尚硅谷Hadoop(MapReduce)V2.0:MapReduce编程框架及优缺点 - Java大数据前端python人工智能...
需积分: 0 109 浏览量
更新于2023-11-24
收藏 65.9MB DOCX 举报
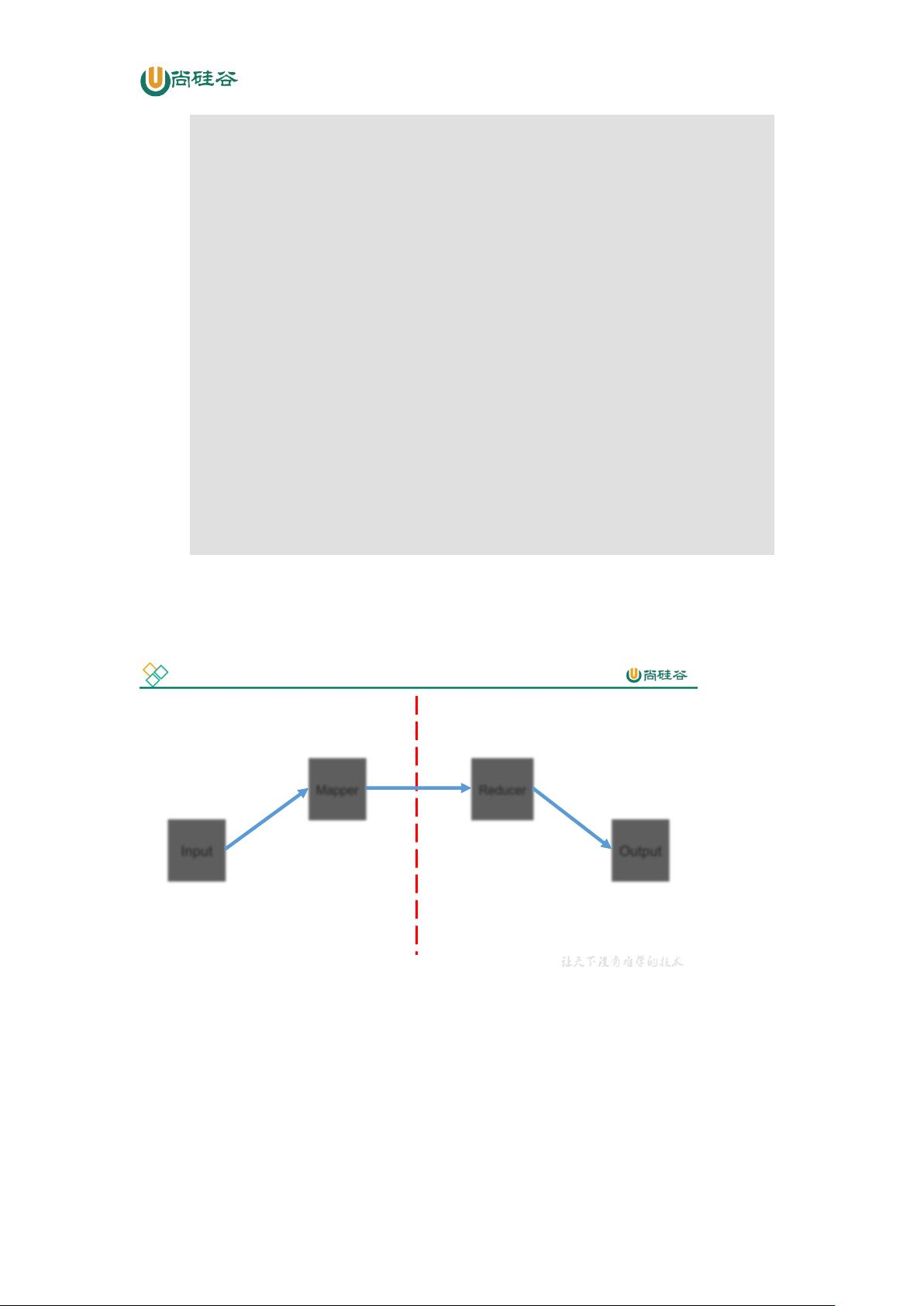
Hadoop(MapReduce)是尚硅谷大数据技术中的一个分布式运算程序的编程框架。它能够将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并运行在一个Hadoop集群上。MapReduce的优点包括易于编程、良好的扩展性和高容错性。它的编程接口简单,用户可以用相同的方式编写分布式程序和串行程序,非常流行。同时,当计算资源不足时,可以通过增加机器来扩展计算能力。另外,MapReduce具有很高的容错性,如果集群中某台机器出现故障,可以将该机器上的计算任务转移到其他机器上完成,不会导致任务失败,并且这个过程完全由Hadoop内部自动完成。

尚硅谷大数据技术之 Hadoop(MapReduce)
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
}
(2)编写 Mapper 类
package com.atguigu.mapreduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowCountMapper extends Mapper<LongWritable,
Text, Text, FlowBean>{
FlowBean v = new FlowBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context
context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割字段
String[] fields = line.split("\t");
// 3 封装对象
// 取出手机号码
String phoneNum = fields[1];
// 取出上行流量和下行流量
long upFlow = Long.parseLong(fields[fields.length -
3]);
long downFlow = Long.parseLong(fields[fields.length -
2]);
k.set(phoneNum);
v.set(downFlow, upFlow);
// 4 写出
context.write(k, v);
}
}
(3)编写 Reducer 类
package com.atguigu.mapreduce.flowsum;
import java.io.IOException;

剩余130页未读,继续阅读
2018-11-29 上传
2022-08-03 上传
2019-11-02 上传
2019-05-28 上传
2022-08-04 上传
2021-12-31 上传
2022-08-03 上传
点击了解资源详情

wxb0cf756a5ebe75e9
- 粉丝: 27
- 资源: 283
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
