Kafka集群选型与实施策略
需积分: 20 21 浏览量
更新于2024-09-07
收藏 371KB DOCX 举报
"本文主要探讨了Kafka集群的选型方案,包括与其他消息中间件的对比,采用Zookeeper+kafka的集群配置,以及解决消息顺序问题的方法。此外,还介绍了Kafka的一些基本概念,如主题和分区。"
Kafka作为当今流行的消息中间件,其在大数据处理和实时流处理领域具有显著优势。在选型过程中,我们需要对比不同产品的主要指标,如ActiveMQ、RabbitMQ和Kafka。ActiveMQ和RabbitMQ基于AMQP协议,而Kafka则采用自己的设计,它更适合大规模、高吞吐量的场景,且在消息持久化和分布式特性上表现出色。
在Kafka集群方案中,Zookeeper起着关键的角色。Zookeeper是一个分布式协调服务,用于管理Kafka的元数据,例如,它负责集群中服务器的状态管理和负载均衡。当Kafka集群需要动态扩容或减容时,Zookeeper会通知系统进行调整。Zookeeper集群通常按照2*n+1的规则搭建,确保即使有部分节点故障,集群仍能保持半数以上节点存活,继续提供服务。
解决消息顺序问题是Kafka的一个挑战。在Kafka中,Producer可以通过同步发送模式保证消息顺序,但这种方式可能会影响性能。一种常见的做法是根据订单ID进行哈希,将相同订单ID的消息发送到同一分区,从而确保在同一分区内的消息顺序。同时,Consumer按照分区顺序消费消息,通过限制并发线程数量(与分区数量一致)来保证顺序。
Kafka的基本概念包括:
1. 主题(Topic):是消息的分类,每个业务通常对应一个主题,类似于新闻分类。
2. 分区(Partition):是主题下的逻辑单元,消息在分区内部按照FIFO原则存储。分区是Kafka提升性能的关键,增加分区可以提高并行处理能力,同时每个分区由一个Consumer线程单独消费,确保无竞争条件下的顺序性。
Kafka集群方案选型需要考虑系统的扩展性、消息顺序需求以及性能要求。结合Zookeeper的使用,Kafka可以构建出高可用且具备良好性能的消息处理系统。
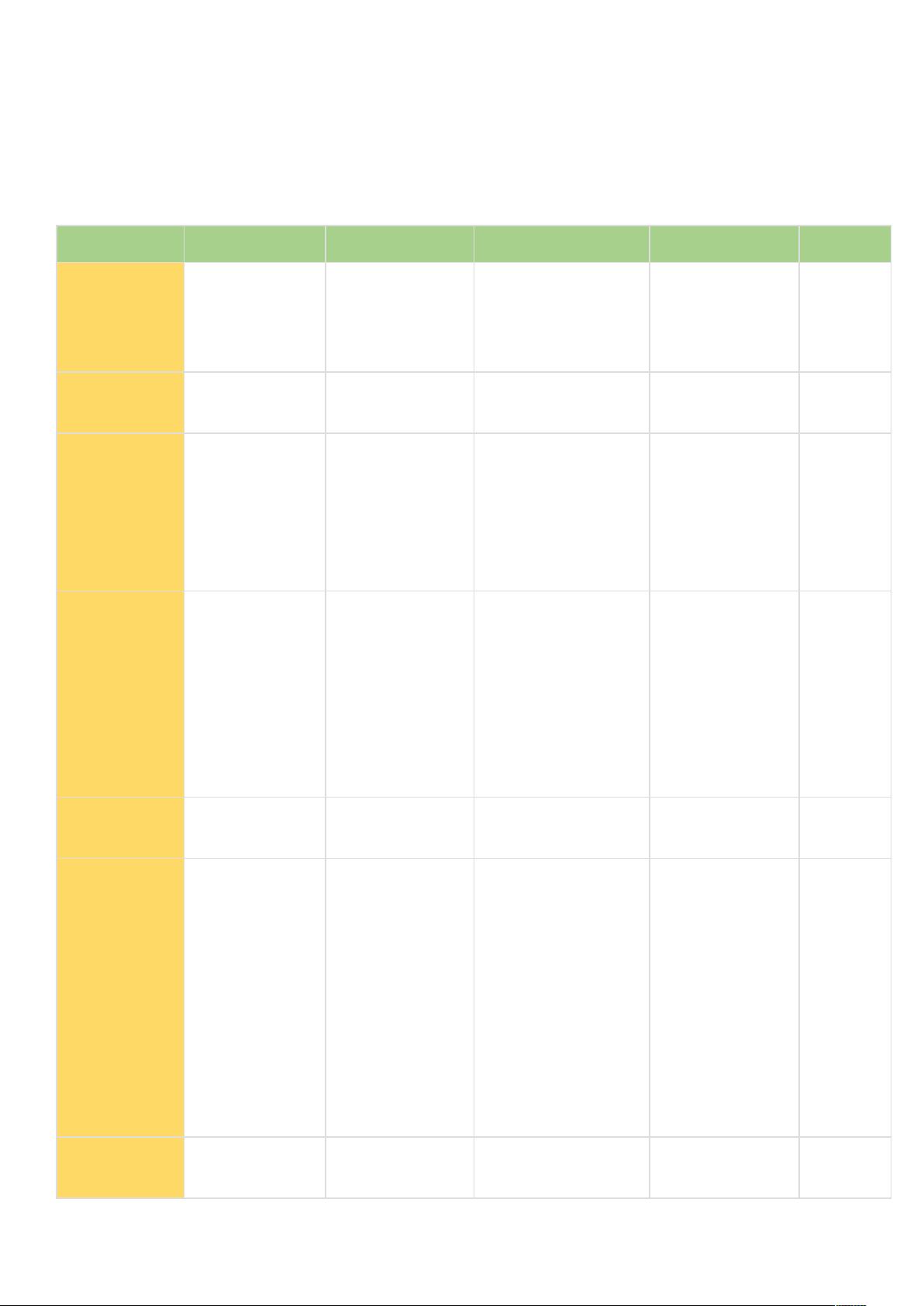
一,当前主流消息中间件产品各项主要指标对比
ActiveMQ RabbitMQ RocketMQ Kafka ZeroMQ
吞吐量 比 RabbitMQ
低
2.6w/s(消息
做持久化)
11.6w/s 17.3w/s 29w/s
开发语言
Java Erlang Java Scala/Java C
主要维护者
Apache Mozilla/Spring Alibaba Apache
iMatix,
创始人
已去世
成熟度 成熟 成熟 开源版本不够成熟 比较成熟 只有
C、PH
P 等版
本成熟
文档和注释 多 多 很少 较少 很少
订阅形式 点对点(p2p)、
广播(发布-订
阅)
提供了 4 种:
direct,
topic ,Headers
和
fanout。fanout
就是广播模式
基于 topic/
messageTag 以及
按照消息类型、属
性进行正则匹配的
发布订阅模式
基于 topic 以及
按照 topic 进行
正则匹配的发
布订阅模式
点对点
(p2p)
持久化 支持少量堆积 支持少量堆积 支持大量堆积 支持大量堆积 不支持
下载后可阅读完整内容,剩余5页未读,立即下载
2019-03-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2015-10-10 上传
2023-03-07 上传
2023-08-07 上传









