递归神经网络解析:训练与优化策略探索
167 浏览量
更新于2024-08-27
收藏 377KB PDF 举报
"深入探究递归神经网络:大牛级的训练和优化如何修成?"
递归神经网络(RNN)是深度学习领域中一种特殊的神经网络结构,旨在处理序列数据,如时间序列或文本数据。与传统的前馈神经网络(FNN)相比,RNN通过引入定向循环,使得信息可以在网络中向前和向后传递,从而能够捕捉到序列中的长期依赖关系。
在FNN中,信息从输入层经过隐藏层直接流向输出层,这种单向传播方式限制了网络处理动态变化或序列数据的能力。然而,RNN允许信息在隐藏层内部循环,每个时间步的输出不仅依赖于当前的输入,还依赖于前面时间步的状态,这使得RNN能记忆之前的上下文信息,对序列中的顺序关系进行建模。
RNN的结构包括输入单元、隐藏单元和输出单元。输入单元接收序列数据,隐藏单元负责存储和处理信息,而输出单元根据隐藏单元的状态生成序列的对应输出。隐藏单元的状态在每个时间步都会更新,这个更新过程通常通过一个称为长短期记忆(LSTM)或门控循环单元(GRU)的机制来控制,以解决传统RNN中梯度消失或梯度爆炸的问题。
在训练RNN时,由于存在循环结构,反向传播算法会变得更加复杂。传统的反向传播算法不能有效地处理这种循环结构,导致训练困难。为了解决这个问题,研究人员发展出了诸如教师强制(teacher forcing)、门控机制(gates)以及变种模型,如双向RNN(Bidirectional RNN)和堆叠RNN(Stacked RNN),以增强RNN的学习能力和泛化性能。
优化RNN的过程通常涉及到调整超参数、使用更高级的优化算法(如Adam或RMSprop)、正则化策略(如权重衰减)以及处理序列数据的不同策略,比如截断反向传播(truncated backpropagation through time, BPTT)。此外,为了应对训练中的梯度消失问题,有时会采用更深层次的RNN结构,或者结合注意力机制(Attention Mechanism)来提高模型对序列不同部分的关注程度。
RNN已经在自然语言处理(NLP)、语音识别、机器翻译、音乐生成等多个领域取得了显著的成果。例如,LSTM模型在语言建模和文本生成方面表现出色,能够理解和生成复杂的语言结构。而GRU则因其相对简单的结构和接近LSTM的表现,成为许多应用的首选。
递归神经网络通过其独特的循环结构和一系列优化技术,成为了处理序列数据的强大工具。虽然训练和优化RNN仍面临挑战,但持续的研究和创新正在不断推动这一领域的进步。
深入探究递归神经网络:大牛级的训练和优化如何修成?深入探究递归神经网络:大牛级的训练和优化如何修成?
不同于传统FNN,RNN无需在层面之间构建,同时引入定向循环,能够更好地处理高维度信息的整体逻辑顺序。本文
中,MIT的Nikhil Buduma将带您深入探析RNN的原理、训练和优化等各方面的内容,以及RNN已经获取的一些成就。
在深度学习领域,传统的前馈神经网络(feed-forward neural net,简称FNN)具有出色的表现,取得了许多成功,它
曾在许多不同的任务上——包括手写数字识别和目标分类上创造了记录。甚至到了今天,FNN在解决分类任务上始终
都比其他方法要略胜一筹。
尽管如此,大多数专家还是会达成共识:FNN可以实现的功能仍然相当有限。究其原因,人类的大脑有着惊人的计算
功能,而“分类”任务仅仅是其中很小的一个组成部分。我们不仅能够识别个体案例,更能分析输入信息之间的整体逻辑
序列。这些信息序列富含有大量的内容,信息彼此间有着复杂的时间关联性,并且信息长度各种各样。例如视觉、开
车、演讲还有理解能力,这些都需要我们同时处理高维度的多种输入信息,因为它们时时都在变化,而这是FNN在建
模时就极为匮乏的。
现在的问题在于如何学习信息的逻辑顺序,解决这一问题有一个相当靠谱的途径,那就是递归神经网络(Recurrent
Neural Net,简称RNN)。
RNN是什么?是什么?
RNN建立在与FNN相同的计算单元上,两者之间区别在于:组成这些神经元相互关联的架构有所不同。FNN是建立在
层面之上,其中信息从输入单元向输出单元单向流动,在这些连通模式中并不存在不定向的循环。尽管大脑的神经元
确实在层面之间的连接上包含有不定向循环,我们还是加入了这些限制条件,以牺牲计算的功能性为代价来简化这一
训练过程。因此,为了创建更为强大的计算系统,我们允许RNN打破这些人为设定强加性质的规定:RNN无需在层面无需在层面
之间构建,同时定向循环也会出现之间构建,同时定向循环也会出现。事实上,神经元在实际中是允许彼此相连的。
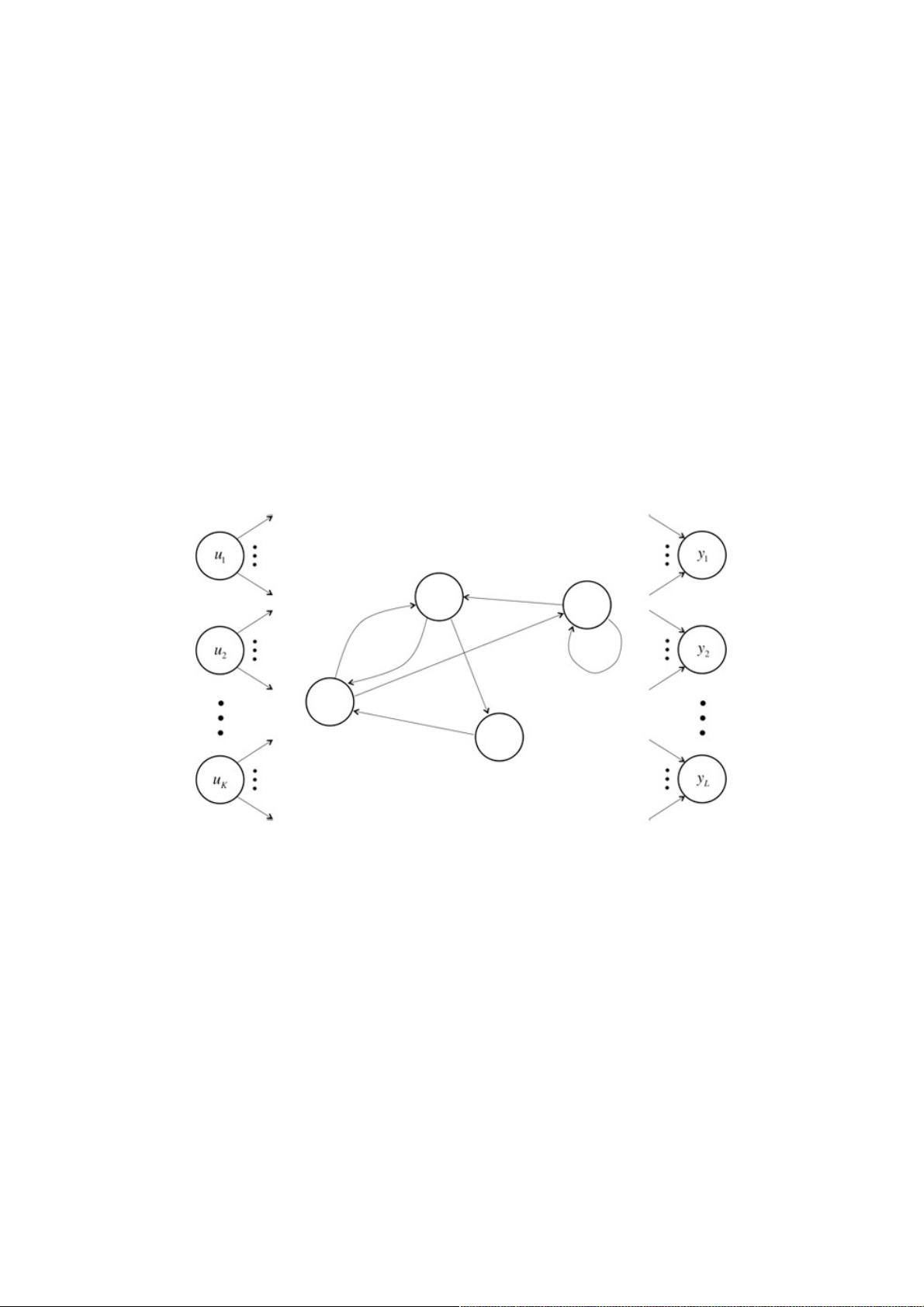
RNN例图,包含直接循环和内部连通
RNN包含输入单元(input units)群,我们将其标记为u1,u2直到uK,而输出单元(output units)群则被标记为
y1,y2直到yL。RNN还包含隐藏单元(hidden units),我们将其标记为x1,x2直到xN,这些隐藏单元完成了最为有
意思的工作。你会发现,在例图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流
动的信息流从隐藏单元到达输出单元。在某些情况下,RNN会打破后者的限制,引导信息从输出单元返回隐藏单元,
这些被称为“backprojections”,不让RNN分析更加复杂。我们在这里讨论的技术同样适用于包含backprojections的
RNN。
训练RNN存在很多相当具有挑战性的难题,而这仍是一个非常活跃的研究领域。了解概念之后,本文将带您深入探析
RNN的原理、训练和优化等各方面的内容,以及RNN已经获取的一些成就。
模拟模拟RNN
现在我们了解到RNN的结构了,可以讨论一下RNN模拟一系列事件的方式。举个简单的例子,下文中的这个RNN的运
作方式类似一个计时器模块,这是由Herbert Jaeger设计的一个经典案例。
下载后可阅读完整内容,剩余9页未读,立即下载
134 浏览量
507 浏览量
1496 浏览量
839 浏览量
314 浏览量
954 浏览量
1177 浏览量
885 浏览量
695 浏览量

weixin_38621897
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微信小程序项目源码分享与解析
- Android中Handler与子线程实现计时方法
- AntiFreeze:永不卡死的高效任务管理器
- DPS系统7.05版本发布:全面升级的统计分析软件
- 记忆卡游戏:HTML制作的互动记忆练习工具
- 易语言实现EXCEL数据与MYSQL数据库交互操作教程
- 掌握数据科学核心技能的哈佛专业证书课程
- C#实现仿Windows记事本功能及特色工具集成
- 全面覆盖BAT Java面试题及详解
- H5音乐播放器模板开发:一站式网页音乐体验
- rcsslogplayer-15.1.0版本发布:全新的日志播放器
- 邮件服务库SendGrid、PostMark、MailGun和Mandrill使用教程
- perseid博客引擎:使用Meteor打造的早期原型
- 创建干净简洁的投资组合网站:mike.lastorbit.co的Jekyll主题指南
- LM2596双路稳压电源设计与完整AD工程资料
- FunPlane打飞机小游戏开发体验分享
