大数据与云计算教程:Spark入门及Scala解析
版权申诉
175 浏览量
更新于2024-07-07
收藏 3.07MB PPTX 举报
"该资源是一系列关于大数据与云计算的教程课件,涵盖了Hadoop、Spark、Neo4j等多个重要技术领域。课程包括了Hadoop的介绍、安装、MapReduce、YARN、HDFS等核心组件的讲解,以及Hive、HBase、Pig、Zookeeper、Sqoop、Flume、Kafka、Storm、SparkSQL、Oozie、Impala、Solr、Lily、Titan、Elasticsearch等大数据处理和分析工具的介绍。特别是其中的`32.Spark入门之Scala(共173页).pptx`,深入介绍了Scala编程语言,它是Spark的主要编程接口,具有面向对象和函数式编程的特性,并能与Java无缝集成。"
这篇课程旨在帮助学习者全面理解大数据处理的生态系统,从基础的Hadoop环境搭建到复杂的数据分析工具使用。Hadoop部分讲解了Hadoop的起源、核心组件如MapReduce的工作原理以及如何进行Hadoop的集群配置。MapReduce作为Hadoop的核心计算框架,涉及了其序列化、IO操作和高级应用开发。HDFS部分涵盖了文件系统的基本操作、Shell命令以及接口。
Spark是现代大数据处理的另一个关键工具,而Scala作为其主要编程语言,提供了强大的并行计算能力。Scala部分讲解了语言的特性,如面向对象和函数式编程的结合,以及如何利用Scala进行并发编程。Spark入门不仅限于Scala,还包括了Spark的基本概念和SparkSQL的使用,使得数据处理更加高效和灵活。
此外,课程还探讨了其他重要组件,如Zookeeper用于分布式协调,Hive提供了基于Hadoop的数据仓库解决方案,HBase是列族数据库,Pig提供了对大型数据集的高级脚本语言,Kafka是消息队列系统,Flume用于日志收集,Strom实时流处理,以及各种搜索和图数据库技术如Solr、Lily、Titan和Neo4j。
这些课程内容全面且深入,适合初学者和有一定经验的开发者,通过学习,可以提升大数据处理和云计算领域的专业技能,为实际项目开发打下坚实基础。

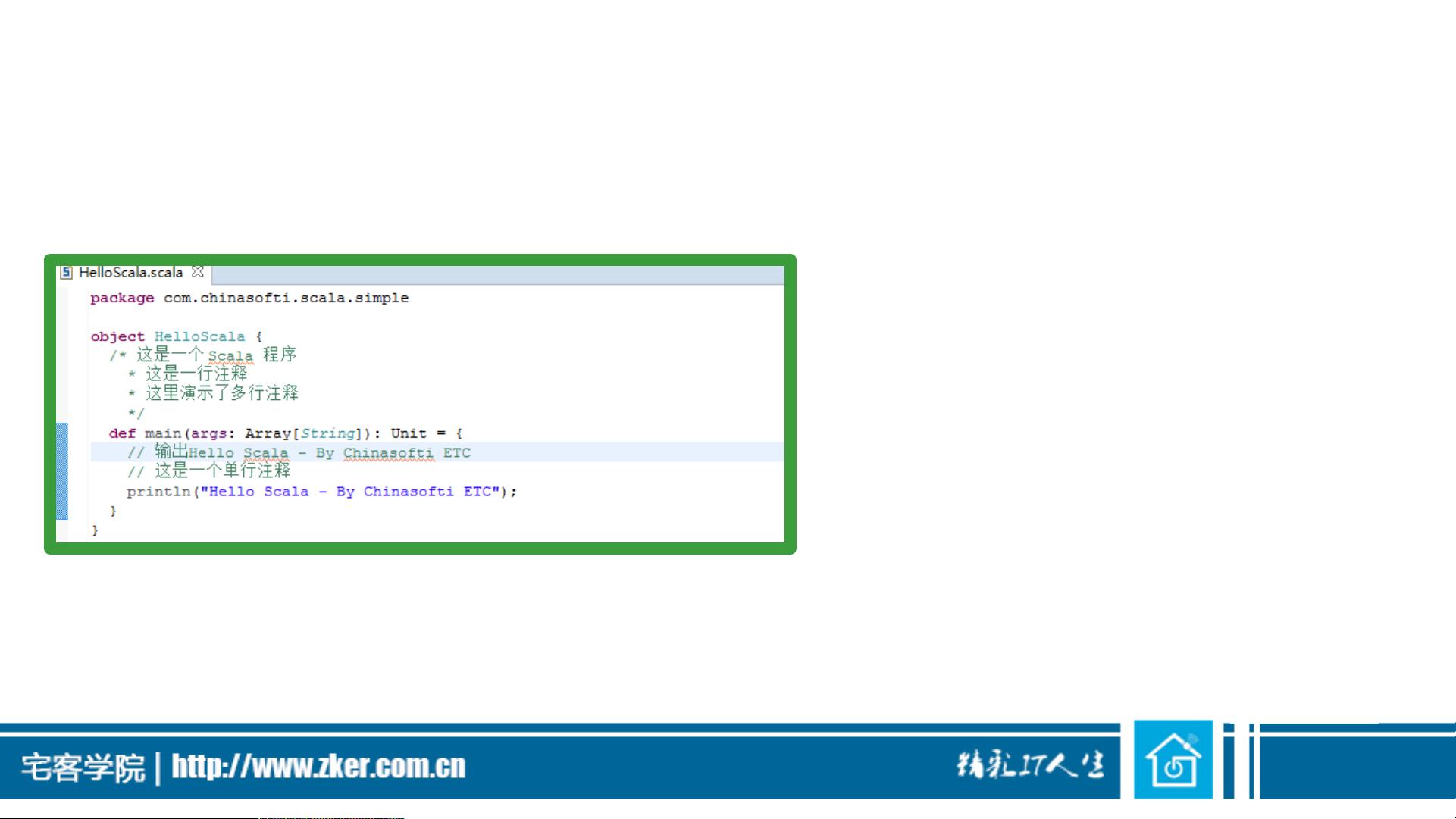
标识符
• Scala内部实现时会使用转义的标志符,比如:->使用
$colon$minus$greater来表示这个符号。因此如果需要在Java代码中
访问:->方法,需要使用Scala的内部名称$colon$minus$greater。
• 混合标志符由字符数字标志符后面跟着一个或多个符号组成,比如
unary_+为Scala对+方法的内部实现时的名称。
• 字面量标志符为使用’’定义的字符串,比如`x``yield`。
• 可以’’之间使用任何有效的Scala标志符,Scala将它们解释为一个
Scala标志符,一个典型的使用为Thread的yield方法,在Scala中不
能使用Thread.yield()是因为yield为Scala中的关键字,必须使用
Thread.`yield`()来使用这个方法。
•


剩余172页未读,继续阅读
2021-12-18 上传
2021-12-18 上传
2023-06-12 上传
2023-06-13 上传
2023-06-11 上传
2023-04-21 上传
2023-07-24 上传
2023-05-23 上传
2023-05-28 上传

passionSnail
- 粉丝: 448
- 资源: 6875
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
