
4807
×
×
×
模型
通道数
块数
股骨头数
量
FLOPs
Param
MViT-T
[96-192-384-768]
[1-2-5-2]
[1-2-4-8]
4.7
24
MViT-S
[96-192-384-768]
[1-2-11-2]
[1-2-4-8]
7.0
35
MViT-B
[96-192-384-768]
[2-3-16-3]
[1-2-4-8]
10.2
52
MViT-L
[144-288-576-1152]
[2-6-36-4]
[2-4-8-16]
39.6
218
MViT-H [192-384-768-1536] [4-8-60-8][3-6-12-24]
120.6
667
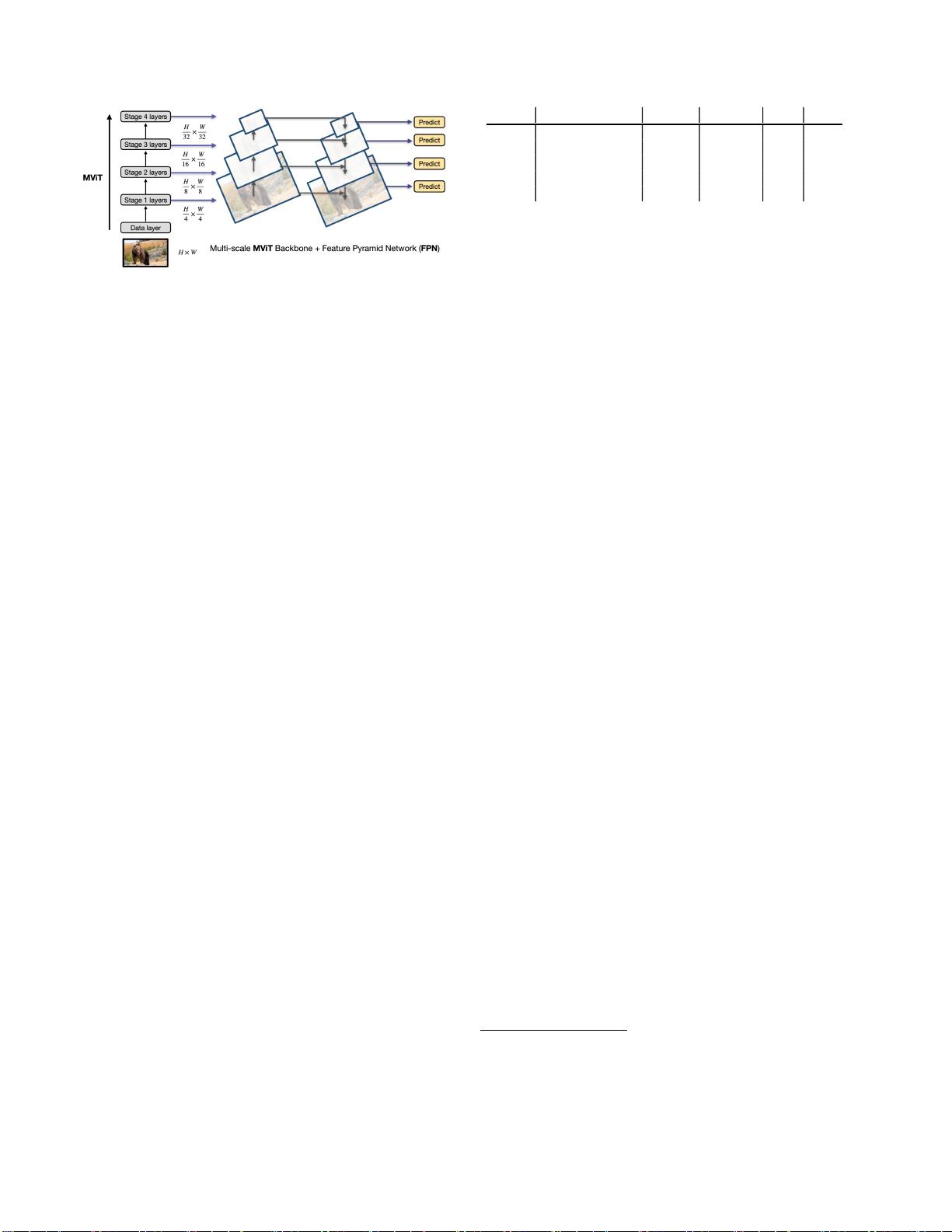
图 3. MViT 主 干 与 FPN 一 起 用 于 对 象 检 测 。 多 尺 度
Transformer功能与标准功能金字塔网络(FPN)自然集成。
计算自我注意力时的键值张量。然而,它们的内在本
质是不同的:通过
局部聚合
对特征进行下采样来池化
注意力池,但保持
全局
自注意力计算,而窗口注意力
保持张量的分辨率,但通过将输入(补丁化的令牌)
划分为非重叠窗口
来局部
执行自注意力,然后仅计算
每个窗口内的局部自注意力。这两种方法的内在差异
促使我们研究它们是否可以在目标检测任务中发挥互
补作用。
默认窗口注意力只在窗口内执行局部自注意,因此
缺乏跨窗口的连接。与Swin [55]不同,Swin [55]使用
移位窗口来缓解这个问题,我们提出了一个简单
的混
合窗口注意力
(Hwin)设计来添加跨窗口连接。Hwin
在窗口内计算局部注意力,除了馈送到FPN的最后三个
阶段的最后块之外。以这种方式,到FPN的输入特征映
射包 含 全局 信 息。 §5.3 中的 消 融表 明 ,这 个 简单 的
Hwin 在 图 像 分 类 和 对 象 检 测 任 务 上 始 终 优 于 Swin
[55]。此外,我们将证明,结合池化注意力和Hwin实
现了对象检测的最佳性能。
检测中的位置嵌 入。 与输入是固定分辨率的作物的
Ima-geNet分类不同(
例如
,224 224),对象检测通常
包含训练中不同大小的输入。对于MViT中的位置嵌入
(绝对或相对),我们首先从ImageNet预训练权重中
初始化对应于224 224输入大小的位置嵌入的参数,然
后将它们插值到相应的大小以进行对象检测训练。
4.3.
用于视频识别
MViT可以很容易地用于视频识别任务(
例如
,动力
学数据集)类似于MViTv1 [21],因为§4.1中的升级模
块推广到时空域。虽然MViTv1只关注Kinetics的从头开
始 训 练 设 置 , 但 在 这 项 工 作 中 , 我 们 还 研 究 了
ImageNet数据集预训练的(大)影响。
从预训练的MViT初始化 相比
表
1. MViT
变体的配置。
#
通道
,
#
块
和#Heads分别指定四个阶段的通道宽度、MViT块的数量和
每个块中的头。FLOPs测量的图像分类与224 224输入。阶段
分辨率为[56
2
,28
2
,14
2
,7
2
]。
与基于图像的MViT相比,基于视频的MViT仅存在三
个差异:1)
分块主干
中的投影层需要将输入投影到时
空立方体中而不是2D分块中; 2)池化算子现在池化时
空特征图; 3)相对位置嵌入参考时空位置。
由于1)和2)中的投影层和池化操作符在
默认情况
下由
卷积层实例化4,因此我们使用如CNN [8,24]的膨胀
初始化。具体来说,我们使用来自预训练模型中的2D
conv层的权重初始化中心帧的conv滤波器,并将其他
权重初始化为零。对于3),我们利用我们分解的相对
位置嵌入在等式2中。4,并且简单地将来自预训练权
重的空间嵌入和时间嵌入初始化为零。
4.4.
MViT体系结构变体
我们构建了几个具有不同数量参数和FLOP的MViT
变体,如表1所示,以便与其他视觉Transformer作品进
行公平比较[9,55,72,81]。具体而言,我们设计了
五个变种(微小,小,基地,大和巨大)MViT通过改
变基础通道尺寸,在每个阶段的块的数量和头的块的
数量。请注意,我们使用较少数量的头来改善运行
时,因为更多的头会导致更慢的运行时,但对FLOP和
参数没有影响遵循MViT [21]中的池化注意力设计,我
们默认在所有池化注意力块中使用键和值池化,并且
在第一阶段
并
自适应
地衰减跨级的步幅相对于分辨率
5.
实验:图像识别
我们对ImageNet分类[14]和COCO对象检测[54]进行
了实验我们首先展示最先进的比较,然后进行全面消
融。更多结果和讨论见§A。
5.1.
ImageNet-1 K图像分类
设置. ImageNet-1 K [14](IN-1 K)数据集
1000 个 类 中
的
128 万 张 图 片 。 我 们 在 IN-1 K 上 针 对
MViTv 2的训练配方遵循MViTv 1[21,72]。我们训练
4
注意,如果使用最大池变量,则不需要初始化。
剩余15页未读,继续阅读

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


