深入解析Lucene 3.0:原理与代码剖析
需积分: 0 47 浏览量
更新于2024-07-30
收藏 4.64MB PDF 举报
"Lucene 3.0 原理与代码分析"
Lucene是一个开源的全文检索库,由Apache软件基金会开发并维护,它提供了高级的文本搜索功能。在Lucene 3.0版本中,这个库已经相当成熟,为开发者提供了强大的文本处理和检索能力。本资源主要围绕Lucene 3.0的原理和内部实现进行深入解析,旨在帮助读者理解其核心机制。
全文检索是Lucene的基础,它不同于简单的关键词匹配,而是通过建立索引来高效地查找包含特定词汇的文档。在Lucene中,全文检索涉及到以下几个关键概念:
1. 分词(Tokenization):在创建索引时,Lucene会将输入的文本分解成一系列的词元(Token),这是全文检索的第一步。分词器(Tokenizer)在这里起着至关重要的作用,它决定了如何识别和分割文本。
2. 词干提取(Stemming)与词形还原(Lemmatization):为了减少词汇表的大小并提高搜索效率,Lucene可能会对词元进行词干提取或词形还原。例如,将"running"和"runs"都转换为"run",以便在搜索时可以匹配不同形式的同义词。
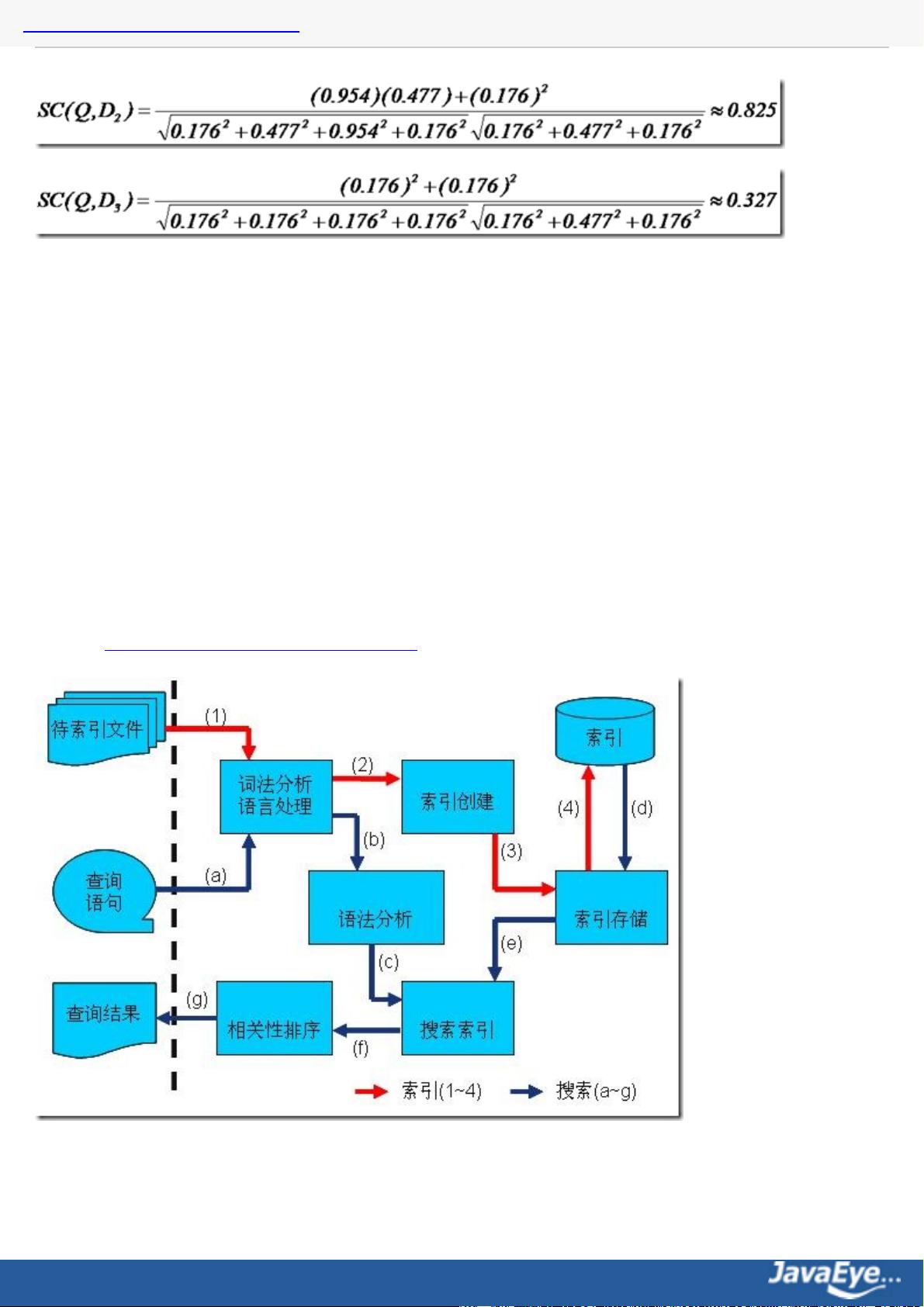
3. 索引文件格式:Lucene的索引由多个文件组成,包括倒排索引(Inverted Index)、频率文件(Term Frequency)、文档频率文件(Document Frequency)等。这些文件共同构成了一个高效的搜索结构,使得快速查找匹配文档成为可能。
4. 索引过程分析:创建索引的过程涉及文档的读取、分词、词元的处理以及索引文件的写入。这一部分详细解释了从原始文本到可搜索索引的转换步骤。
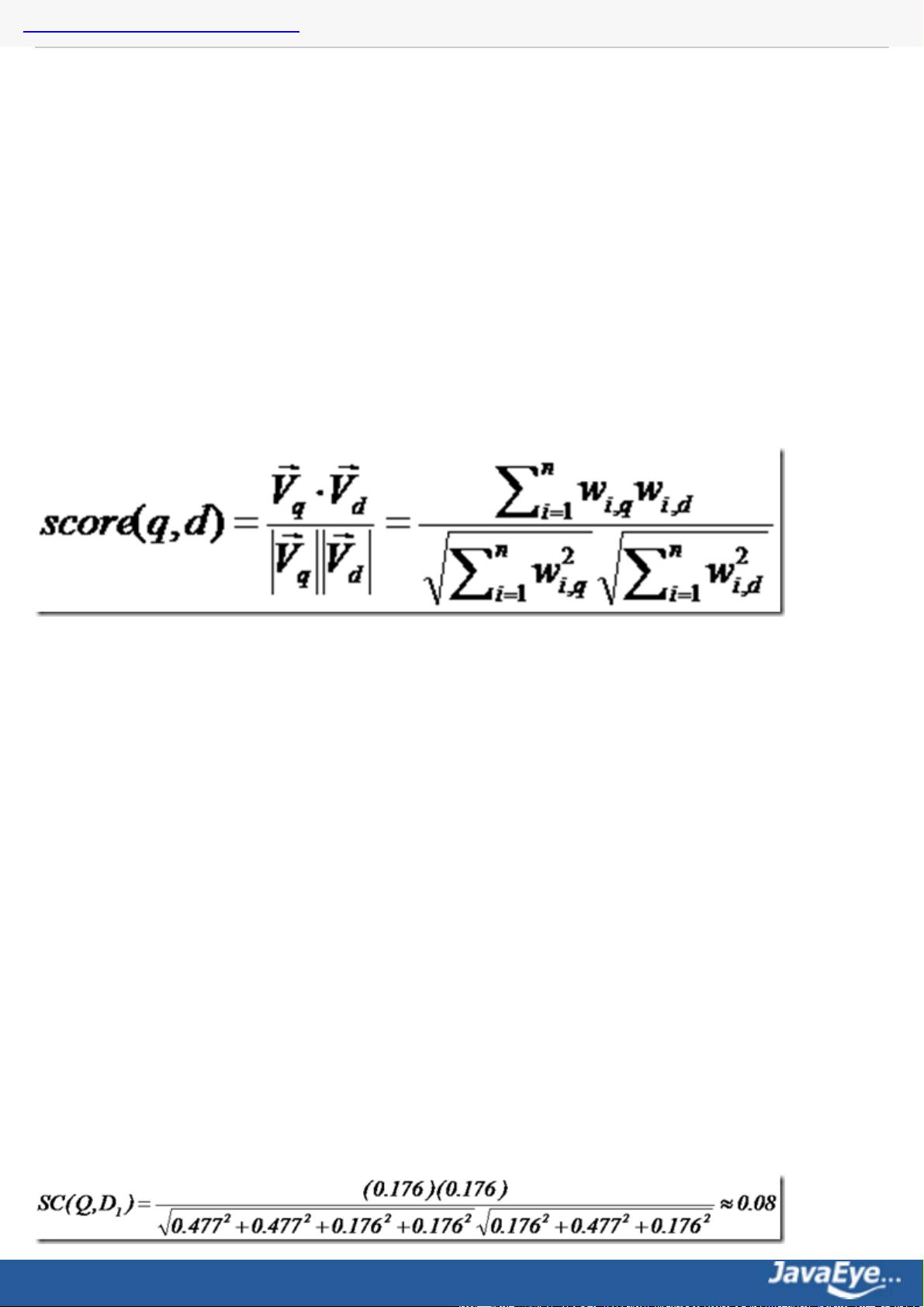
5. 打分机制:Lucene使用向量空间模型来评估查询与文档的相关性,并为每个匹配文档分配一个分数。这个分数反映了文档与查询的匹配程度,通常用于决定搜索结果的排序。
6. 问题解答:资源中还包含了对一些常见问题的解答,如为什么能搜索到"中华AND共和国"却搜不到"中华共和国",这涉及到Lucene的查询解析和短语匹配规则。其他问题涵盖了stemming和lemmatization的区别,以及影响Lucene文档打分的四种方式。
通过对这些内容的深入学习,读者不仅可以掌握Lucene的工作原理,还能了解到如何优化搜索性能和调整搜索结果的相关性。对于Java开发者来说,这是一份宝贵的参考资料,可以帮助他们在实际项目中有效利用Lucene进行全文检索和信息检索系统的构建。

计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。
词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term
weight),因而在计算文档之间的相关性中将发挥更大的作用。
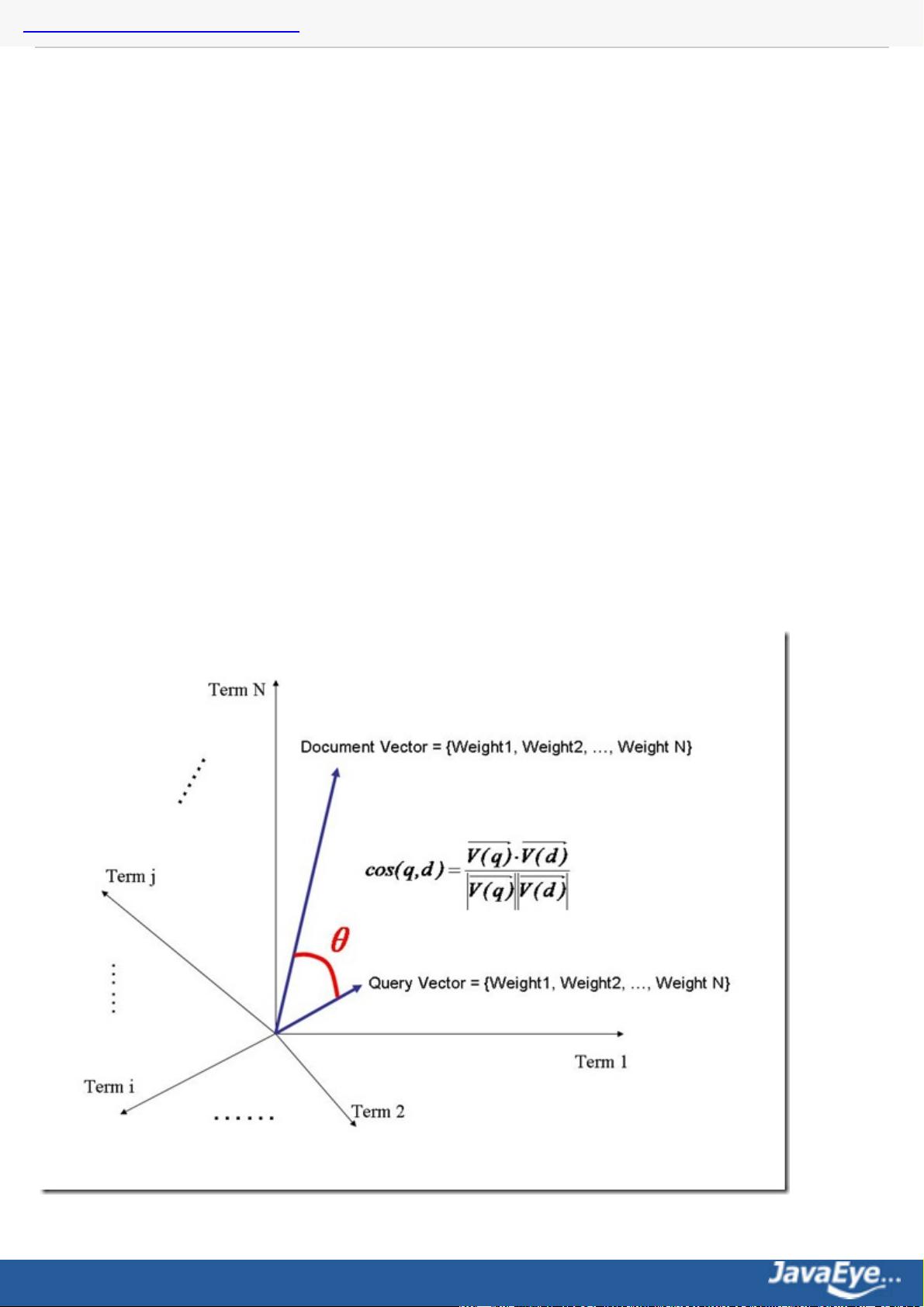
判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space
Model)。
下面仔细分析一下这两个过程:
1. 计算权重(Term weight)的过程。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
• Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
• Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
容易理解吗?词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本
文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,
就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明
此词(Term)太普通,不足以区分这些文档,因而重要性越低。
这也如我们程序员所学的技术,对于程序员本身来说,这项技术掌握越深越好(掌握越深说明花时间看的越
多,tf越大),找工作时越有竞争力。然而对于所有程序员来说,这项技术懂得的人越少越好(懂得的人少df
小),找工作越有竞争力。人的价值在于不可替代性就是这个道理。
道理明白了,我们来看看公式:
这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现,Lucene就与此稍有
不同。
http://forfuture1978.javaeye.com
1.1 Lucene学习总结之一:全文检索的基本原理
第 16 / 199 页

剩余198页未读,继续阅读
2011-08-18 上传
2023-09-22 上传
2017-10-28 上传
2010-02-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

gaojiewang
- 粉丝: 20
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
