ResNeSt:Split-Attention网络,提升ResNet性能
需积分: 32 49 浏览量
更新于2024-07-16
收藏 549KB PDF 举报
"ResNeSt Split-Attention Networks是ResNet的一种变形,它通过引入Split-Attention块提高了模型的性能,并且在保持ResNet结构的基础上,适用于各种下游任务,如对象检测和语义分割,而无需增加额外的计算成本。"
在计算机视觉领域,ResNet(残差网络)因其深度学习模型的简单性和模块化结构,长期以来一直是许多任务如图像分类、目标检测和语义分割的首选骨干网络。然而,随着技术的进步,研究者们一直在寻找能进一步提升性能的方法。ResNeSt(Split-Attention Networks)就是这样的一个创新,它由Hang Zhang等人提出,旨在增强ResNet的注意力机制。
Split-Attention块是ResNeSt的核心,其设计目的是允许特征图组之间的注意力交互。传统的自注意力机制通常会计算所有位置的全局依赖,这在计算上可能非常昂贵。相比之下,Split-Attention块将特征图分成多个分组,每个分组内部进行注意力计算,然后将这些分组的结果合并,这样既实现了注意力的分散,又降低了计算复杂性。
通过以ResNet风格堆叠这些Split-Attention块,ResNeSt网络得以构建。这种网络保留了ResNet的基本结构,可以直接用于下游任务,而且由于其优化的设计,不增加额外的计算负担。这使得ResNeSt在保持效率的同时,增强了模型的表达能力和适应性。
实验结果显示,ResNeSt模型在性能上优于其他具有相似模型复杂度的网络。例如,ResNeSt-50模型在使用单个224x224的图像裁剪尺寸时,能够在ImageNet数据集上达到81.13%的Top-1准确率,显示出其在图像分类任务上的强大能力。
此外,ResNeSt的优秀表现也体现在目标检测和语义分割等应用中,表明Split-Attention机制对于提升这些任务的性能同样有效。这使得ResNeSt成为研究人员和开发者在处理复杂视觉问题时的一个有力工具,特别是在需要平衡性能和计算效率的情况下。
ResNeSt Split-Attention Networks通过引入分组注意力机制,成功地增强了ResNet的性能,同时保持了易于使用和计算效率高的优点,是当前计算机视觉领域中值得探索和应用的网络架构之一。
ResNeSt: Split-Attention Networks 5
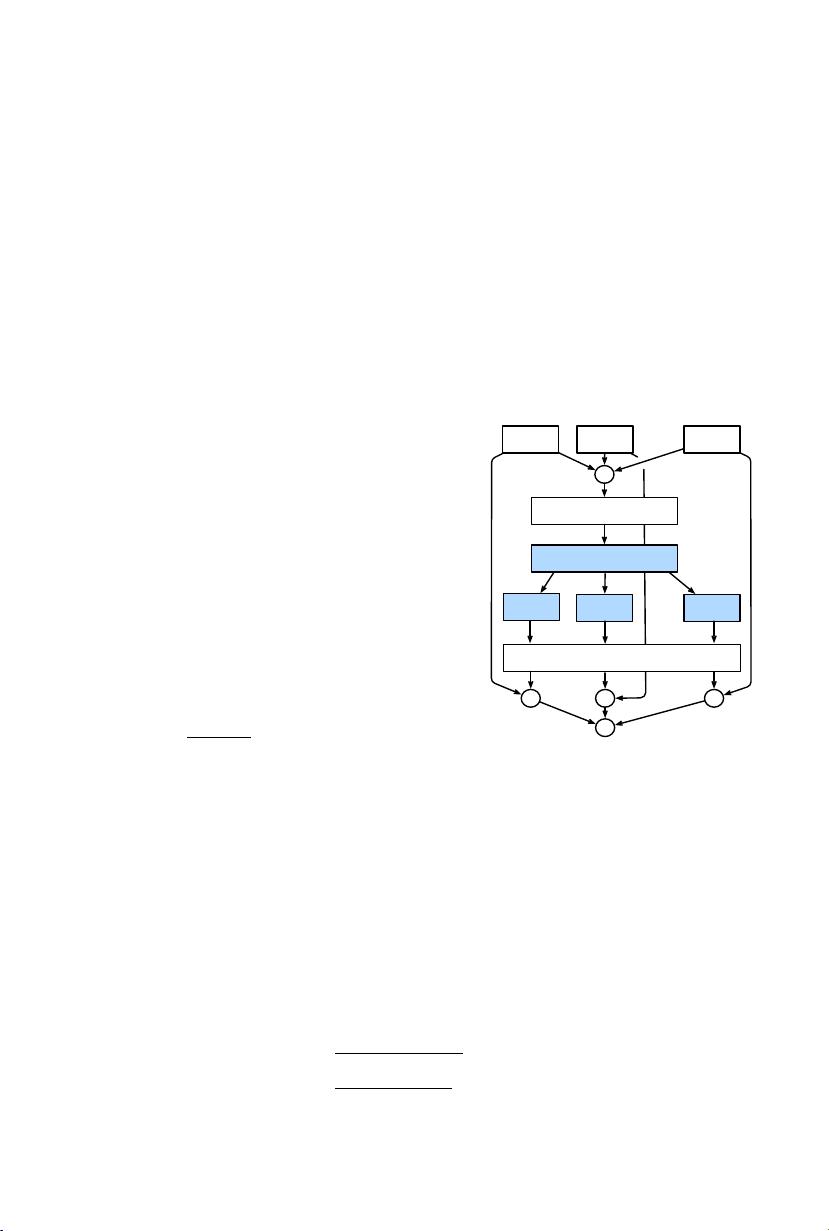
3.1 Split-Attention Block
Our Split-Attention block is a computational unit, consisting feature-map group
and split attention operations. Figure 1 (Right) depicts an overview of a Split-
Attention Block.
Feature-map Group. As in ResNeXt blocks [61], the input feature-map can
be divided into several groups along the channel dimension, and the number of
feature-map groups is given by a cardinality hyperparameter K. We refer to the
resulting feature-map groups as cardinal groups. We introduce a new radix hy-
perparameter R that dictates the number of splits within a cardinal group. Then
the block input X are split into G = KR groups along the channel dimension
X = {X
1
, X
2
, ...X
G
} as shown in Figure 1. We apply a series of transformations
{F
1
, F
2
, ...F
G
} to each individual group, then the intermediate representation
of each group can be represented as U
i
= F
i
(X
i
), for i ∈ {1, 2, ...G}.
Input 1 Input r
…
+
Input 2
Global pooling
Dense c’ + BN + ReLU
Dense c
Dense c
r-Softmax
x
Dense c
x x
+
(h, w, c)
(h, w, c)
(c, )
(c’, )
(c, )
(c, )
(h, w, c)
Fig. 2: Split-Attention within a
cardinal group. For easy visu-
alization in the figure, we use
c = C/K in this figure.
Split Attention in Cardinal Groups. Fol-
lowing [30, 38], a combined representation for
each cardinal group can be obtained by fusing
via an element-wise summation across mul-
tiple splits. The representation for k-th car-
dinal group is
ˆ
U
k
=
P
Rk
i=R(k−1)+1
U
i
.
ˆ
U
k
∈
R
H×W×C/K
for k ∈ 1, 2, ...K. Global contex-
tual information with embedded channel-wise
statistics can be gathered with global aver-
age pooling across spatial dimensions s
k
∈
R
C/K
[29,38]. Here the c-th component is cal-
culated as:
s
k
c
=
1
H × W
H
X
i=1
W
X
j=1
ˆ
U
k
c
(i, j). (1)
A weighted fusion of the cardinal group
representation V
k
∈ R
H×W×C/K
is aggre-
gated using channel-wise soft attention, where
each feature-map channel is produced using a
weighted combination over splits. The c-th channel is calculated as:
V
k
c
=
R
X
i=1
a
k
i
(c)U
R(k−1)+r
, (2)
where a
k
i
(c) denotes a (soft) assignment weight given by:
a
k
i
(c) =
exp(G
c
i
(s
k
))
P
R
j=0
exp(G
c
j
(s
k
))
if R > 1,
1
1+exp(−G
c
i
(s
k
))
if R = 1,
(3)
and mapping G
c
i
determines the weight of each split for the c-th channel based
on the global context representation s
k
.
剩余21页未读,继续阅读
839 浏览量
2022-02-07 上传
104 浏览量
193 浏览量
165 浏览量
137 浏览量
104 浏览量
137 浏览量
2023-04-05 上传

佑林杉
- 粉丝: 10
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







