Python实现高斯判别分析:多元正态分布与GDA算法详解
16 浏览量
更新于2024-08-30
收藏 431KB PDF 举报
高斯判别分析算法(GDA)是一种在统计学和机器学习中广泛应用的分类方法,它属于生成学习的一种。在Python中实现该算法时,我们基于以下核心概念:
1. 多元正态分布:算法的核心假设是,给定类别y,输入数据X服从多元正态分布,即每个样本点X的每个特征独立地服从均值μ和协方差矩阵Σ的正态分布。多元正态分布有两个关键参数:μ(均值向量,每个维度的期望值)和Σ(协方差矩阵,衡量不同特征之间的线性相关性)。
2. 协方差矩阵:它是衡量随机变量之间关系的重要工具,定义为列向量X的期望值E(X)的偏差的平方和。协方差矩阵Σ是正定的,确保了分布的唯一性。Σ的大小和结构会影响数据点在高维空间中的分布形状,如标准正态分布(Σ=I,单位矩阵)表示所有特征间相互独立,而Σ变大或变小则会改变数据的集中程度。
3. 判别学习与生成学习:GDA属于判别学习,与之相对的是生成学习,后者假设p(y|x)(类别给定特征的概率)是易于建模的,而GDA则假设p(x|y)(特征给定类别的概率)更为直观。
4. 似然函数:算法的目标是最大化似然函数L,通过估计μ和Σ来找到最佳的分类决策边界。这通常通过求解优化问题来完成,涉及到计算梯度并更新参数。
5. Python实现:在实际编程中,例如使用Python,可能需要通过numpy库来处理矩阵运算,计算概率密度函数。但代码实现可能存在错误,比如矩阵操作不正确,特别是在处理二维数据时简化公式。通过可视化,我们可以直观地理解算法如何将不同协方差矩阵对应的高斯分布应用于分类任务。
在实践中,GDA可以用于降维、特征选择和分类,尤其是在处理连续型输入数据时。通过理解并应用这些原理,开发者可以在Python中构建并调试高斯判别分析模型,以解决实际问题。
python实现高斯判别分析算法的例子实现高斯判别分析算法的例子
高斯判别分析算法(高斯判别分析算法(Gaussian discriminat analysis))
高斯判别算法是一个典型的生成学习算法(关于生成学习算法可以参考我的另外一篇博客)。在这个算法中,我们假设p(x|y)p(x|y)服从多
元正态分布。
注:在判别学习算法中,我们假设p(y|x)p(y|x)服从一维正态分布,这个很好类比,因为在模型中输入数据XX通常是拥有很多维度的,所
以对于XX的条件概率建模时要取多维正态分布。
多元正态分布多元正态分布
多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量μ∈Rnμ∈Rn和一个协方差矩阵∑∈Rn×n∑∈Rn×n
关于协方差矩阵的定义;假设XX是由nn个标量随机变量组成的列向量,并且μkμk是第kk个元素的期望值,即μk=E(Xk)μk=E(Xk),那么协
方差矩阵被定义为
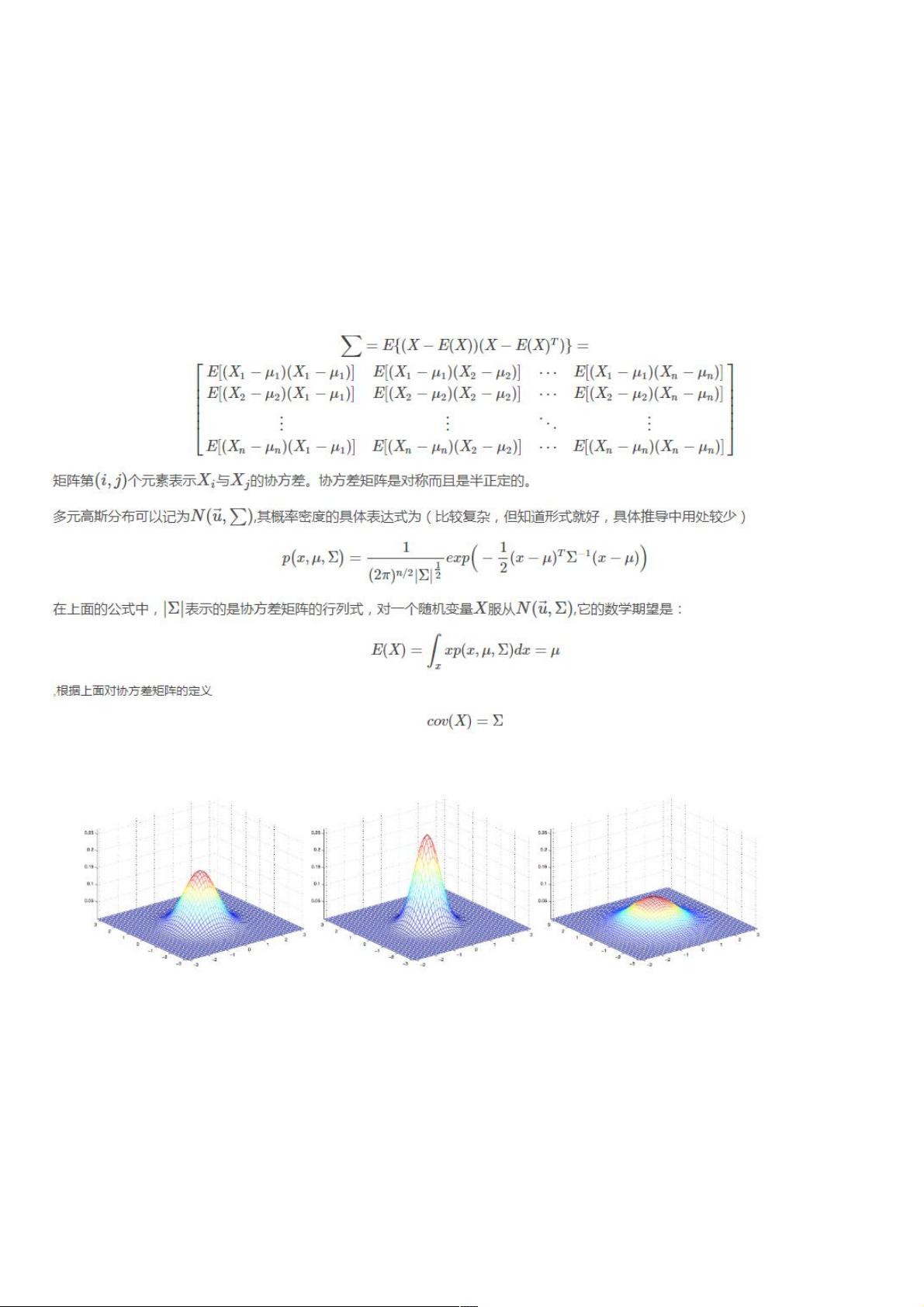
下面是一些二维高斯分布的概率密度图像:下面是一些二维高斯分布的概率密度图像:
最右边的图像展现的二维高斯分布的均值是零向量(2×1的零向量),协方差矩阵Σ=IΣ=I(2×2的单位矩阵),像这样以零向量为均值以单位
阵为协方差的多维高斯分布称为标准正态分布,中间的图像以零向量为均值,Σ=0.6IΣ=0.6I;最右边的图像中Σ=2IΣ=2I,观察发现当ΣΣ越
大时,高斯分布越“铺开”,当ΣΣ越小时,高斯分布越“收缩”。
让我们看一些其他例子对比发现规律让我们看一些其他例子对比发现规律
下载后可阅读完整内容,剩余5页未读,立即下载
2019-04-29 上传
2018-08-08 上传
2023-09-29 上传
2024-03-17 上传
2023-09-25 上传
2023-06-03 上传
2023-06-02 上传
2023-09-01 上传

weixin_38550334
- 粉丝: 2
- 资源: 952
 我的内容管理
展开
我的内容管理
展开







最新资源
- CAD使用中可能碰到的49种小问题(1-33)
- oracle+SQL语法大全
- principles of model checking
- Java Persistence with Hibernate 2007(英文版)
- flex 和 java项目 整合.pdf
- 流行学习包含等距离映射和局部线性嵌入法
- ARCGIS二次开发实例教程
- zigbee在网络交流的应用
- ArcXML基于INTERNET的空间数据描述语言
- 黑盒测试教程(教你什么叫黑盒测试,系统测试)
- androd设计高级教程
- 交流信号真有效值数字测量方法
- 常用算法设计方法+搜集.doc
- Linux1.0核心游记
- eclips pdf 电子书
- oracle 游标入门
