巴豆大数据HBase深度解析:从基础到实践
需积分: 18 189 浏览量
更新于2024-07-16
收藏 1.48MB PDF 举报
"这是巴豆大数据团队的一份关于Hbase的讲师课件,涵盖了Hbase的基础知识、实践操作以及其在大数据场景中的应用。"
HBase,全称为Hadoop Database,是一个开源的非关系型分布式数据库(NoSQL),设计灵感来源于谷歌的BigTable,主要用Java语言实现,并作为Apache Hadoop项目的一部分,运行在HDFS(Hadoop Distributed File System)之上,具备处理海量稀疏数据的能力。HBase提供了高可靠性、高并发读写、面向列的存储方式,并且具有良好的可伸缩性,易于构建大规模数据存储解决方案。
在存储方式上,HBase采用了与传统行存储不同的列存储模式。行存储在写入时一次性完成,保证数据完整性,但在读取时可能会产生冗余数据。而列存储则在读取时避免冗余,尤其适用于对数据完整性要求不高的大数据场景,但写入效率相对较低。
HBase的优势在于其对海量数据的存储能力,能够实现快速的随机访问,特别适合处理大量写操作的应用。例如,在互联网搜索引擎中,HBase可以高效存储和检索数据;在消息中心,它可以快速处理并存储大量的消息数据;在内容服务系统中,由于其schema-free的特性,HBase可以灵活应对不断变化的数据结构;对于需要复杂及多维度索引的大表,HBase也表现出色;同时,对于大批量数据的读取,HBase也能提供高效的性能。
HBase的数据模型由四个主要部分构成:
1. RowKey(行键):每个记录的唯一标识,通常设计为Bytearray,以便于快速查找。RowKey的选择和设计对于查询效率至关重要。
2. ColumnFamily(列族):列族是HBase的基本存储单元,拥有一个名称,并包含一组相关的列。所有的列都属于某个特定的列族。
3. Column(列):每个列由其所属的列族名和具体的列名组成,如familyName:columnName,可以在记录中动态添加。
4. VersionNumber(版本号):默认为系统时间戳,可以自定义,用于区分同一列族下不同时间点的值。
5. Value(值):存储的数据,以Bytearray形式存在,可以是任意类型的数据。
这份资料提供了HBase的基础知识讲解,包括如何搭建HBase环境、使用HbaseShell进行操作,以及通过Python进行HBase的交互。它对于理解和掌握HBase的核心概念、操作方法以及实际应用非常有帮助,是一份全面的学习资源。
八斗大数据培训 Hbase
——
八斗大数据内部资料,盗版必究
——
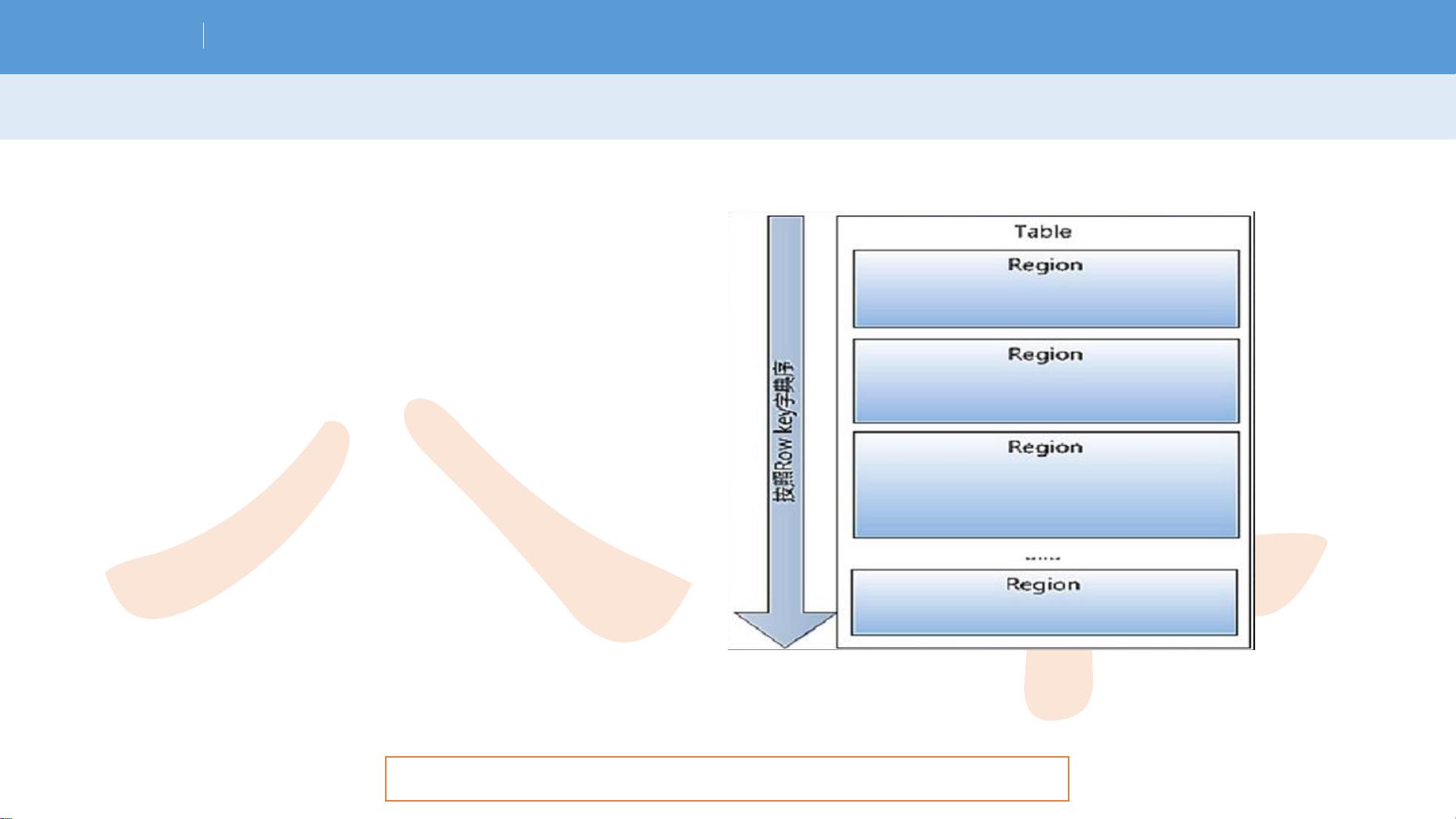
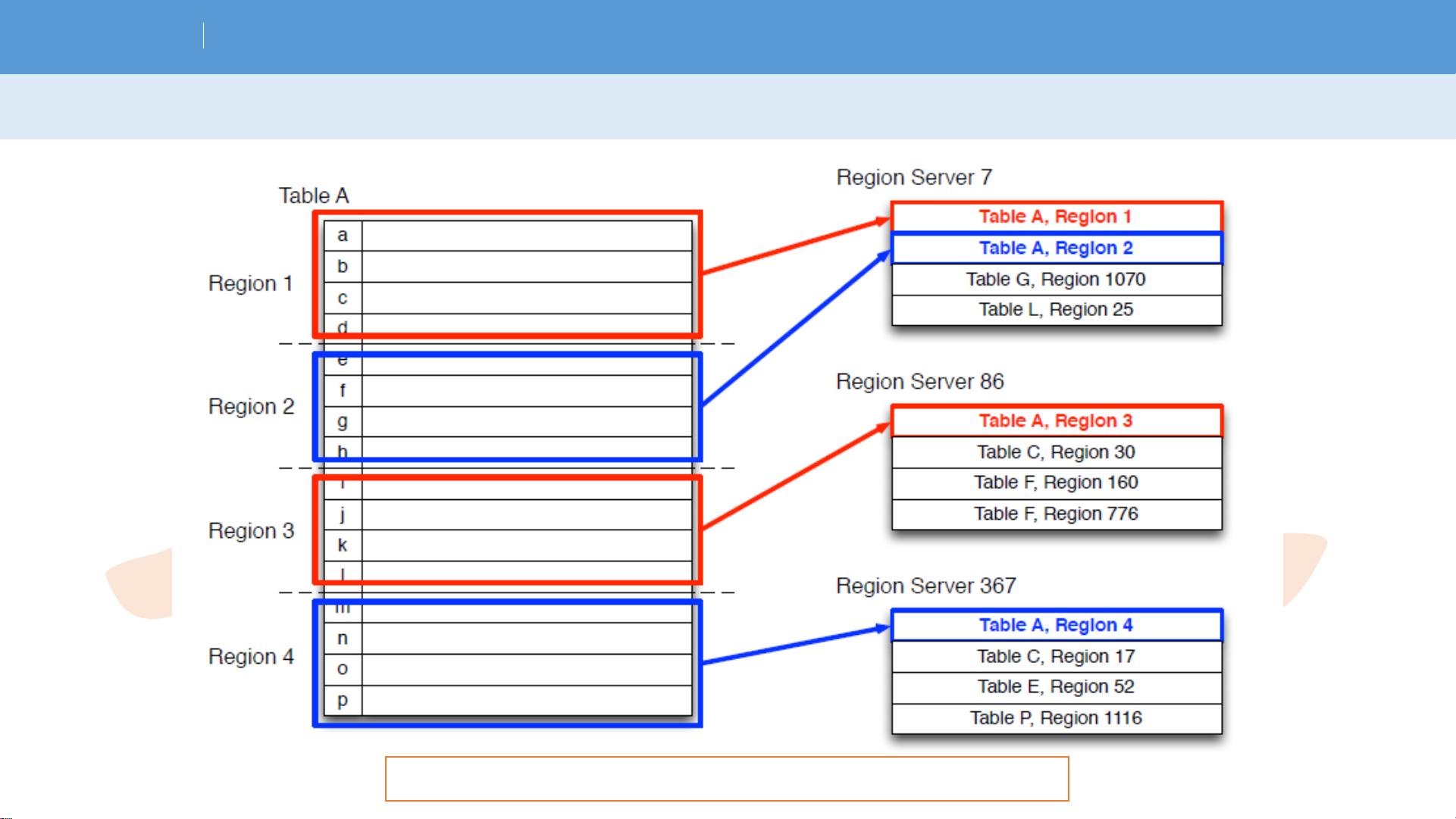
H b a s e 物理模型
• Hbase一张表由一个或多个
Hregion组成
• 记录之间按照Row Key的字典
序排列
剩余63页未读,继续阅读
2020-02-20 上传
2020-02-20 上传
2020-02-20 上传
2020-02-20 上传
2020-02-20 上传
点击了解资源详情
点击了解资源详情
2021-12-15 上传
2020-02-20 上传

一尘在心
- 粉丝: 253
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于ASP+ACCESS网上图书销售系统(源代码+论文).rar
- flysystem-rackspace:用于机架空间的Flysystem适配器
- 2014年研究生数学建模竞赛优秀论文选.rar华为杯
- netty-handler-4.1.16.Final.jar中文-英文对照文档.zip
- 【创新发文无忧】Matlab实现能量谷优化算法EVO-DELM的故障诊断算法研究.rar
- 基于HTML实现的亚麻背景响应式图片画廊html5(含HTML源代码+使用说明).zip
- node-farm:基于Node核心模块的Web服务器
- Python库 | arcframework-2.4.8-py3-none-any.whl
- omnia-led-colors:根据带宽wifi的使用情况设置Turris Omnia上的LED
- textlint-rule-write-good:使用textlint规则检查您的英语风格是否良好
- dropbox-integration:将 Zendesk 票证上的附件保存到 Dropbox 帐户
- transport-6.3.0.jar中文-英文对照文档.zip
- main_BP神经网络代码_期望传播_
- 【创新发文无忧】Matlab实现蝠鲼觅食优化算法MRFO-DELM的故障诊断算法研究.rar
- [上海]中式低密度滨水豪宅规划文本PDF2019
- dot-vimrc:.vimrc和任何辅助文件
