详细阐述
- sql金典.pdf sql金典.pdf
- tomcat配置手册
- webwork开发指南
- Ajax In Action 中文版
- 数据挖掘论文.。。。。
- Visual Studio 2008 可扩展性开发4:添加新的命令.doc
- Visual Studio 2008 可扩展性开发3:Add-In运行机制解析(下).doc
- Visual Studio 2008 可扩展性开发3:Add-In运行机制解析(上).doc
- 蚁群分区算法C#实现
- Visual Studio 2008 可扩展性开发2:Macro和Add-In初探
- C、C++高质量编程指导
- BIND9 管理员参考手册
- MiniGUI用户手册
