谷歌神经机器翻译系统:缩小人类与机器翻译的差距
69 浏览量
更新于2024-07-14
收藏 1.6MB PDF 举报
"Google在2016年发布了一篇名为'Google's Neural Machine Translation System - Bridging the Gap between Human and Machine Translation'的研究论文,该论文由Yonghui Wu, Mike Schuster, Zhifeng Chen等多位谷歌研究人员共同撰写。论文主要探讨了谷歌的神经机器翻译系统(Neural Machine Translation, NMT),旨在缩小人类翻译与机器翻译之间的差距。NMT是一种端到端的学习方法,旨在自动化翻译,并有望克服传统基于短语的翻译系统的诸多缺点。然而,NMT系统在训练和翻译推理阶段的计算成本高,以及在处理罕见词汇时的不稳定性,是其面临的主要挑战。"
本文的核心内容是介绍谷歌如何通过神经机器翻译系统来改进机器翻译的性能,使其更加接近人类翻译的水平。NMT系统采用深度学习技术,通过构建大规模的神经网络模型来理解整个句子的上下文,而不仅仅是单个单词或短语,从而提高翻译的质量。
谷歌的NMT系统旨在解决以下两个关键问题:
1. **计算效率**:传统的机器翻译系统通常基于统计和短语匹配,而NMT则依赖于复杂的神经网络模型。这导致NMT在处理大量数据和大型模型时,训练和推理过程的计算需求显著增加。为了解决这个问题,谷歌可能研究了优化算法、模型压缩以及分布式计算策略,以减少计算资源的需求。
2. **鲁棒性问题**:NMT系统在遇到输入句子中的罕见词或未见过的词汇时,翻译质量可能会下降。这是因为这些系统通常在有限的训练数据上进行学习,难以处理语言的多样性和不确定性。为提高鲁棒性,谷歌可能采用了词汇嵌入、动态词汇表扩展或使用上下文敏感的表示方法,使模型能够更好地理解和处理罕见词汇。
此外,论文还可能涉及了以下几个方面:
- **模型架构**:NMT通常采用序列到序列(Seq2Seq)模型,包含编码器和解码器两部分,其中编码器负责理解输入句子,解码器则生成对应的翻译。
- **注意力机制**:为了更好地捕捉句子的上下文信息,NMT可能引入了注意力机制,允许模型在生成每个目标词时关注源句的不同部分。
- **损失函数**:论文可能讨论了如何选择和优化损失函数,如交叉熵损失,以促进模型的训练和性能提升。
- **实验与评估**:为了验证NMT的效果,研究者可能进行了大量的实验,包括与其他翻译方法的对比,并使用BLEU等标准评估指标进行性能评估。
通过这篇论文,谷歌不仅展示了NMT在提高机器翻译质量上的潜力,同时也提出了针对计算效率和罕见词处理的解决方案,为后续的机器翻译研究和实践提供了重要参考。
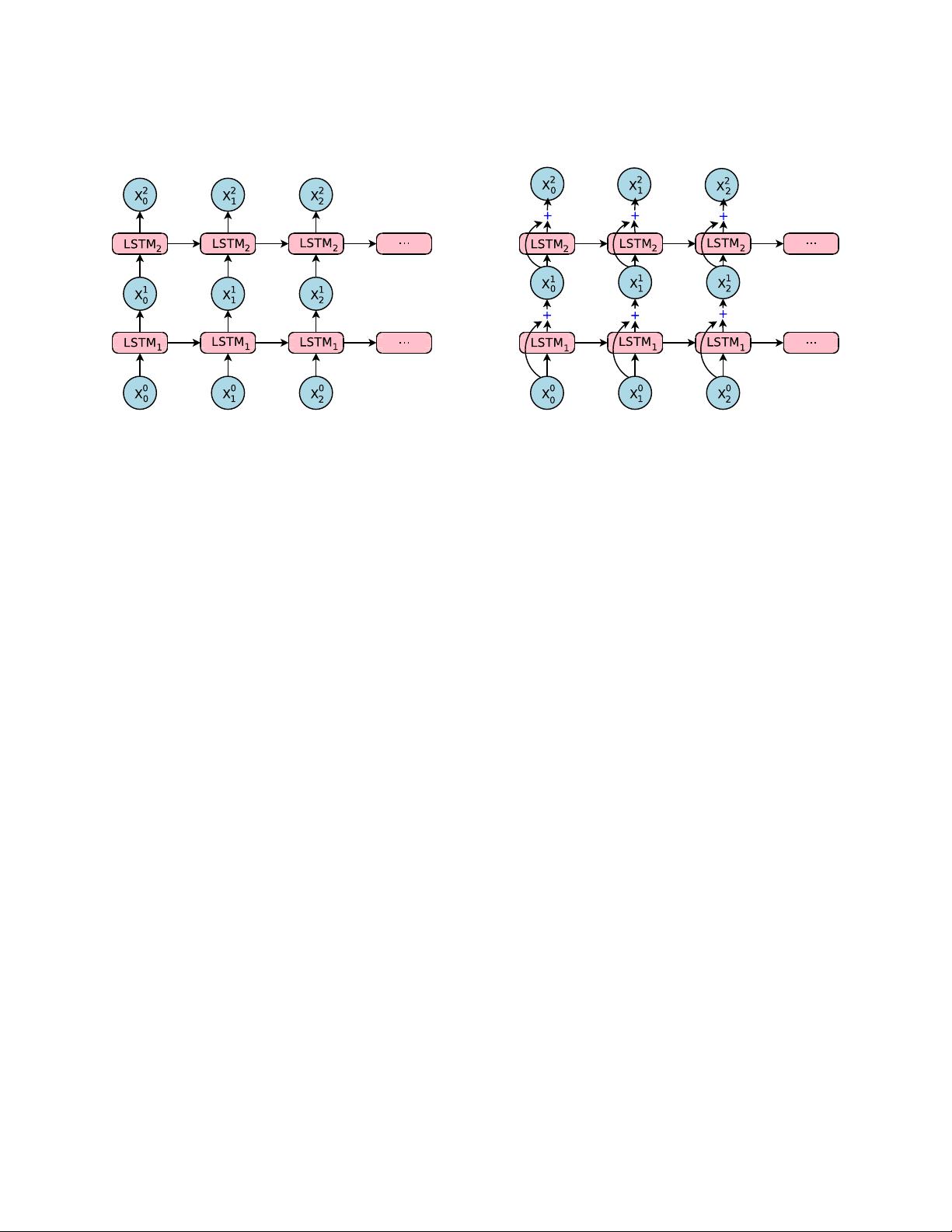
experience with large-scale translation tasks, simple stacked LSTM layers work well up to 4 layers, barely
with 6 layers, and very poorly beyond 8 layers.
Figure 2: The difference between normal stacked LSTM and our stacked LSTM with residual connections.
On the left: simple stacked LSTM layers [
39
]. On the right: our implementation of stacked LSTM layers
with residual connections. With residual connections, input to the bottom LSTM layer (
x
0
i
’s to
LSTM
1
) is
element-wise added to the output from the bottom layer (
x
1
i
’s). This sum is then fed to the top LSTM layer
(LSTM
2
) as the new input.
Motivated by [
20
], we introduce residual connections among the LSTM layers in a stack (see Figure 2).
More concretely, let
LSTM
i
and
LSTM
i+1
be the
i
-th and (
i
+1)-th LSTM layers in a stack, whose parameters
are
W
i
and
W
i+1
respectively. At the
t
-th time step, for the stacked LSTM without residual connections,
we have:
c
i
t
, m
i
t
= LSTM
i
(c
i
t−1
, m
i
t−1
, x
i−1
t
; W
i
)
x
i
t
= m
i
t
c
i+1
t
, m
i+1
t
= LSTM
i+1
(c
i+1
t−1
, m
i+1
t−1
, x
i
t
; W
i+1
)
(5)
where
x
i
t
is the input to
LSTM
i
at time step
t
, and
m
i
t
and
c
i
t
are the hidden states and memory states of
LSTM
i
at time step t, respectively.
With residual connections between LSTM
i
and LSTM
i+1
, the above equations become:
c
i
t
, m
i
t
= LSTM
i
(c
i
t−1
, m
i
t−1
, x
i−1
t
; W
i
)
x
i
t
= m
i
t
+ x
i−1
t
c
i+1
t
, m
i+1
t
= LSTM
i+1
(c
i+1
t−1
, m
i+1
t−1
, x
i
t
; W
i+1
)
(6)
Residual connections greatly improve the gradient flow in the backward pass, which allows us to train very
deep encoder and decoder networks. In most of our experiments, we use 8 LSTM layers for the encoder and
decoder, though residual connections can allow us to train substantially deeper networks (similar to what
was observed in [43]).
3.2 Bi-directional Encoder for First Layer
For translation systems, the information required to translate certain words on the output side can appear
anywhere on the source side. Often the source side information is approximately left-to-right, similar to
the target side, but depending on the language pair the information for a particular output word can be
distributed and even be split up in certain regions of the input side.
5
剩余22页未读,继续阅读
111 浏览量
2023-05-31 上传
2023-06-11 上传
2023-06-09 上传
2023-06-09 上传
2023-06-08 上传
2023-04-04 上传
2023-03-29 上传

weixin_38518638
- 粉丝: 3
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
