自适应手语识别:示例提取与MAP/IVFS方法
191 浏览量
更新于2024-08-26
收藏 89KB PDF 举报
"具有示例性提取和MAP/IVFS的自适应手语识别"
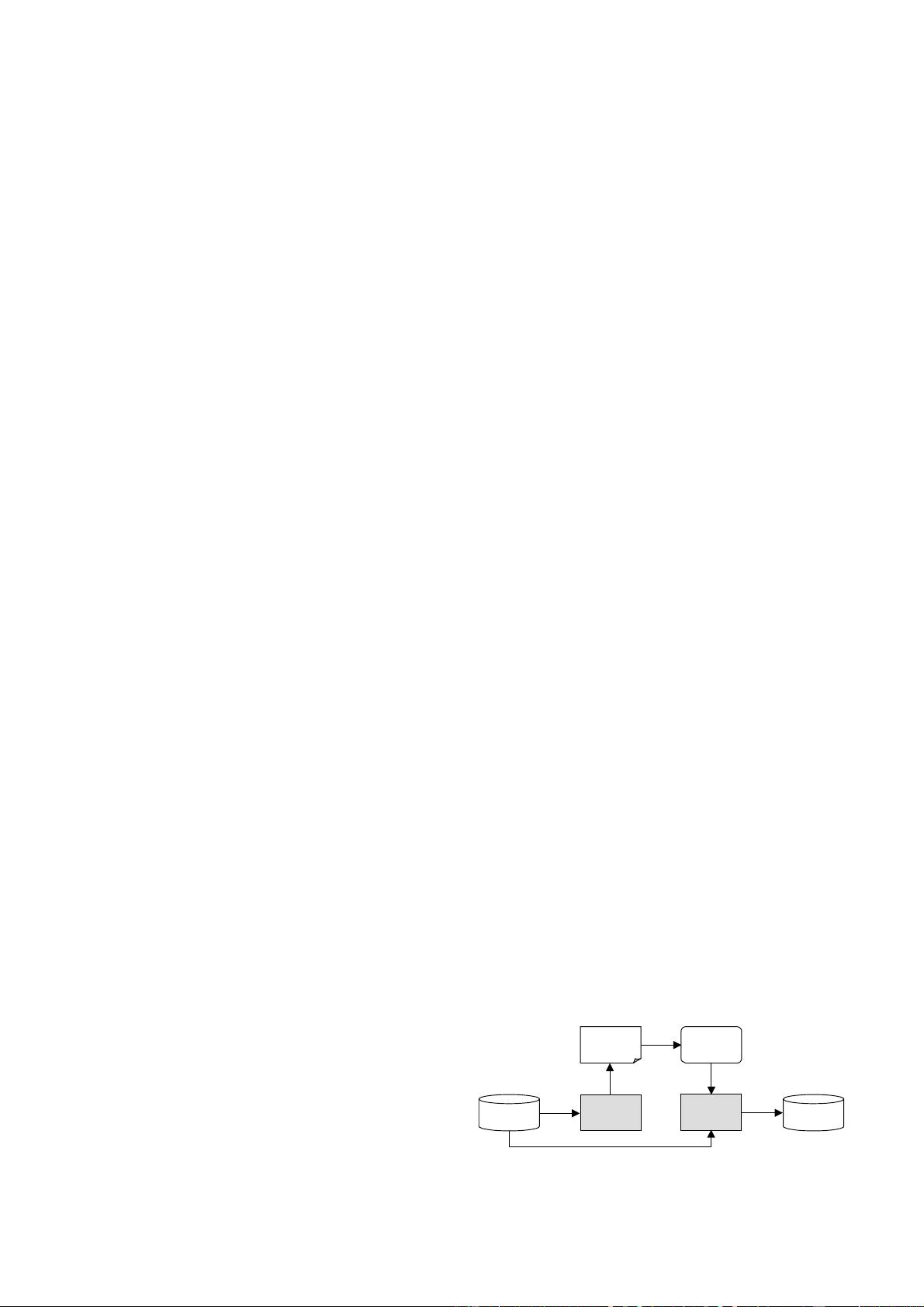
这篇研究论文探讨了手语识别系统中的签名人依赖问题,提出了一种新颖的方法来适应特定签名人,利用其少量训练数据调整原始模型集。该方法分为两个主要步骤:首先,采用亲和传播算法(Affinity Propagation)从签名人独立的隐马尔可夫模型(HMMs)中提取示例;然后,基于新词汇表收集的手势,结合最大后验概率(MAP)和迭代向量场平滑(IVFS)技术生成签名人适应模型。
手语识别是自动将手语转化为文本的技术,已有许多研究工作在这个领域进行。典型的研究如引用文献[2][3][4]所示,大多数工作都集中在建立通用模型,但这些模型通常在处理不同签名人时表现不佳,因为每个人的手势和表达方式都有所差异,这就是所谓的签名人依赖问题。
本文提出的解决方案首先运用亲和传播算法,这是一种无监督学习方法,用于从大量数据中寻找代表性样本,即签名人特有的手势模式。这种方法可以有效减少模型对大量训练数据的依赖,仅需少量特定签名人数据即可。
接下来,基于亲和传播提取出的示例,构建一个适应新签名人的词汇表。然后,利用最大后验概率(MAP)和迭代向量场平滑(IVFS)相结合的技术,对新签名人手势数据进行处理。MAP是一种统计决策理论,用于估计最可能的参数值,而IVFS则有助于平滑手势轨迹,提高识别准确性。
通过在六位签名人上的实验,研究证明了该方法能够显著减少适应数据量,同时保持高识别性能。这表明,该方法对于解决手语识别中的签名人适应问题具有显著优势,有助于开发更智能、更具适应性的手语识别系统,进一步提升系统的普适性和用户体验。
总结来说,这篇论文的核心贡献在于提出了一种基于亲和传播和MAP/IVFS的自适应手语识别方法,通过减少对大量训练数据的需求,实现了对不同签名人手势的高效识别,这对于推动手语交流的无障碍化进程具有重要意义。
SPL-07512-2009
1
Abstract—Sign language recognition systems suffer from the
problem of signer dependence. In this letter, we propose a novel
method that adapts the original model set to a specific signer with
his/her small amount of training data. First, affinity propagation
is used to extract the exemplars of signer independent hidden
Markov models; then the adaptive training vocabulary can be
automatically formed. Based on the collected sign gestures of the
new vocabulary, the combination of maximum a posteriori and
iterative vector field smoothing is utilized to generate
signer-adapted models. Experimental results on six signers
demonstrate that the proposed method can reduce the amount of
the adaptation data and still can achieve high recognition
performance.
Index Terms—Sign language recognition, signer adaptation,
affinity propagation, maximum a posteriori, vector field
smoothing.
I. I
NTRODUCTION
ign language recognition aims to transcribe sign language
to text automatically. Many works on sign language
recognition have been performed [1]. To the best of our
knowledge, some representative works are [2][3][4]. Most
works focus on signer dependent (SD) sign language
recognition. Nevertheless, the performance of the system is
poor when a signer is unregistered in the training set. Signer
independent (SI) models [5] can achieve high performance, but
still can not be comparable with SD models. Adaptation
techniques in speech recognition [6] and handwriting
recognition [7] supply an alternative solution to this problem.
Ong et al. [8] applied supervised maximum a posteriori (MAP,
[9]) to adapt their system and yielded 88.5% accuracy on a
Manuscript received on March 29, 2009; revised on September 29, 2009.
This work was supported by the Natural Science Foundation of China under
contracts 60533030, 60603023 and 60973067, and by National Key
Technology R&D Program under contract No.2008BAH26B03, and also by
open project of Beijing Multimedia and Intelligent Software Key laboratory in
Beijing University of Technology. The associate editors coordinating the
review of this manuscript and approving it for publication were Prof. Fernando
Perez-Gonzalez and Prof. Jen-Tzung Chien.
Copyright (c) 2008 IEEE. Personal use of this material is permitted.
However, permission to use this material for any other purposes must be
obtained from the IEEE by sending a request to pubspermissions@ieee.org.
Y. Zhou, D. Zhao and H. Yao are with the School of Computer Science and
Technology, Harbin Institute of Technology, Harbin, China; X. Chen is with
Key Lab of Intelligent Information Processing, Institute of Computing
Technology, Chinese Academy of Sciences, Beijing, China; W. Gao is with the
Institute of Digital Media, Peking University, Beijing, China (e-mail: {yzhou,
xlchen, dbzhao, wgao}@jdl.ac.cn; yhx@vilab.hit.edu.cn).
20-gesture vocabulary. U. von Agris et al. [10] combined
maximum likelihood linear regression and MAP for signer
adaptation. With 80 and 160 signs, they achieved 78.6% and
94.6% accuracy respectively on a vocabulary of 153 signs. In
their latest work [11], they combined eigenvoice, maximum
likelihood linear regression, and MAP algorithms to reduce the
adaptation data and retard the performance saturation. Wang et
al. [12] presented an adaptive method based on data generating,
in which they reduced the size of adaptation data set from 350
to 136 with acceptable recognition accuracy.
In this letter we propose a novel signer adaptation method to
reduce the amount of data further. As shown in Fig. 1, our
method mainly consists of two steps: the exemplar extraction
and the combination of maximum a posteriori and iterative
vector field smoothing (MAP/IVFS). First, affinity propagation
(AP, [13]) is used to extract a subset of the vocabulary, which
can represent the major characteristics of the new signer’s
signing; then MAP/IVFS is adopted to modify the parameters
of the models. In the next two sections, AP based exemplar
extraction and MAP/IVFS are described respectively, and the
experiment evaluation and conclusion are given in Section IV
and V respectively.
II. E
XEMPLAR
E
XTRACTION
Different people have different hand sizes, body sizes,
signing habits, signing rhythms, and so on, which leads to
varieties when they sign the same word. The mismatch between
the training data and the test data leads to poor recognition
performance. One alternative to solve this problem is collecting
enough data from different people to train SI models. In this
way two problems stand out:
1) The models are difficult to converge because the data of
different people vary noticeably. Sometimes the
distinctions between the data of two different people on the
same sign are almost larger than the distinctions between
the data of the same people on two different signs.
Adaptive Sign Language Recognition
with Exemplar Extraction and MAP/IVFS
Yu Zhou, Xilin Chen, Member, IEEE, Debin Zhao, Hongxun Yao, and Wen Gao, Fellow, IEEE
S
SI Models SA Models
Exemplar
Extraction
MAP/IVFS
Exemplar
Subset
Adaptation
Data
Fig. 1. Exemplar extraction and MAP/IVFS for signer adaptation
下载后可阅读完整内容,剩余3页未读,立即下载
318 浏览量
2022-07-15 上传
2016-03-24 上传
2021-05-29 上传
2018-07-24 上传
2021-05-29 上传
2021-03-12 上传
2020-09-25 上传

weixin_38676500
- 粉丝: 9
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
