软约束监督哈希方法
65 浏览量
更新于2024-08-26
收藏 516KB PDF 举报
"这篇研究论文探讨了具有软约束的监督哈希方法,旨在解决现有监督哈希技术中的两个主要问题:过于强调最大化汉明距离可能导致相似样本编码相同,以及未充分考虑语义差距导致监督信息利用不足。作者提出了一种通用框架,采用软约束作为正则化手段,以避免过拟合,并对不同标签对赋予不同的重要性权重,以更有效地利用监督信息。"
正文:
监督哈希(Supervised Hashing)是一种在计算机视觉、信息检索和大数据等领域广泛应用的技术。它的核心思想是将高维数据转换成紧凑的二进制编码(或称为哈希码),同时保持原始数据之间的相似性关系。通过在汉明空间中保持相似度,可以显著提高大规模数据的存储效率和检索速度。
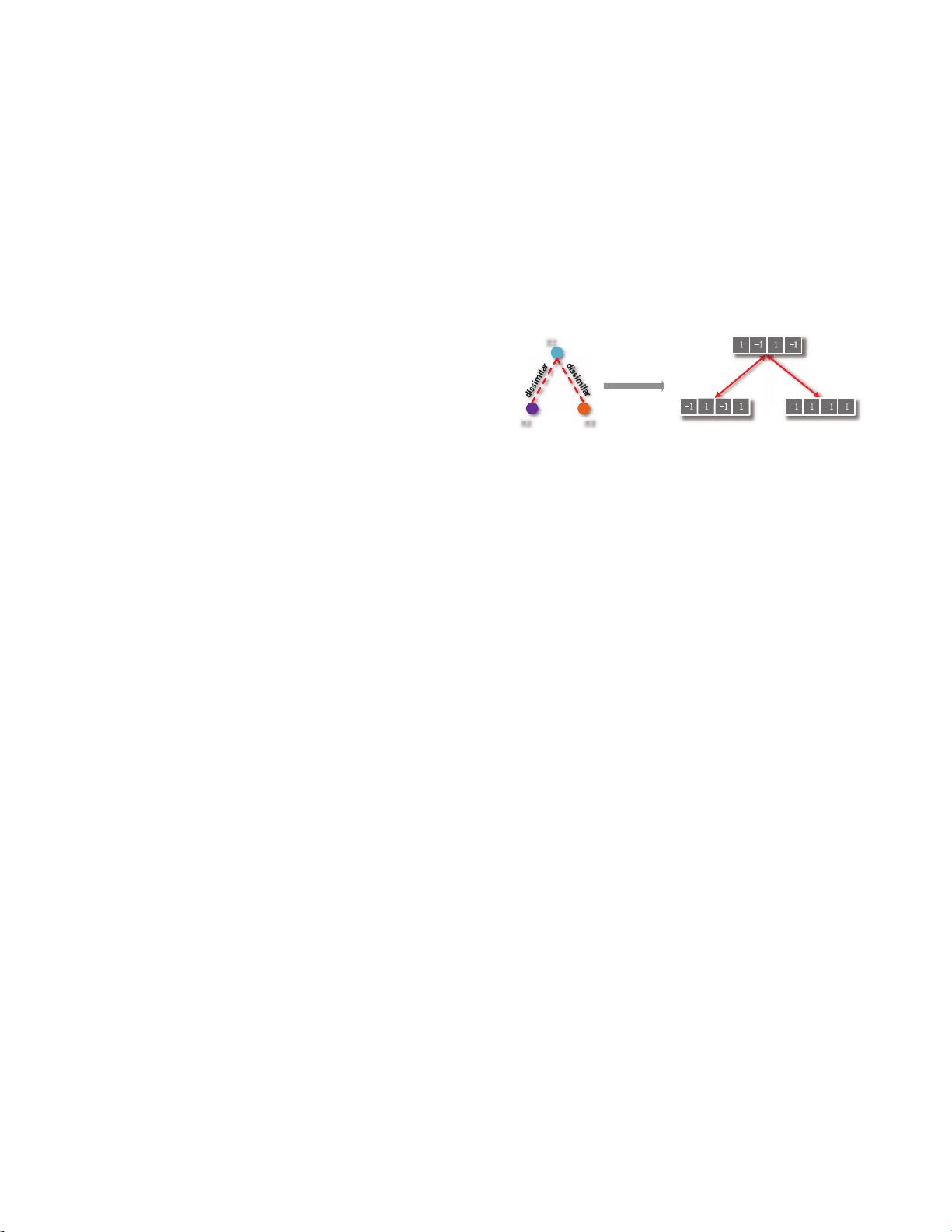
然而,现有的监督哈希方法通常存在两个局限性。首先,它们通常追求最大化不同样本间的汉明距离,期望不相似的样本在哈希编码上差异最大。这种做法可能导致两个实际上并不相似的样本获得相同的编码,如果它们都与另一个样本不相似。其次,传统方法对所有有标签的样本对一视同仁,没有考虑到语义差距,这限制了对监督信息的充分利用。
针对这些问题,论文“Supervised Hashing with Soft Constraints”提出了一种新的框架。在这个框架中,作者不再严格要求不相似的样本必须有最大的汉明距离。相反,他们引入了软约束(Soft Constraint)的概念,这个软约束可以看作是防止模型过拟合的一种正则化策略。通过这种方式,模型可以在保持整体结构的同时,允许一定的灵活性,避免对某些特定样本对的过度适应。
此外,论文还考虑了标签对的重要性差异。作者提出对不同标签对赋予不同的权重,以反映它们在语义上的差距。这种方法使得模型能够更好地理解和利用监督信息,尤其是在处理语义差距较大的样本对时,可以更加精确地学习哈希函数。
这项工作为监督哈希提供了新的视角,通过软约束和差异化的权重处理,提升了哈希编码的质量和模型的泛化能力,对于提升大规模数据检索的性能和准确性具有重要的理论与实践价值。
Supervised Hashing with Soft Constraints
Cong Leng, Jian Cheng, Jiaxiang Wu, Xi Zhang, Hanqing Lu
National Laboratory of Pattern Recognition
Institute of Automation, Chinese Academy of Sciences
Beijing, China
{cong.leng, jcheng, jiaxiang.wu, zhangxi, luhq}@nlpr.ia.ac.cn
ABSTRACT
Due to the ability to preserve semantic similarity in Ham-
ming space, supervised hashing has been extensively studied
recently. Most existing approaches encourage two dissimilar
samples to have maximum Hamming distance. This may
lead to an unexpected consequence that two unnecessarily
similar samples would have the same code if they are both
dissimilar with another sample. Besides, in existing method-
s, all labeled pairs are treated with equal importance with-
out considering the semantic gap, which is not conducive to
thoroughly leverage the supervised information. We present
a general framework for supervised hashing to address the
above two limitations. We do not toughly require a dissim-
ilar pair to have maximum Hamming distance. Instead, a
soft constraint which can be viewed as a regularization to
avoid over-fitting is utilized. Moreover, we impose differen-
t weights to different training pairs, and these weights can
be automatically adjusted in the learning process. Experi-
ments on two benchmarks show that the proposed method
can easily outperform other state-of-the-art methods.
Categories and Subject Descriptors
H.3.3 [Information Systems]: Information Search and Re-
trieval
Keywords
Supervised Hashing; Soft Constraints; Weights; Bo osting
1. INTRODUCTION
Hashing based approximate nearest neighbor (ANN) search
methods have attracted much attention recently. Hashing
methods map the two nearby points in the original space
to close binary codes in a compact Hamming space. This
enables very fast searching since Hamming distance can b e
efficiently calculated with XOR operation in modern CPU.
According to whether supervised information is utilized or
not in the training process, hashing methods can be divided
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full cita-
tion on the first page. Copyrights for components of this work owned by others than
ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or re-
publish, to post on servers or to redistribute to lists, requires prior specific permission
and/or a fee. Request permissions from permissions@acm.org.
CIKM’14, November 3–7, 2014, Shanghai, China.
Copyright 2014 ACM 978-1-4503-2598-1/14/11 ...$15.00.
http://dx.doi.org/10.1145/2661829.2661937.
X1
X2 X3
(a) The labeled data
Hashing with
hard constraints
code of X1
code of X2 code of X3
max dis.: 4max dis.: 4
(b) Optimized hashing code
Figure 1: Paradox in traditional supervised Hashing
methods. Two unnecessarily similar data x
2
and x
3
will have the same code.
into unsupervised and supervised categories. In the unsu-
pervised setting, hashing methods such as Locality Sensitive
Hashing (LSH) [1] and Iterative Quantization (ITQ) [2] at-
tempt to preserve the data similarity defined in Euclidean
space, e.g., l
2
distance. However, this is not sufficient for
various practical applications such as image retrieval, where
semantically similar neighbors are preferred.
In order to construct efficient hash functions that pre-
serve the semantic similarity, supervised hashing methods
[3, 6, 5, 4, 7] have been extensively studied. The super-
vised information here is typically based on some pairwise
constraints, i.e., “A and B is similar” or “A and B is dis-
similar”, which is analogous to the “must link” and “cannot
link” constraints in metric learning [8]. Some representative
supervised hashing methods include Binary Reconstruction
Embedding (BRE) [3], Kernel Supervised Hashing (KSH) [5]
and Two Step Hashing (TSH) [4]. These sup ervised meth-
ods can be formally formulated with following objective [4]:
min
Φ
∑
(x
i
,x
j
)∈L
L (Φ(x
i
), Φ(x
j
); y
ij
) (1)
where Φ(x) ∈ {−1, 1}
r
is the r bits code of x. L(·) is a loss
function that measures how well the codes match the ground
truth y
ij
. Different algorithms corresponds to different loss
functions, for example, l
2
loss for BRE and KSH. Although
promising performance has been shown from these methods,
some limitations exist in them.
Inspired by metric learning, all these supervised meth-
ods attempt to learn codes whose Hamming distances are
minimized on similar pairs and simultaneously maximized
on dissimilar pairs. This principle is widely used in metric
learning and proved to be effective. However, metric learn-
ing executes in continuous real number space while hashing
executes in discrete Hamming space. Importantly, although
it makes sense in metric learning, we argue that maximiz-
1851
下载后可阅读完整内容,剩余3页未读,立即下载
2023-07-28 上传
2023-03-13 上传
2023-06-10 上传
2023-06-02 上传
2023-03-14 上传
2023-05-24 上传
2023-10-10 上传
2023-05-22 上传
2023-09-22 上传

weixin_38641764
- 粉丝: 3
- 资源: 921
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
