
够自学一些外部工具(例如搜索引擎、计算器、维基百科)的使用,主要是让语言模型学会
根据实际情况选择合适的 API 并根据反馈生成更可信的答案。
论文还研究了模型参数量对学习工具能力的影响,发现参数到达 775M 以上时使用工具才能
明显地提升回答质量(换句话说这时模型才学会正确用工具),也说明有些能力确实只有当
模型足够大时才会“解锁”。
当然,这篇论文做的只有单 API 调用,不会同时在使用一个工具时再套娃使用另一个工具
(例如不能同时用日历获取当前日期再用计算器做一个减法获取某个新日期),也不会和
API 做交互。
8.Theory of Mind May Have Spontaneously Emerged in Large Language Models
这是一篇认为大语言模型可能出现心智的论文,前段时间在公众号之间传的比较广。这篇论
文使用了 ToM(Theory of mind)任务进行测试,发现小模型很难通过这项测试,而 GPT-3
可以通过部分 70%的测试,ChatGPT 可以通过 93%的测试,似乎表明它们已经具有心智,并
且论文认为这些心智是自发地出现的。
所谓自发,在文中主要指模型具有的心智并不是我们在设计模型时可以去设计的,而只是最
终产生模型的一个副产物而已。这个结论某种程度上还挺恐怖的,似乎人的智能的出现也只
是单纯地因为语言发展而自发出现的,并没有任何神秘感。
实验所采用的 ToM 任务有:(1)意外内容任务(因标签错误导致的信念错误)。实验表明
GPT-3.5 确实可以根据语境判断一个人的心理状态;(2)意外转移任务(因事物变化导致的
信念错误)。实验证明 GPT-3.5 正确预测了主人公会遵从自己的错误信念而不是基于真正的
事实做出预测;(3)类-心智理论能力。基于(1)和(2)的变种测试
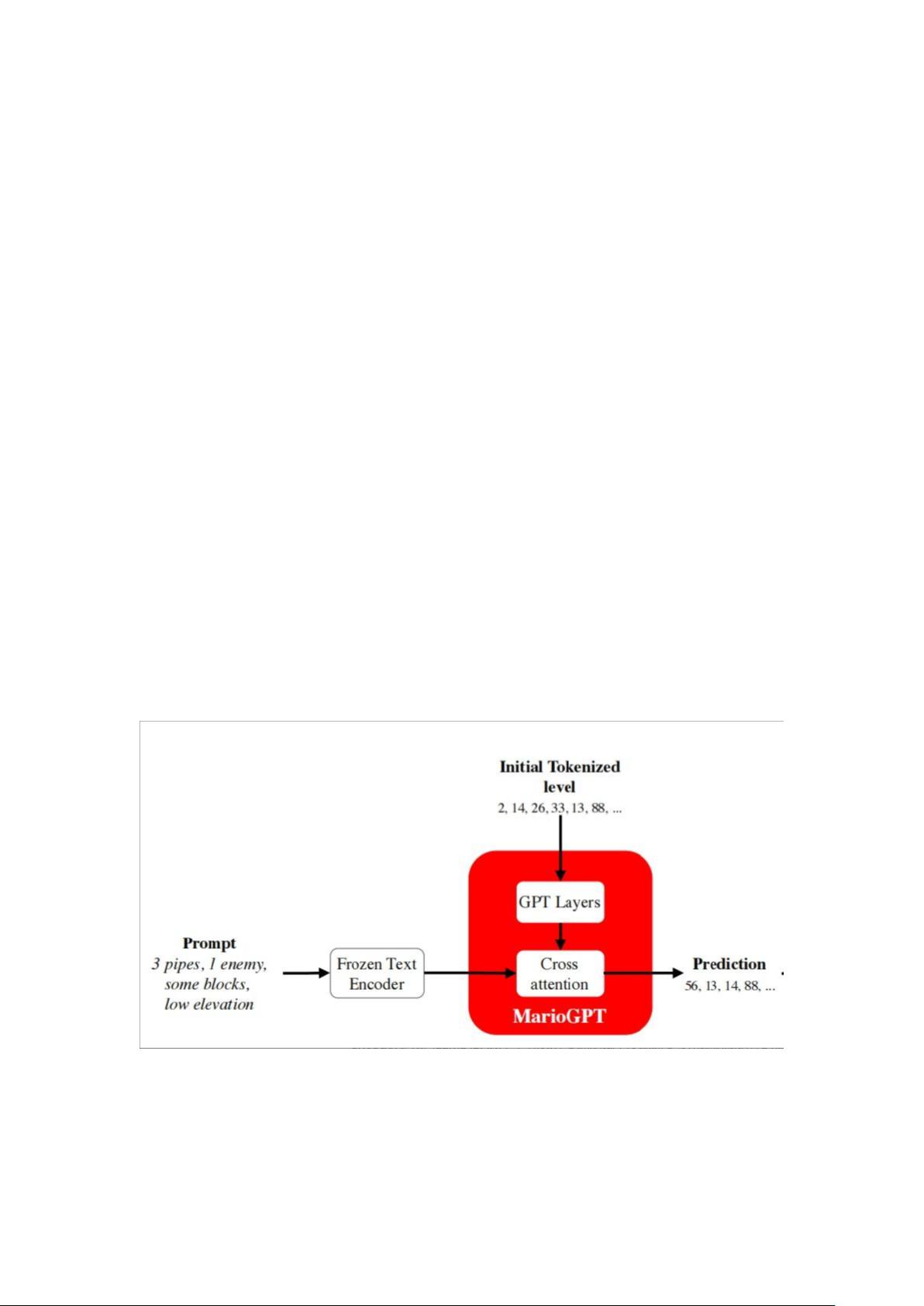
9.MarioGPT: Open-Ended Text2Level Generation through Large Language Models
这是一篇借助于 GPT-2 生成马里奥关卡的论文,就像文字生成图像一样,是通过文字生成关
卡。
整体架构如下,简单来说 prompt 是关卡描述,输出是字符串形式,再转化为关卡(Frozen Text
Encoder 是双向 LLM 的 BART),所以在实际测试中发现确实会出现贴图错位的情况。
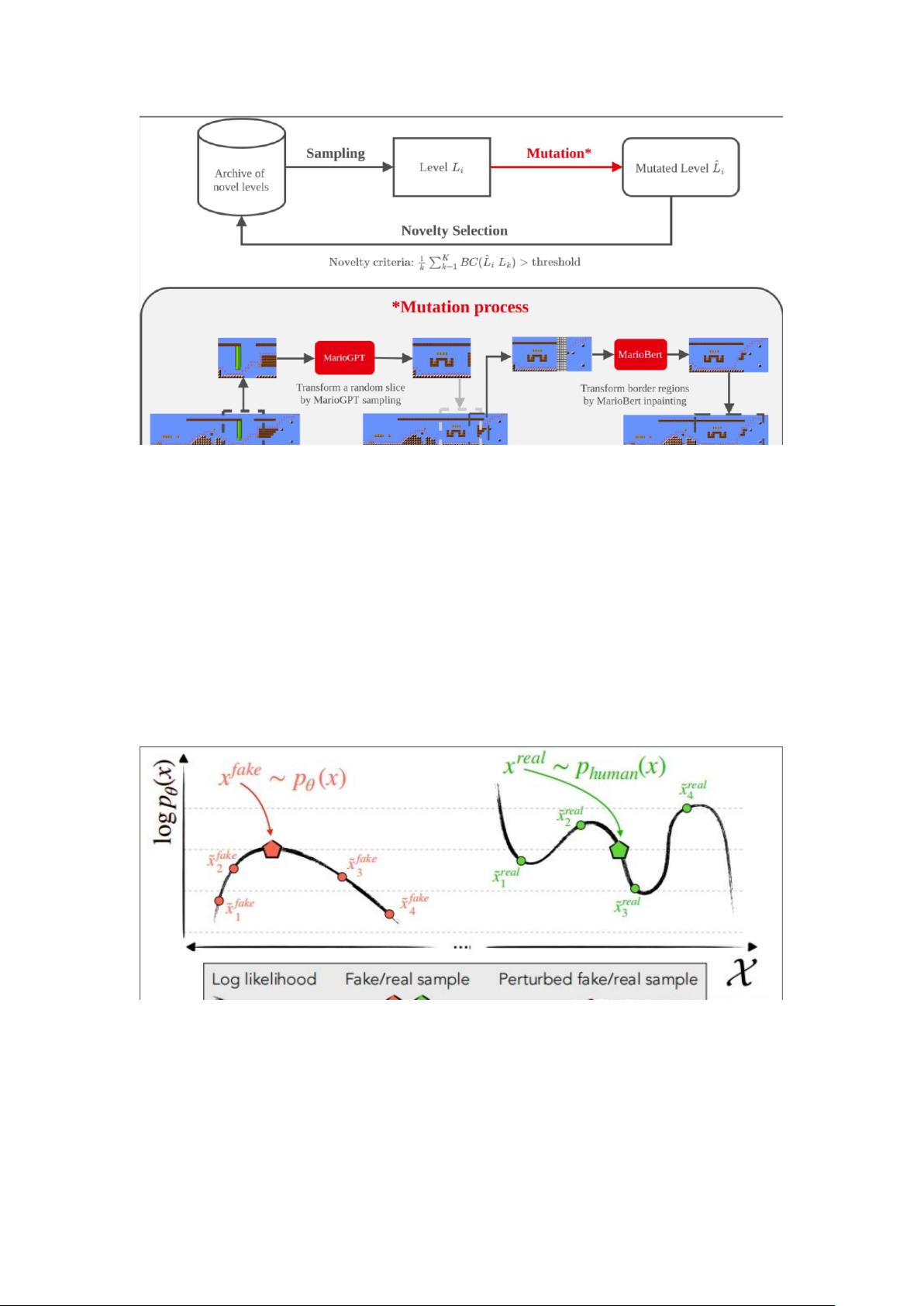
此外,算法还使用了新颖性搜索(novelty search,好像是遗传算法的改进版本):
剩余25页未读,继续阅读

萧鼎
- 粉丝: 2w+
- 资源: 89
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 利用迪杰斯特拉算法的全国交通咨询系统设计与实现
- 全国交通咨询系统C++实现源码解析
- DFT与FFT应用:信号频谱分析实验
- MATLAB图论算法实现:最小费用最大流
- MATLAB常用命令完全指南
- 共创智慧灯杆数据运营公司——抢占5G市场
- 中山农情统计分析系统项目实施与管理策略
- XX省中小学智慧校园建设实施方案
- 中山农情统计分析系统项目实施方案
- MATLAB函数详解:从Text到Size的实用指南
- 考虑速度与加速度限制的工业机器人轨迹规划与实时补偿算法
- Matlab进行统计回归分析:从单因素到双因素方差分析
- 智慧灯杆数据运营公司策划书:抢占5G市场,打造智慧城市新载体
- Photoshop基础与色彩知识:信息时代的PS认证考试全攻略
- Photoshop技能测试:核心概念与操作
- Photoshop试题与答案详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


