CUDA编程入门:并行模型与API详解
需积分: 35 26 浏览量
更新于2024-07-22
收藏 1.8MB DOC 举报
CUDA教程文档提供了一种针对NVIDIA GPU的高效并行编程方法,它扩展了C语言,专为那些熟悉标准编程语言的开发者设计。CUDA(Compute Unified Device Architecture)是计算统一设备架构,旨在利用GPU的高度并行性和多核处理器能力来加速计算密集型任务。
第1章介绍了CUDA的基本概念,包括CUDA作为一个可伸缩的并行编程模型,以及GPU的特点,如其多线程和多核的特性。文档结构清晰,让读者能够逐步理解CUDA的体系和组织方式。
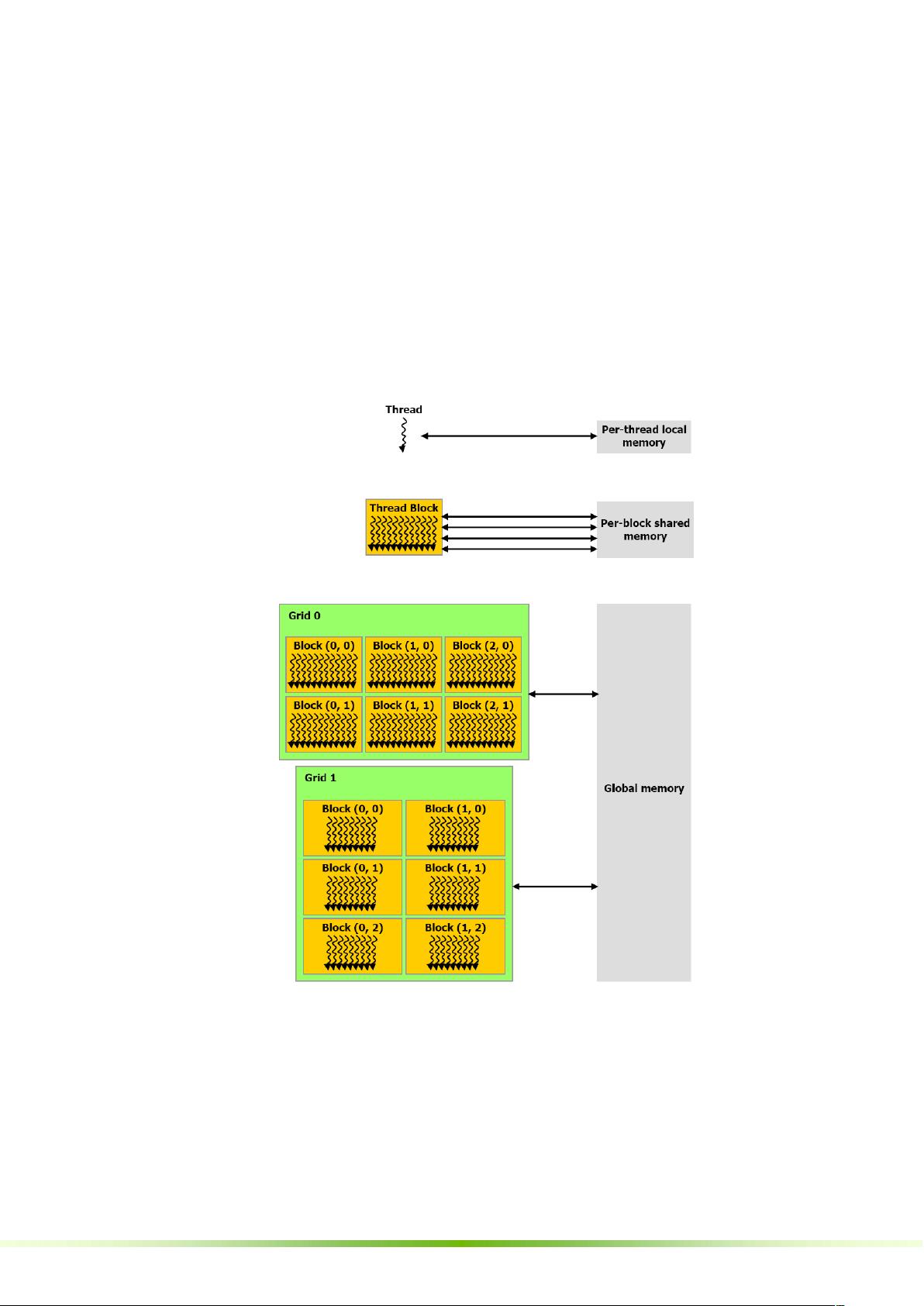
在第2章中,编程模型的核心概念被深入剖析。线程层次结构和存储器层次结构是理解CUDA编程的关键,前者定义了线程如何组织和协同工作,后者展示了设备内存的不同类别,如全局内存、共享内存和常量内存。此外,本章还涵盖了主机(CPU)与设备(GPU)之间的交互,以及软件栈的构成,包括驱动程序、CUDA runtime API和CUDA编程库。
第3章详细讨论了GPU硬件的实现,包括带有芯片共享存储器的SIMT(Single Instruction Multiple Thread)多处理器,以及多个设备间的连接和模式切换。理解这些底层细节有助于开发者优化性能和充分利用GPU资源。
第4章主要介绍了CUDA的API(应用程序编程接口),包括对C语言的扩展特性。C++程序员可以利用`_device_`、`_global_`、`_host_`等限定符来区分代码将在何处执行,以及变量的不同存储类型。此外,章节还讲解了执行配置参数,如gridDim(网格维度)、blockIdx(块索引)和threadIdx(线程索引)等,这些都是控制并行执行的重要工具。编译选项,如`_noinline_`和`#pragma unroll`,也被提及,以优化代码性能。通用运行时组件部分介绍了CUDA提供的向量类型、数学函数、计时功能和纹理处理能力,这些都是编写高性能CUDA程序不可或缺的部分。
这本教程文档提供了全面的指导,从CUDA的基础概念到高级编程技巧,帮助开发者有效地将CPU密集型任务迁移到GPU上,显著提升计算性能。无论是初学者还是经验丰富的开发者,都能从中获益匪浅。

第 2 章 编程模型
CUDA 允许程序员定义称为内核(kernel)的 C 语言函数,从而扩展了 C 语言,在调用此类函数时,它将
由 N 个不同的 CUDA 线程并行执行 N 次,这与普通的 C 语言函数只执行一次的方式不同。
在定义内核时,需要使用 _global_ 声明说明符,使用一种全新的 <<<…>>> 语法指定每次调用的 CUDA
线程数:
// Kernel definition
__global__ void vecAdd(float* A, float* B, float* C)
{
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}
执行内核的每个线程都会被分配一个独特的线程 ID,可通过内置的 threadIdx 变量在内核中访问此 ID。
以下示例代码将大小为 N 的向量 A 和向量 B 相加,并将结果存储在向量 C 中:
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}
执行 vecAdd( ) 的每个线程都会执行一次成对的加法运算。
2.1 线程层次结构
为方便起见,我们将 threadIdx 设置为一个包含 3 个组件的向量,因而可使用一维、二维或三维缩影标识
线程,构成一维、二维或三维线程块。这提供了一种自然的方法,可为一个域中的各元素调用计算,如
向量、矩阵或字段。下面的示例代码将大小为 NxN 的矩阵 A 和矩阵 B 相加,并将结果存储在矩阵 C 中:
__global__ void matAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
// Kernel invocation
dim3 dimBlock(N, N);
matAdd<<<1, dimBlock>>>(A, B, C);
}
线程的索引及其线程 ID 有着直接的关系:对于一维块来说,两者是相同的;对于大小为 (D
x
,
D
y
) 的二维
块来说,索引为 (x,y) 的线程的 ID 是 (x + yD
x
);对于大小为 (D
x
,
D
y
,
D
z
) 的三维块来说,索引为
(x, y, z) 的线程的 ID 是 (x + yD
x + Z
D
x
D
y
)。
4 CUDA 编程指南,版本 2.0

剩余63页未读,继续阅读
2009-09-13 上传
2009-12-06 上传
2018-04-24 上传
2010-03-21 上传
2024-04-20 上传
2013-03-02 上传
2017-03-13 上传
点击了解资源详情
2023-03-16 上传

冬瓜子
- 粉丝: 47
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
