Amazon Redshift数据库开发全面指南
需积分: 50 144 浏览量
更新于2024-07-18
1
收藏 7.09MB PDF 举报
"Amazon Redshift数据库开发人员指南是官方文档,涵盖了如何使用Amazon Redshift进行大数据处理和数据库开发。此指南适用于新用户和有经验的数据库开发者,详细介绍了Redshift的系统架构、性能特性和集成其他AWS服务的方法。"
Amazon Redshift是一个基于云的数据仓库服务,由Amazon Web Services (AWS) 提供,它专为大规模数据分析设计。作为一款大数据解决方案,Redshift结合了列式存储、数据压缩和查询优化等特性,旨在提供高性能和高效率的分析能力。
**Amazon Redshift系统概览**
Amazon Redshift采用了分布式架构,数据仓库系统架构支持分片(sharding)和并行处理,能够处理PB级别的数据。它利用大规模并行处理(MPP)来加速查询执行,使得多个节点可以同时处理不同部分的复杂查询,极大地提高了处理速度。
**性能特性**
1. **列式数据存储**:与传统的行式存储不同,列式存储更利于分析查询,因为可以只读取需要的列,减少了I/O操作。
2. **数据压缩**:Redshift自动对数据进行压缩,降低了存储需求,同时也减少了在处理数据时的网络传输量。
3. **查询优化器**:Redshift拥有强大的查询优化器,能够根据数据分布和统计信息制定最优的执行计划。
4. **结果缓存**:为了提高性能,Redshift会缓存查询结果,对于重复查询能快速返回结果。
5. **编译后的代码**:查询处理过程中的部分工作负载会被转化为编译后的机器代码,进一步提升执行效率。
**内部架构和系统操作**
Redshift的内部架构包括多个节点,每个节点又包含多个段(segments),这种设计使得数据处理可以高度并行化。工作负载管理(Workload Management)允许管理员控制和调度查询,确保资源的公平分配。
**与其他服务的集成**
1. **Amazon S3**:可以方便地在Redshift和Amazon Simple Storage Service (S3)之间移动数据,用于数据导入和导出。
2. **Amazon DynamoDB**:可以与NoSQL数据库DynamoDB集成,实现结构化和非结构化数据的混合分析。
3. **SSH导入**:通过SSH可以直接从远程主机导入数据到Redshift。
4. **AWS Data Pipeline**:可以使用Data Pipeline自动化数据加载流程,定期更新数据仓库。
5. **AWSDatabaseMigrationService (DMS)**:用于迁移现有的数据库到Redshift,简化数据迁移过程。
**数据库使用入门**
入门Redshift涉及以下基本步骤:
1. 创建数据库实例。
2. 创建数据库用户,并管理权限。
3. 设计和创建数据库表。
4. 加载数据到表中,可以是从其他数据源如S3或CSV文件导入。
5. 使用SQL查询语言执行查询,分析存储在Redshift中的数据。
这个官方指南提供了详细的步骤和示例,帮助开发者快速掌握Amazon Redshift的使用,充分利用其在大数据处理和分析领域的优势。
Amazon Redshift 数据库开发人员指南
数据仓库系统架构
Amazon Redshift 系统概览
主题
• 数据仓库系统架构 (p. 3)
• 性能 (p. 5)
• 列式存储 (p. 7)
• 内部架构和系统操作 (p. 8)
• 工作负载管理 (p. 9)
• 将 Amazon Redshift 与其他服务结合使用 (p. 9)
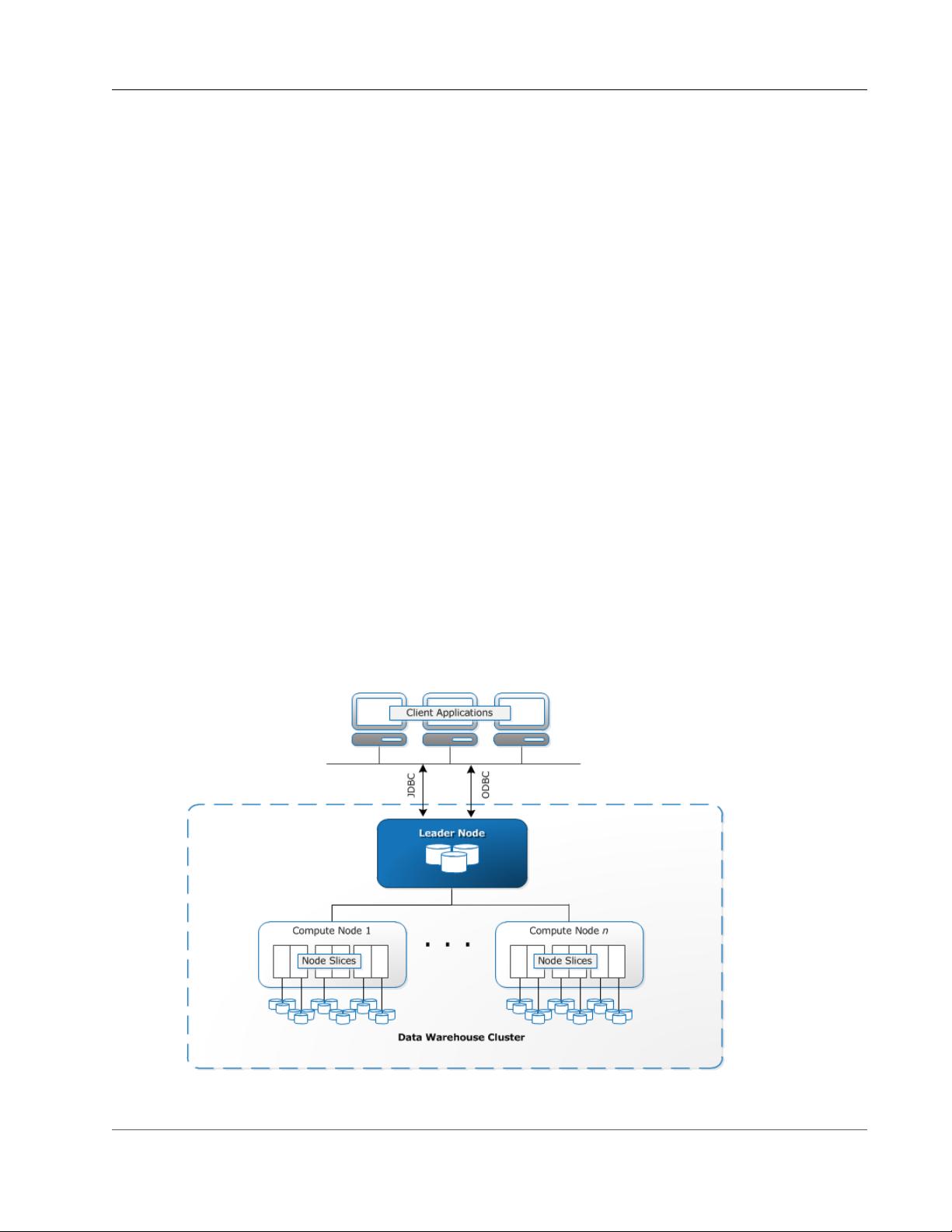
Amazon Redshift 数据仓库是一个企业级的关系数据库查询和管理系统。
Amazon Redshift 支持与多种类型的应用程序(包括商业智能 (BI)、报告、数据和分析工具)建立客户端连
接。
在执行分析查询时,您将在多阶段操作中检索、比较和计算大量数据以产生最终结果。
Amazon Redshift 通过大规模并行处理、列式数据存储和非常高效且具有针对性的数据压缩编码方案的组
合,实现高效存储和最优查询性能。此部分介绍了 Amazon Redshift 系统架构。
数据仓库系统架构
此部分介绍 Amazon Redshift 数据仓库架构的元素,如下图所示。
客户端应用程序
API 版本 2012-12-01
3



剩余921页未读,继续阅读
2021-05-03 上传
2021-05-01 上传
2018-06-01 上传
2023-09-09 上传
2023-05-10 上传
2024-08-31 上传
2024-11-01 上传
2024-11-01 上传
2023-09-17 上传

坤宇辰大数据
- 粉丝: 3
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
