Facebook's Haystack: A High-Performance Photo Storage System for...
需积分: 10 162 浏览量
更新于2024-09-12
收藏 312KB PDF 举报
Facebook's "Haystack" 是一项针对其照片应用优化的对象存储系统,该系统在处理海量数据时展现出了高性能和经济性。Facebook每天面临着巨大的数据挑战,它存储了超过2600亿张图片,总数据量超过20拍字节(PB)。每周用户上传约10亿张新照片(约60TB),高峰期每秒需要服务超过100万张图片。这样的规模促使Facebook需要一种比之前依赖网络附加存储(NAS)设备通过NFS协议的解决方案更高效、成本更低的架构。
传统设计中的一个主要问题是元数据查找带来的大量磁盘操作。在Haystack中,Facebook的关键创新在于减少每张照片的元数据查找次数,使得存储服务器能够在主内存中完成这些操作。这一改变显著减少了对实际数据读取的磁盘访问,从而提高了整体的吞吐量。通过优化存储系统来减少不必要的I/O操作,Haystack确保了Facebook在照片分享业务中的高可用性和性能需求。
Haystack的设计背后体现了现代IT系统中的核心原则,即利用内存性能提升数据处理能力,尤其是在大数据场景下。Facebook的照片应用对存储系统的高并发性和低延迟要求极高,而Haystack正是针对这些需求进行定制化的解决方案。通过将元数据管理与数据访问分离,系统能够更好地平衡存储和计算资源,提升整体存储效率,降低运营成本。
此外,随着社交媒体用户数量的增长和照片生成速率的加快,Facebook不断寻求技术上的突破来适应这种增长。Haystack的成功案例表明,企业在构建大规模数据存储系统时,不仅关注容量和性能,还要重视优化数据访问模式和降低元数据处理开销,这将直接影响到整个系统的可扩展性和服务质量。
Facebook的Haystack项目是一个具有重要意义的案例,展示了如何通过技术创新解决大规模数据存储问题,并为其他互联网公司提供了处理海量照片数据的参考模板。通过将元数据优化与存储架构相结合,Haystack不仅提升了Facebook在照片处理方面的性能,也预示着未来IT基础设施朝着更加智能、高效的方向发展。
Browser
Web
Server
CDN
1 2
3
4
7
8
Photo Store
Server
Photo Store
Server
5
6
NFS
NASNASNAS
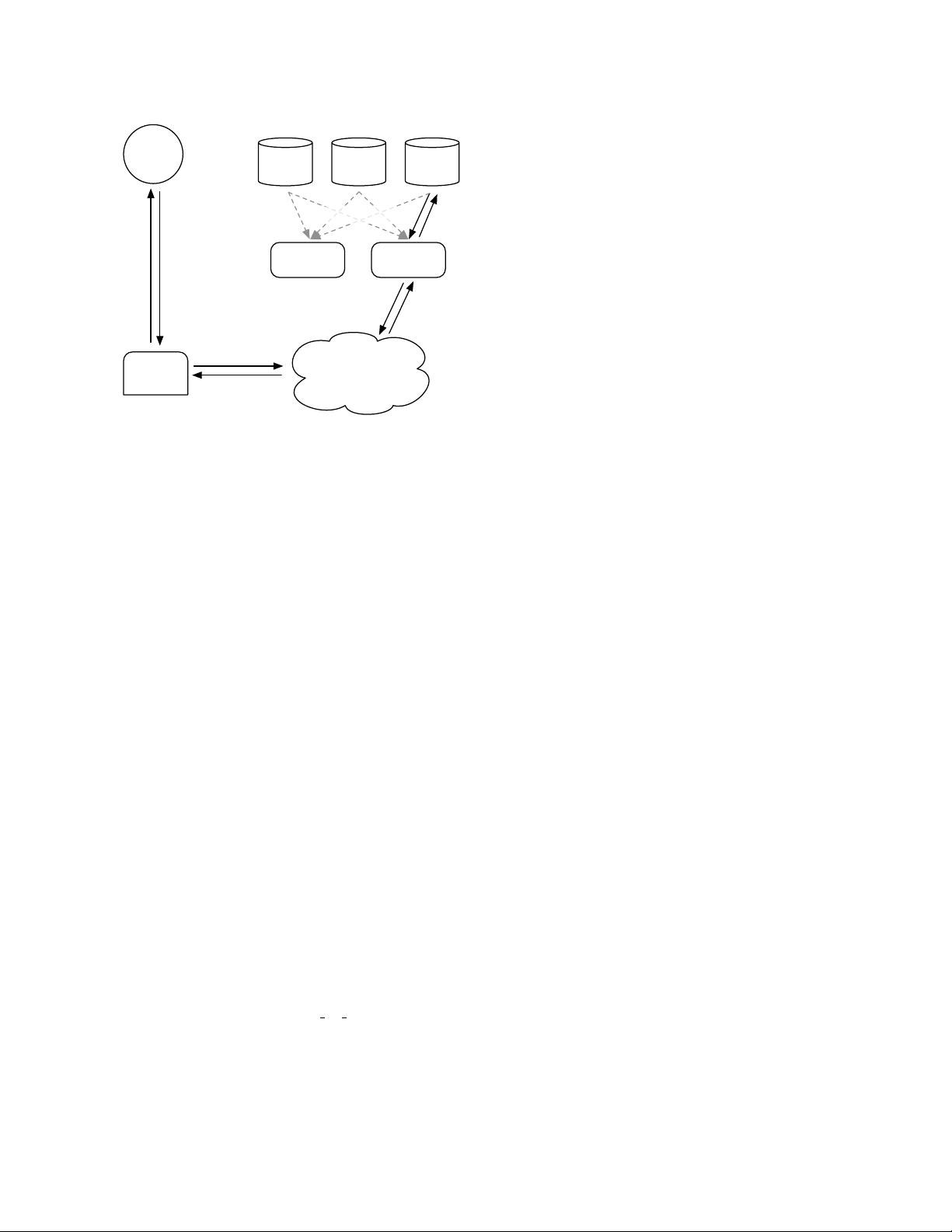
Figure 2: NFS-based Design
machines, Photo Store servers, then mount all the vol-
umes exported by these NAS appliances over NFS. Fig-
ure 2 illustrates this architecture and shows Photo Store
servers processing HTTP requests for images. From an
image’s URL a Photo Store server extracts the volume
and full path to the file, reads the data over NFS, and
returns the result to the CDN.
We initially stored thousands of files in each directory
of an NFS volume which led to an excessive number of
disk operations to read even a single image. Because
of how the NAS appliances manage directory metadata,
placing thousands of files in a directory was extremely
inefficient as the directory’s blockmap was too large to
be cached effectively by the appliance. Consequently
it was common to incur more than 10 disk operations to
retrieve a single image. After reducing directory sizes to
hundreds of images per directory, the resulting system
would still generally incur 3 disk operations to fetch an
image: one to read the directory metadata into memory,
a second to load the inode into memory, and a third to
read the file contents.
To further reduce disk operations we let the Photo
Store servers explicitly cache file handles returned by
the NAS appliances. When reading a file for the first
time a Photo Store server opens a file normally but also
caches the filename to file handle mapping in mem-
cache [18]. When requesting a file whose file handle
is cached, a Photo Store server opens the file directly
using a custom system call, open by filehandle, that
we added to the kernel. Regrettably, this file handle
cache provides only a minor improvement as less pop-
ular photos are less likely to be cached to begin with.
One could argue that an approach in which all file han-
dles are stored in memcache might be a workable solu-
tion. However, that only addresses part of the problem
as it relies on the NAS appliance having all of its in-
odes in main memory, an expensive requirement for tra-
ditional filesystems. The major lesson we learned from
the NAS approach is that focusing only on caching—
whether the NAS appliance’s cache or an external cache
like memcache—has limited impact for reducing disk
operations. The storage system ends up processing the
long tail of requests for less popular photos, which are
not available in the CDN and are thus likely to miss in
our caches.
2.3 Discussion
It would be difficult for us to offer precise guidelines
for when or when not to build a custom storage system.
However, we believe it still helpful for the community
to gain insight into why we decided to build Haystack.
Faced with the bottlenecks in our NFS-based design,
we explored whether it would be useful to build a sys-
tem similar to GFS [9]. Since we store most of our user
data in MySQL databases, the main use cases for files
in our system were the directories engineers use for de-
velopment work, log data, and photos. NAS appliances
offer a very good price/performance point for develop-
ment work and for log data. Furthermore, we leverage
Hadoop [11] for the extremely large log data. Serving
photo requests in the long tail represents a problem for
which neither MySQL, NAS appliances, nor Hadoop are
well-suited.
One could phrase the dilemma we faced as exist-
ing storage systems lacked the right RAM-to-disk ra-
tio. However, there is no right ratio. The system just
needs enough main memory so that all of the filesystem
metadata can be cached at once. In our NAS-based ap-
proach, one photo corresponds to one file and each file
requires at least one inode, which is hundreds of bytes
large. Having enough main memory in this approach is
not cost-effective. To achieve a better price/performance
point, we decided to build a custom storage system that
reduces the amount of filesystem metadata per photo so
that having enough main memory is dramatically more
cost-effective than buying more NAS appliances.
3 Design & Implementation
Facebook uses a CDN to serve popular images and
leverages Haystack to respond to photo requests in the
long tail efficiently. When a web site has an I/O bot-
tleneck serving static content the traditional solution is
to use a CDN. The CDN shoulders enough of the bur-
den so that the storage system can process the remaining
tail. At Facebook a CDN would have to cache an unrea-
剩余13页未读,继续阅读
2019-09-25 上传
2021-02-05 上传
2022-01-26 上传
2022-02-12 上传
2021-03-14 上传

honXian
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
