飞桨OCR工具库PaddleOCR的安装与应用教程
需积分: 2 97 浏览量
更新于2024-08-03
收藏 2.8MB PPTX 举报
PaddleOCR是基于飞桨(PaddlePaddle)开发的高级OCR(Optical Character Recognition,光学字符识别)工具库,它专注于提供高效、易用的文本检测和识别功能。该工具特别适合于中英文数字组合、竖排文本以及长文本的识别任务,具有轻量化的特点,其基础模型仅有8.6M大小,适合资源受限的环境。
该项目不仅包含了基础的识别算法,还支持多种先进的OCR技术,使得开发者能够在此基础上扩展并创建适应特定应用场景的产业级特色模型,如PP-OCR和PP-Structure。这表明PaddleOCR在设计上考虑了灵活性和可定制性,涵盖了数据生产、模型训练、压缩和部署的全流程,使得模型从研发到实际应用的整个过程更加便捷。
在安装方面,首先需要确保安装了Python(版本3.8及以上),推荐使用清华源进行包管理。对于GPU支持,虽然提供了cuda的安装选项,但建议直接安装非GPU版本的PaddlePaddle,即pip install paddlepaddle,或者安装特定版本的paddleocr(至少2.0.1版本)。如果在安装过程中遇到shapely的错误,可以从特定链接下载对应Python版本的whl文件进行安装。
安装完成后,可以使用命令行工具进行基本的OCR检测,例如通过`paddleocr --image_dir <图片目录> --use_angle_clstrue --use_gpufalse`来识别指定目录中的图片。另外,也提供了Python编程接口,通过导入PaddleOCR模块,读取图像,设置识别参数(如是否使用角度分类和GPU),然后调用`ocr`函数进行识别,获取识别结果并打印出来。
`from paddleocr import PaddleOCR
from PIL import Image
import numpy as np
image = Image.open('<图片路径>')
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False)
text = ocr.ocr(np.asarray(image), cls=True)
for result in text[0]:
print(result[1])`
PaddleOCR的使用方法非常直观,无论是命令行还是脚本编程,都能快速实现图像文字的识别,这在文档处理、自动化检测、机器视觉等领域有着广泛的应用潜力。PaddleOCR是一个功能强大且易于集成的OCR工具,有助于提升文本识别任务的效率和准确性。
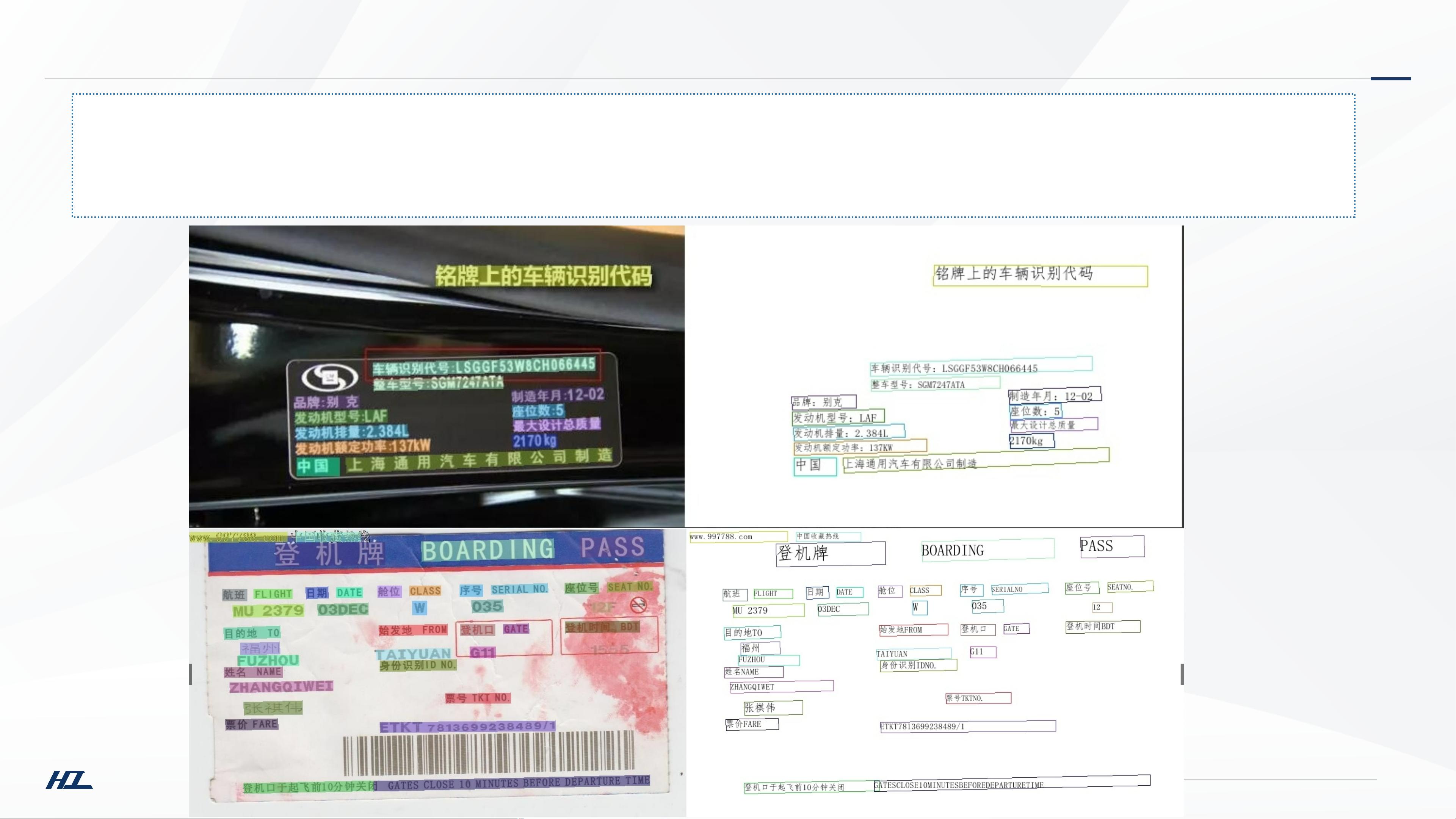
治 嘉 · 利 国 · 通 天 下
哈工智慧嘉利通
项目介绍
https://gitee.com/paddlepaddle/PaddleOCR
基于飞桨的OCR工具库,包含总模型仅8.6M的超轻量级中文OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同
时支持多种文本检测、文本识别的训练算法
下载后可阅读完整内容,剩余6页未读,立即下载
2021-12-01 上传
2021-12-22 上传
2023-08-24 上传
2024-04-09 上传
2023-04-12 上传
2023-05-12 上传
2024-05-08 上传
2023-08-19 上传
2023-04-14 上传

yuxiangyu
- 粉丝: 6
- 资源: 48
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
