Hadoop WordCount Eclipse打包与部署教程
需积分: 11 25 浏览量
更新于2024-09-13
收藏 138KB DOC 举报
在Hadoop环境下,WordCount是经典的MapReduce示例程序,它用于计算文本文件中单词的频率。本文档主要讲解如何在Eclipse中编译和打包WordCount程序,以便于在Hadoop集群上部署和运行。以下是详细的步骤:
1. **Eclipse打包步骤**:
- 首先,在Eclipse中,选择"File" -> "Export",然后在Java菜单下选择"JAR File"。
- 在弹出的对话框中,点击"Next",指定源项目或者选择包含WordCount代码的Java类文件,设置导出位置并输入jar包的名称,如"Myhadoop.jar"。
- 接着,点击"Next",进入配置选项,这里可以选择包括或排除特定的文件或文件夹,也可以配置构建路径(Build Path)设置。
- 然后,再次点击"Next",确认打包设置,Eclipse会扫描并打包项目的Java类、资源和其他依赖。
2. **发布与执行**:
- 打包完成后,将生成的jar文件放置到Hadoop的可执行目录,通常是"/usr/hadoop"(请根据实际安装路径调整)。确保Hadoop的bin目录在系统路径中,以便通过命令行访问Hadoop工具。
- 使用`Hadoop jar`命令执行WordCount任务,命令格式如下:
```
Hadoopjar <jar包路径> <主类全名> <输入文件路径> <输出文件路径>
```
- 具体示例:
```
Hadoopjar /usr/hadoop/Myhadoop.jar com.hadoop.WordCount hdfs://192.168.20.118:9000/test/test.txt hdfs://192.168.20.118:9000/test/out
```
- 这里,`com.hadoop.WordCount`是主类(通常包含`Mapper`和`Reducer`实现),`test/test.txt`是待处理的文本输入文件,`hdfs://192.168.20.118:9000/test/out`是期望的输出文件路径。
通过这些步骤,你不仅学会了如何在Eclipse中打包Hadoop WordCount程序,还了解了如何将其部署到Hadoop集群中进行分布式计算。请注意,实际操作时可能需要根据Hadoop的版本和配置进行调整。此外,为了保证程序能够正常运行,还需要确保输入文件已经上传到Hadoop分布式文件系统(HDFS),并且Hadoop集群的环境变量和配置已正确设置。
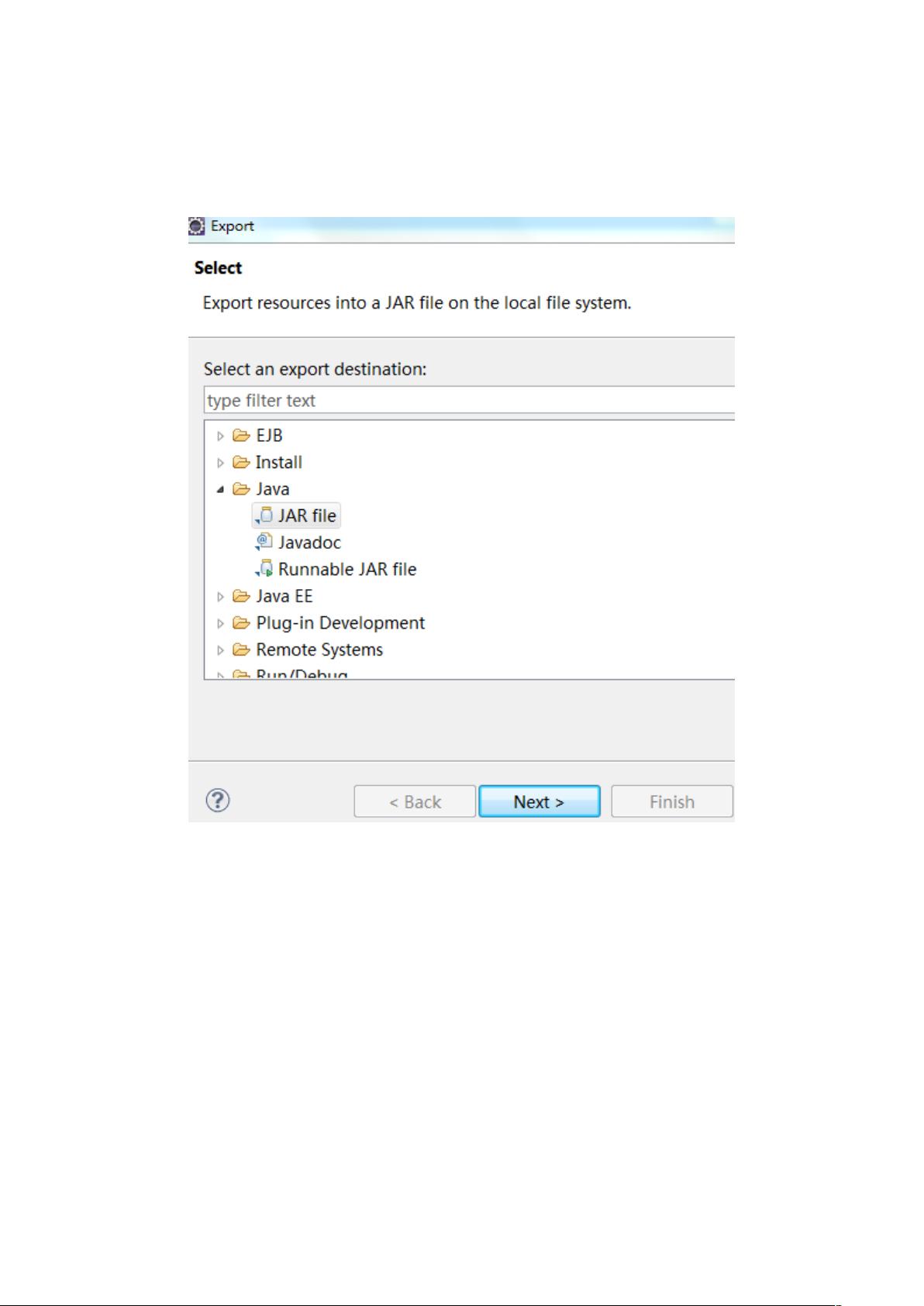
一、Eclipse 打包步骤:
1、Export-->Java-->JAR file,如下图:
2、
点
击
Next
选择导出路径,并制定 jar 包的名字
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-08 上传
2023-06-28 上传
2017-10-14 上传
2024-04-21 上传
2014-08-28 上传
2024-10-25 上传

duan19056
- 粉丝: 20
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
