50年超越K-means:数据聚类的演变、挑战与未来趋势
数据聚类作为一种基本的数据组织方式,已经历经半个世纪的发展,特别是自K-means算法诞生以来,它在众多领域中扮演着关键角色。本文回顾了K-means算法50年来的发展历程,深入探讨了用户面临的挑战和未来发展趋势。
在早期,K-means算法(最初由Stuart Lloyd在1957年提出)因其简单、易于实现和广泛应用而广受欢迎。它是一种基于迭代过程的聚类方法,通过不断优化质心来划分数据集为预设数量的簇。然而,K-means算法存在几个显著局限性:对初始聚类中心的选择敏感,无法处理非凸形状的簇,以及对异常值或噪声数据的鲁棒性较弱。
随着数据科学的发展,用户在使用K-means时面临着多种困境。首先,确定最佳的簇数(K值)是一个开放问题,通常需要依赖经验和试错。其次,算法对数据的分布和质量非常敏感,不适用于高度异质或非线性的数据集。此外,K-means无法处理高维数据中的“维度灾难”,因为它依赖于欧氏距离,这在高维空间中效率低下。
尽管如此,近年来的研究者们并未止步于K-means,而是探索了各种改进和扩展。比如,提出了基于密度的聚类方法,如DBSCAN,它们不依赖于预先设定的簇数;还有一些混合方法,如谱聚类,结合了图论和矩阵分解技术,能更好地处理非凸形状的簇。同时,半监督学习和深度学习也为数据聚类提供了新的视角,通过利用部分标记数据或深层神经网络结构,提升聚类性能。
对于未来的展望,数据聚类将继续朝着更自动化、鲁棒性和适应性强的方向发展。一种可能的趋势是集成机器学习和人工智能技术,例如强化学习,以智能选择聚类参数并优化聚类过程。同时,解释性聚类将成为关注焦点,因为理解聚类结果背后的逻辑对实际应用至关重要。随着大数据和云计算的普及,大规模、实时的在线聚类算法也将成为研究热点。
最后,尽管K-means作为经典算法的地位不可动摇,但用户面临的困境和未来发展趋势提醒我们,数据聚类领域还有许多未被充分挖掘的潜力等待挖掘。随着技术的进步,我们期待看到更多创新的聚类算法出现,使得数据的洞察力和价值得以进一步提升。
Jðc
k
Þ¼
X
x
i
2c
k
jjx
i
l
k
jj
2
:
The goal of K-means is to minimize the sum of the squared error
over all K clusters,
JðCÞ¼
X
K
k¼1
X
x
i
2c
k
jjx
i
l
k
jj
2
:
Minimizing this objective function is known to be an NP-hard prob-
lem (even for K =2)(Drineas et al., 1999). Thus K-means, which is a
greedy algorithm, can only converge to a local minimum, even
though recent study has shown with a large probability K-means
could converge to the global optimum when clusters are well sep-
arated (Meila, 2006). K-means starts with an initial partition with
K clusters and assign patterns to clusters so as to reduce the squared
error. Since the squared error always decreases with an increase in
the number of clusters K (with J(C)=0 when K = n), it can be mini-
mized only for a fixed number of clusters. The main steps of K-
means algorithm are as follows (Jain and Dubes, 1988):
1. Select an initial partition with K clusters; repeat steps 2 and 3
until cluster membership stabilizes.
2. Generate a new partition by assigning each pattern to its closest
cluster center.
3. Compute new cluster centers.
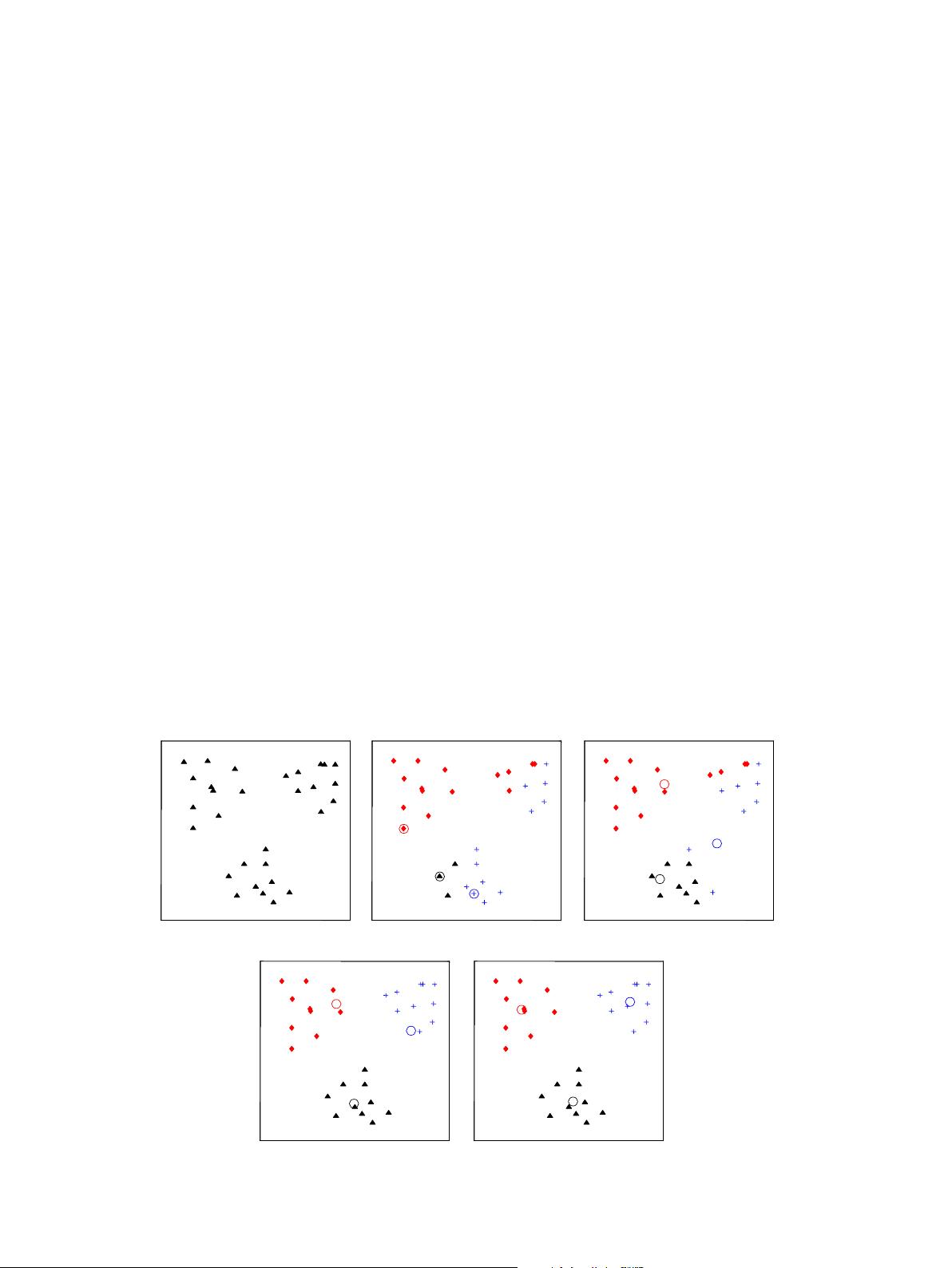
Fig. 4 shows an illustration of the K-means algorithm on a 2-
dimensional dataset with three clusters.
2.4. Parameters of K-means
The K-means algorithm requires three user-specified parame-
ters: number of clusters K, cluster initialization, and distance met-
ric. The most critical choice is K. While no perfect mathematical
criterion exists, a number of heuristics (see (Tibshirani et al.,
2001), and discussion therein) are available for choosing K. Typi-
cally, K-means is run independently for different values of K and
the partition that appears the most meaningful to the domain ex-
pert is selected. Different initializations can lead to different final
clustering because K-means only converges to local minima. One
way to overcome the local minima is to run the K-means algo-
rithm, for a given K, with multiple different initial partitions and
choose the partition with the smallest squared error.
K-means is typically used with the Euclidean metric for com-
puting the distance between points and cluster centers. As a result,
K-means finds spherical or ball-shaped clusters in data. K-means
with Mahalanobis distance metric has been used to detect hyper-
ellipsoidal clusters (Mao and Jain, 1996), but this comes at the ex-
pense of higher computational cost. A variant of K-means using the
Itakura–Saito distance has been used for vector quantization in
speech processing (Linde et al., 1980) and K-means with L
1
dis-
tance was proposed in (Kashima et al., 2008). Banerjee et al.
(2004) exploits the family of Bregman distances for K-means.
2.5. Extensions of K-means
The basic K-means algorithm has been extended in many differ-
ent ways. Some of these extensions deal with additional heuristics
involving the minimum cluster size and merging and splitting clus-
ters. Two well-known variants of K-means in pattern recognition
literature are ISODATA Ball and Hall (1965) and FORGY Forgy
(1965). In K-means, each data point is assigned to a single cluster
(called hard assignment). Fuzzy c-means, proposed by Dunn
(1973) and later improved by Bezdek (1981), is an extension of
K-means where each data point can be a member of multiple clus-
ters with a membership value (soft assignment). A good overview of
fuzzy set based clustering is available in (Backer, 1978). Data
reduction by replacing group examples with their centroids before
clustering them was used to speed up K-means and fuzzy C-means
in (Eschrich et al., 2003). Some of the other significant modifica-
(a) Input data (b) Seed point selection (c) Iteration 2
(d) Iteration 3 (e) Final clustering
Fig. 4. Illustration of K-means algorithm. (a) Two-dimensional input data with three clusters; (b) three seed points selected as cluster centers and initial assignment of the
data points to clusters; (c) and (d) intermediate iterations updating cluster labels and their centers; (e) final clustering obtained by K-means algorithm at convergence.
654 A.K. Jain / Pattern Recognition Letters 31 (2010) 651–666
剩余15页未读,继续阅读
2015-04-18 上传
2018-04-14 上传
2024-05-30 上传
2022-07-13 上传
2021-05-30 上传
2022-07-14 上传
2022-07-14 上传
2021-04-16 上传

sever2011
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
