理解SVM:从八股到核心原理
需积分: 9 37 浏览量
更新于2024-07-30
收藏 376KB DOC 举报
"SVM入门知识讲解"
支持向量机(Support Vector Machine,简称SVM)是一种强大的监督学习算法,由Cortes和Vapnik在1995年提出,主要用于分类和回归分析。SVM的核心理念在于找到一个最优的决策边界,最大化数据点与边界之间的间隔,从而实现对未知数据的有效预测。
SVM的理论基础包括统计学习理论的VC维理论和结构风险最小化原则。VC维是评估模型复杂度的重要指标,它表示一个模型能够正确分类的最多样本数量。对于高VC维的模型,过拟合的风险增加,而低VC维模型可能无法捕捉数据的复杂性。SVM的优势在于,即使面对高维数据,也能通过寻找支持向量(离决策边界最近的数据点)来构建有效的低维决策边界,因此它对样本维度的依赖性较低。
结构风险最小化是SVM优化目标的关键,它意味着在保证模型的泛化能力的同时,尽可能降低在训练集上的误差。换句话说,SVM不仅追求在训练集上的高准确率,更注重模型对新数据的预测能力。这与传统的过拟合和欠拟合概念相呼应,SVM试图找到一个平衡点,既能充分利用训练数据,又不会过度依赖特定样本。
在SVM中,核函数是一个至关重要的概念。核函数能够将原始数据映射到高维空间,使得在原始空间中非线性可分的数据在高维空间中变得线性可分。常用的核函数有线性核、多项式核、高斯核(RBF)等,它们的选择直接影响到SVM的性能。
在实际应用中,SVM广泛应用于文本分类、图像识别、生物信息学等领域。例如,在文本分类中,每个文档可以被表示为一个高维特征向量,SVM通过核函数处理这些高维数据,构建出有效的分类模型。
SVM的训练过程通常涉及选择合适的参数,如惩罚项C(控制模型的复杂度)和核函数的参数γ(影响决策边界的形状)。通过交叉验证等方法,可以调整这些参数以达到最优的泛化性能。
SVM是一种基于统计学习理论的高效机器学习工具,它以优化决策边界和最大化间隔为目标,结合核函数处理高维数据,具有良好的泛化能力和适应性。对于初学者来说,理解和掌握SVM的基本原理和应用,能够为后续的深度学习和数据挖掘奠定坚实的基础。

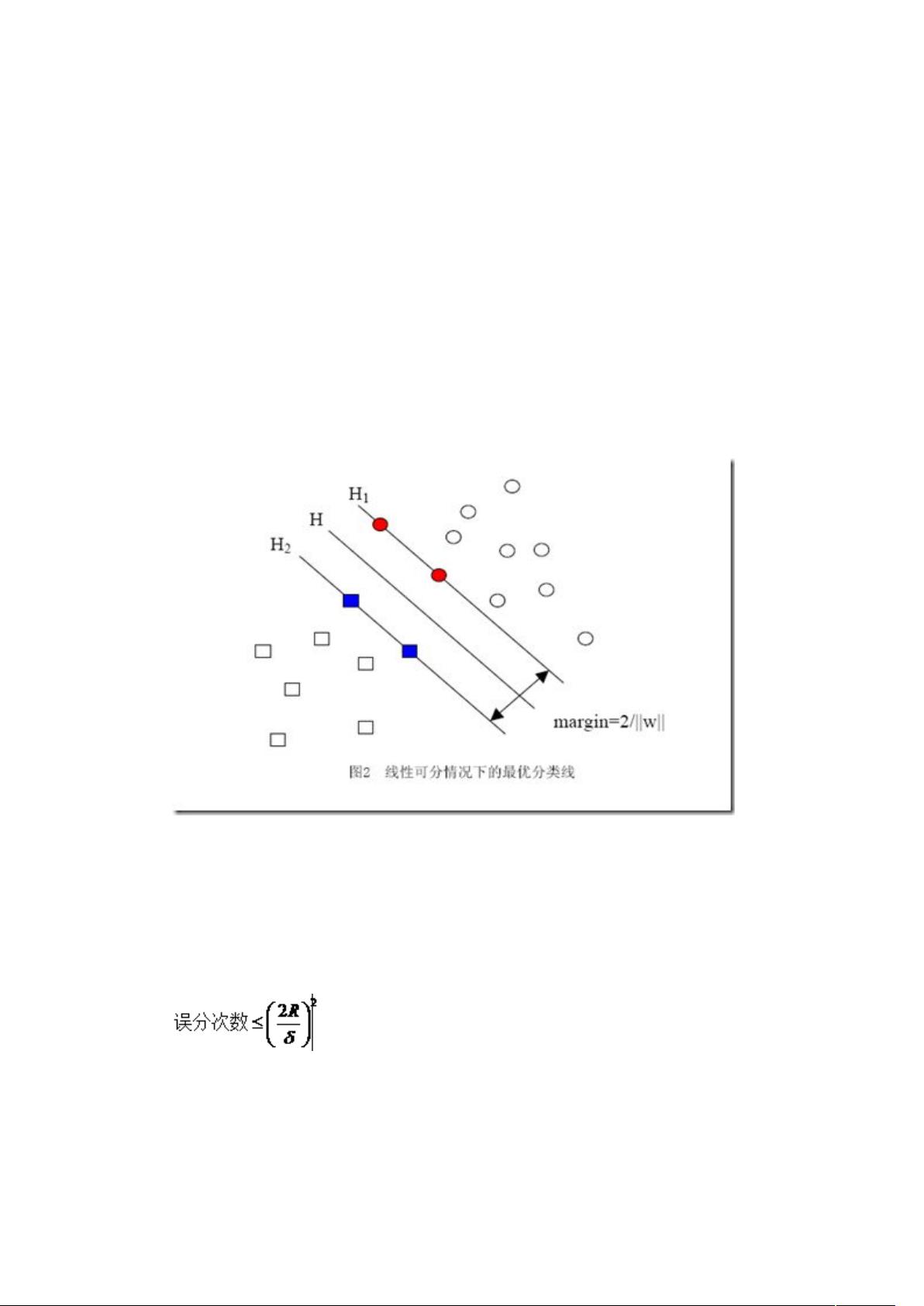
在二元的线性分类中,这个表示分类的标记只有两个值,1 和-1(用来表示属于还是
不属于这个类)。有了这种表示法,我们就可以定义一个样本点到某个超平面的间隔:
δi=yi(wxi+b)
这个公式乍一看没什么神秘的,也说不出什么道理,只是个定义而已,但我们做做变
换,就能看出一些有意思的东西。
首先注意到如果某个样本属于该类别的话,那么 wxi+b>0(记得么?这是因为我们所
选的 g(x)=wx+b 就通过大于 0 还是小于 0 来判断分类),而 yi 也大于 0;若不属于该类别
的话,那么 wxi+b<0,而 yi 也小于 0,这意味着 yi(wxi+b)总是大于 0 的,而且它的值就等
于|wxi+b|!(也就是|g(xi)|)
现在把 w 和 b 进行一下归一化,即用 w/||w||和 b/||w||分别代替原来的 w 和 b,那么间
隔就可以写成
这个公式是不是看上去有点眼熟?没错,这不就是解析几何中点 xi 到直线 g(x)=0 的距
离公式嘛!(推广一下,是到超平面 g(x)=0 的距离, g(x)=0 就是上节中提到的分类超平
面)
小 Tips:||w||是什么符号?||w||叫做向量 w 的范数,范数是对向量长度的一种度量。
我们常说的向量长度其实指的是它的 2-范数,范数最一般的表示形式为 p-范数,可以写成
如下表达式
向量 w=(w1, w2, w3,…… wn)
它的 p-范数为
剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-07-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

xumg2007
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
