IKAnalyzer3.2.8源码解析:分词原理与架构探讨
需积分: 10 169 浏览量
更新于2024-09-13
收藏 631KB PDF 举报
"这篇文档详细介绍了IKAnalyzer3.2.8的原理和源码分析,主要包括系统架构、接口单元、分词单元以及字典内存保存结构。作者关注于IKAnalyzer的核心组件,如分词器、查询分析器和相似度评估器,并详细阐述了分词过程中的细分步骤和字典文件的组织方式。"
IKAnalyzer3.2.8是一款基于Lucene的中文分词器,广泛应用于搜索引擎和信息检索系统。这个版本主要由以下几个部分构成:
1. **系统架构**:IKAnalyzer3.2.8的架构设计简洁而高效,包括分词器、查询分析器和相似度评估器等核心组件。
- **IK分词器**:是IKAnalyzer的核心,实现了两种分词策略。最细粒度切分旨在尽可能多地切分出词汇,而最大词长切分则是对最细粒度结果的优化,以获取更长的词组。
- **IK查询分析器**:专为Solr查询优化,处理查询语句,确保在查询时能准确匹配到相关文档。
- **相似度评估器**:IKAnalyzer自定义了相似度评估器IKSimilarity,通过调整协调因子(coord方法)来提升多词元匹配的文档相似度。
2. **分词单元**:分词过程主要由主分析器IKSegmentation完成,它由CJKSegmenter(处理中文)、LetterSegmenter(处理字母)和QuantifierSegmenter(处理数量词)三个子单元协同工作。IKTokenizer是对此类的封装,方便用户使用。
3. **字典内存保存结构**:IKAnalyzer3.2.8使用多个字典文件,如主词典、姓氏词典、量词词典、后缀词典和副词、介词词典。这些字典存储在org.wltea.analyzer.dic包下,其中主词典是最主要的,包含大量的词汇,其他词典分别针对特定类型的词汇,如姓氏、量词等。部分词典(如主词典)支持动态扩展,以适应不断变化的词汇需求。
通过深入理解IKAnalyzer3.2.8的这些核心组成部分,开发者可以更好地定制分词规则,优化查询性能,以及调整文本相似度计算,以适应不同的应用场景。此外,熟悉源码分析对于调试和性能优化也极其重要。
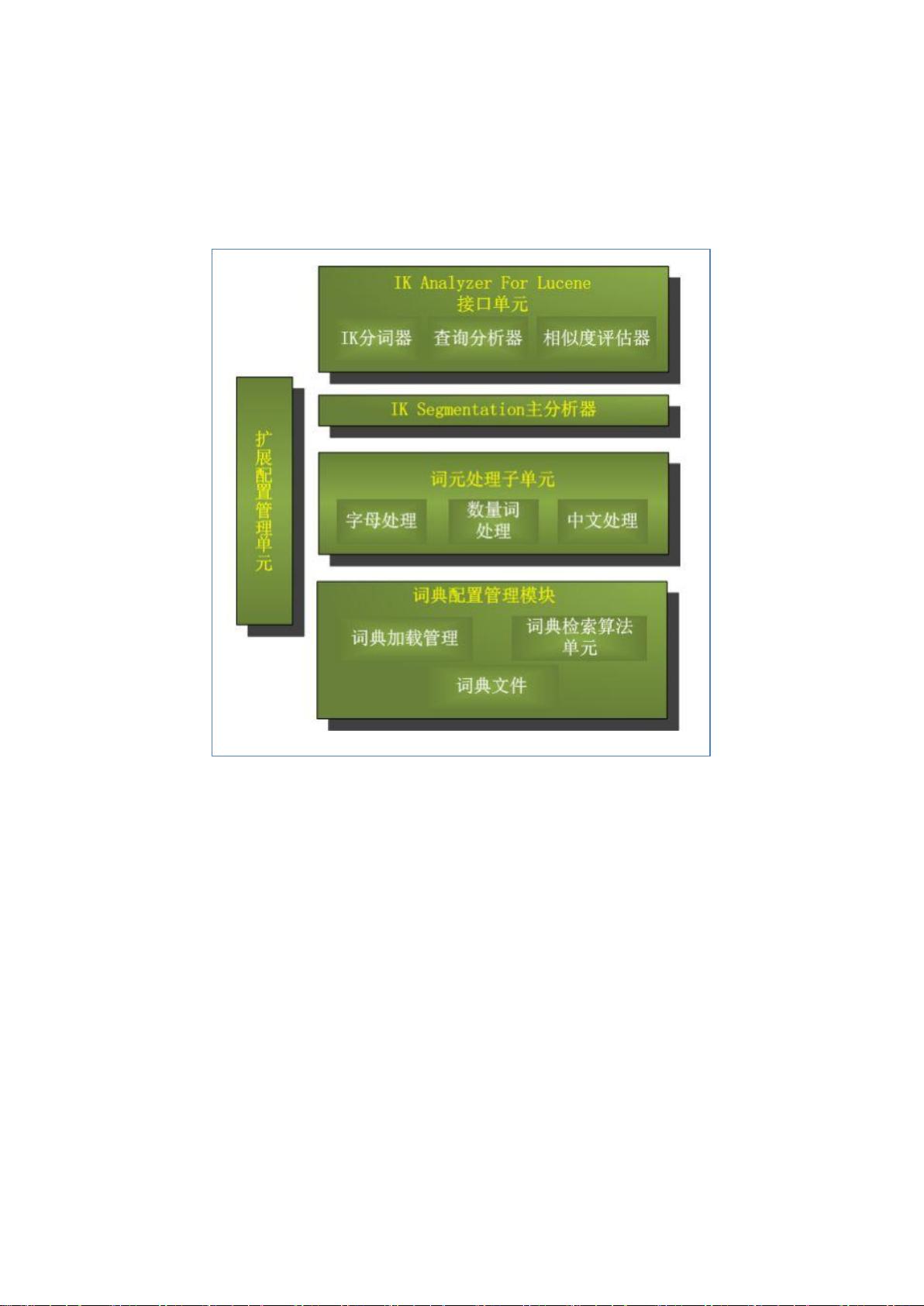
1. IKAnalyzer 3.2.8 原理及源码分析
1.1 IKAnalyzer 3.2.8 系统架构
1.2 IK 接口单元
1.2.1 IK 分词器
也就是类 org.wltea.analyzer.lucene.IKAnalyzer,提供了两种分词算法:最细粒
度切分算法和最大词长切分算法,最大词长切分算法只是对最细粒度切分算法结
果的再次加工。
1.2.2 IK 查询分析器
也就是类 org.wltea.analyzer.lucene.IKQueryParser,针对 solr 查询词做了优化。
1.2.3 相似度评估器
也就是类 org.wltea.analyzer.lucene.IKSimilarity,重载了 DefaultSimilarity 下的
下载后可阅读完整内容,剩余5页未读,立即下载
2020-12-03 上传
2021-05-31 上传
2021-03-25 上传
2012-01-07 上传
2013-09-28 上传
2018-09-12 上传
2011-07-27 上传

提灯夜行者
- 粉丝: 9
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
