Hadoop HDFS知识精要:设计与概念解析
180 浏览量
更新于2024-08-27
收藏 293KB PDF 举报
"本文总结了HDFS的关键知识点,包括HDFS的定义、设计原则、数据块概念、节点类型、HDFS联邦以及高可用性特性。"
HDFS,全称Hadoop分布式文件系统,是一种大规模分布式存储系统,专为处理大规模数据而设计。它以流式数据访问模式存储超大文件,适应于商业硬件环境,允许文件跨越多台计算机存储。然而,HDFS并不适合需要低延迟数据访问、存储大量小文件或支持多用户写入和随意修改文件的场景。
HDFS的核心设计之一是数据块。文件被分割成固定大小的数据块,默认为64MB,便于在集群中的不同节点间分散存储。这种设计提高了存储效率,允许文件超过单个磁盘容量,并且支持数据冗余备份,增强了系统的容错性和可用性。用户可以通过HDFS命令行工具查看文件的数据块信息。
HDFS的运行依赖于三种核心节点:Namenode、Datanode和SecondaryNamenode。Namenode是整个文件系统的元数据管理者,它存储文件系统命名空间和数据块映射信息。Datanode是实际存储数据的地方,它们向Namenode报告存储的块信息,并按需提供数据读写服务。SecondaryNamenode并非备用的Namenode,而是协助主Namenode定期保存元数据快照,防止数据丢失。
为了提高可扩展性和可用性,HDFS引入了Federation(联邦)机制。在HDFS联邦中,多个Namenode各自管理文件系统命名空间的一部分,每个Namenode负责一部分文件和数据块,这降低了单一Namenode的压力,增强了系统的整体性能。
HDFS的高可用性(HA)特性是通过设置一对活动-备用的Namenode实现的。正常情况下,活动Namenode处理所有客户端请求,而备用Namenode处于监控状态。一旦活动Namenode出现故障,备用Namenode能快速接管,确保服务的连续性,从而避免了单点故障的问题。
HDFS是大数据处理的重要基础设施,其设计理念和特性使得它能够高效、可靠地处理海量数据,是Hadoop生态系统中的关键组成部分。理解HDFS的工作原理对于开发、管理和优化大规模数据处理系统至关重要。
HDFS知识点总结知识点总结
学习完Hadoop权威指南有一段时间了,现在再回顾和总结一下HDFS的知识点。
1、HDFS的设计
HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,
运行于商用硬件集群上,是管理网络中跨多台计算机存储的文件系统。
HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。
2、HDFS的概念
HDFS数据块:HDFS上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块,默认大小是64MB。
使用数据块的好处是:
一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块不需要存储在同一个磁盘上,因此它们可以利用集群上的
任意一个磁盘进行存储。
简化了存储子系统的设计,将存储子系统控制单元设置为块,可简化存储管理,同时元数据就不需要和块一同存储,用一个单
独的系统就可以管理这些块的元数据。
数据块适合用于数据备份进而提供数据容错能力和提高可用性。
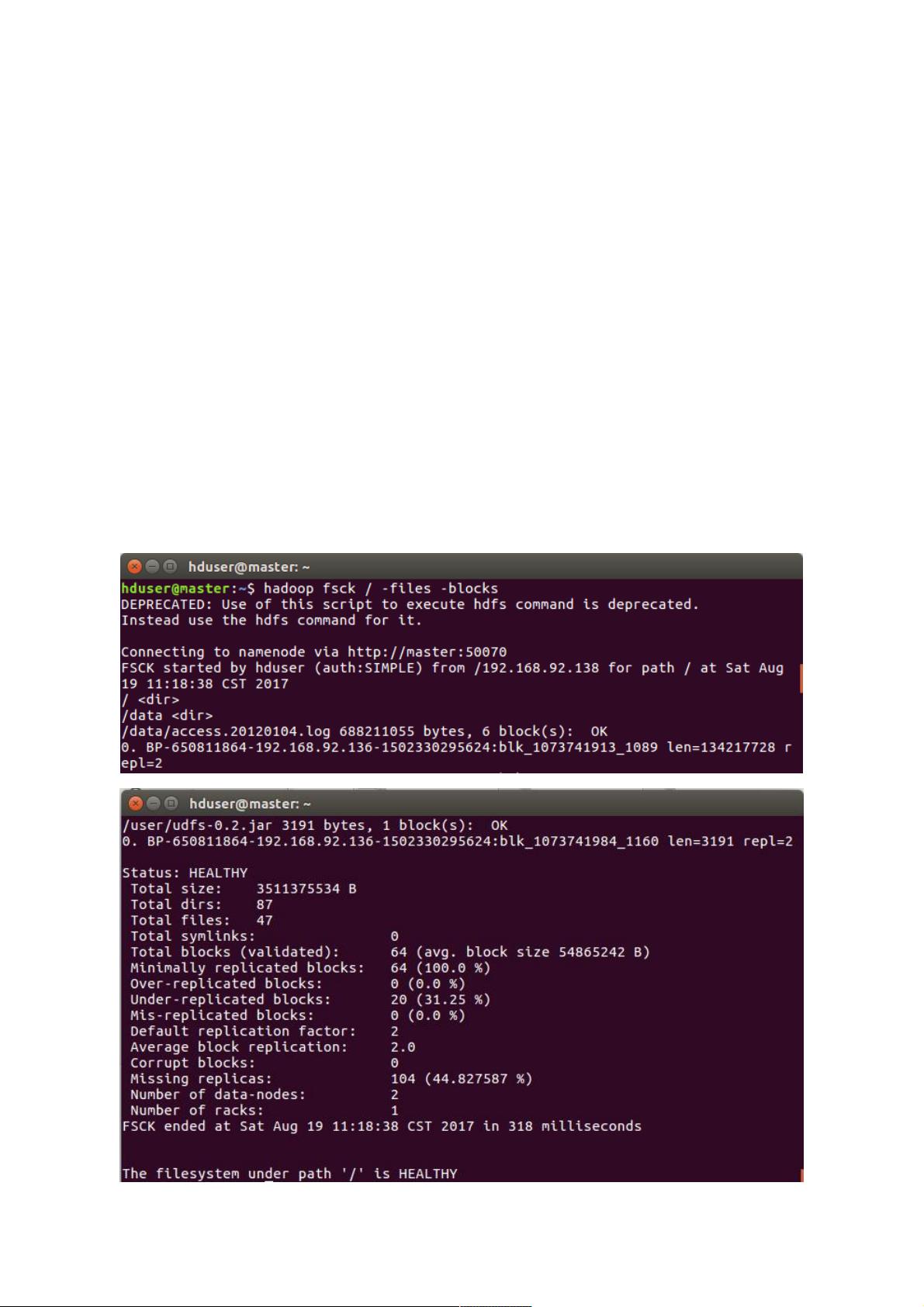
查看块信息
HDFS的三个节点:Namenode,Datanode,Secondary Namenode
Namenode:HDFS的守护进程,用来管理文件系统的命名空间,负责记录文件是如何分割成数据块,以及这些数据块分别被
下载后可阅读完整内容,剩余7页未读,立即下载
5123 浏览量
2024-12-15 上传
101 浏览量
119 浏览量
2023-09-16 上传
2022-11-24 上传
2022-11-24 上传
2022-11-24 上传









