CUDA并行归约优化策略详解:避免全局同步挑战
需积分: 22 185 浏览量
更新于2024-07-19
收藏 7.84MB PDF 举报
在CUDA编程中,优化并行规约(Parallel Reduction)是一项关键且常见的任务,特别是在处理大数据集时,它作为性能优化的重要案例。并行规约涉及在一个多线程环境中,每个线程对数组元素执行某种操作,最终合并所有线程的结果,形成全局结果。这个过程看似简单,但在实践中却涉及到多种策略和挑战。
首先,理解并行规约的基本概念至关重要。它是一种基础的数据并行运算,通常用于求和、最小值、最大值等操作。在CUDA中,由于其易实现但不易优化的特点,优化并行规约可以显著提升代码的性能。为了处理非常大的数组,并确保GPU的所有处理器都被充分利用,开发者可能需要利用多个线程块(Thread Blocks),每个块负责处理部分数组。
一种常见的优化策略是采用树状结构方法,也就是在每个线程块内部使用递归或分治法进行局部规约,然后通过线程间的通信将部分结果传递给其他块。这种设计允许在GPU上并发地进行计算,避免全局同步,因为CUDA架构不支持跨线程块的全局同步,这会消耗大量的硬件资源。
然而,没有全局同步带来的问题是,我们必须找到一种有效的机制来协调各个线程块之间的进度。一种解决方案是使用分阶段的同步,比如在每个阶段完成一部分规约后再进行同步,或者使用异步通信技术,如CUDA的streaming multiprocessors (SM) 来避免不必要的阻塞。
另一个问题在于内存访问效率。规约操作通常涉及频繁的读写操作,如何避免 bank conflicts 和 memory coalescing 是优化的重要环节。这可以通过合理安排数据布局、优化内存访问模式以及利用共享内存来改善。
此外,还要注意减少数据复制和通信开销。尽可能减少数据在不同线程之间或线程块之间的交换次数,可以显著提高性能。有时,通过将计算和通信步骤结合起来,使用pipelining或多级流水线技术,可以在一定程度上隐藏通信延迟。
最后,随着硬件的进步,未来的GPU可能会引入更高级的同步机制或者专用的并行规约硬件,但这也将带来新的挑战和优化需求。优化并行规约需要深入理解CUDA架构,熟练掌握并行编程技巧,以及不断跟踪最新硬件发展动态,以实现高效、可扩展的并行计算。

7
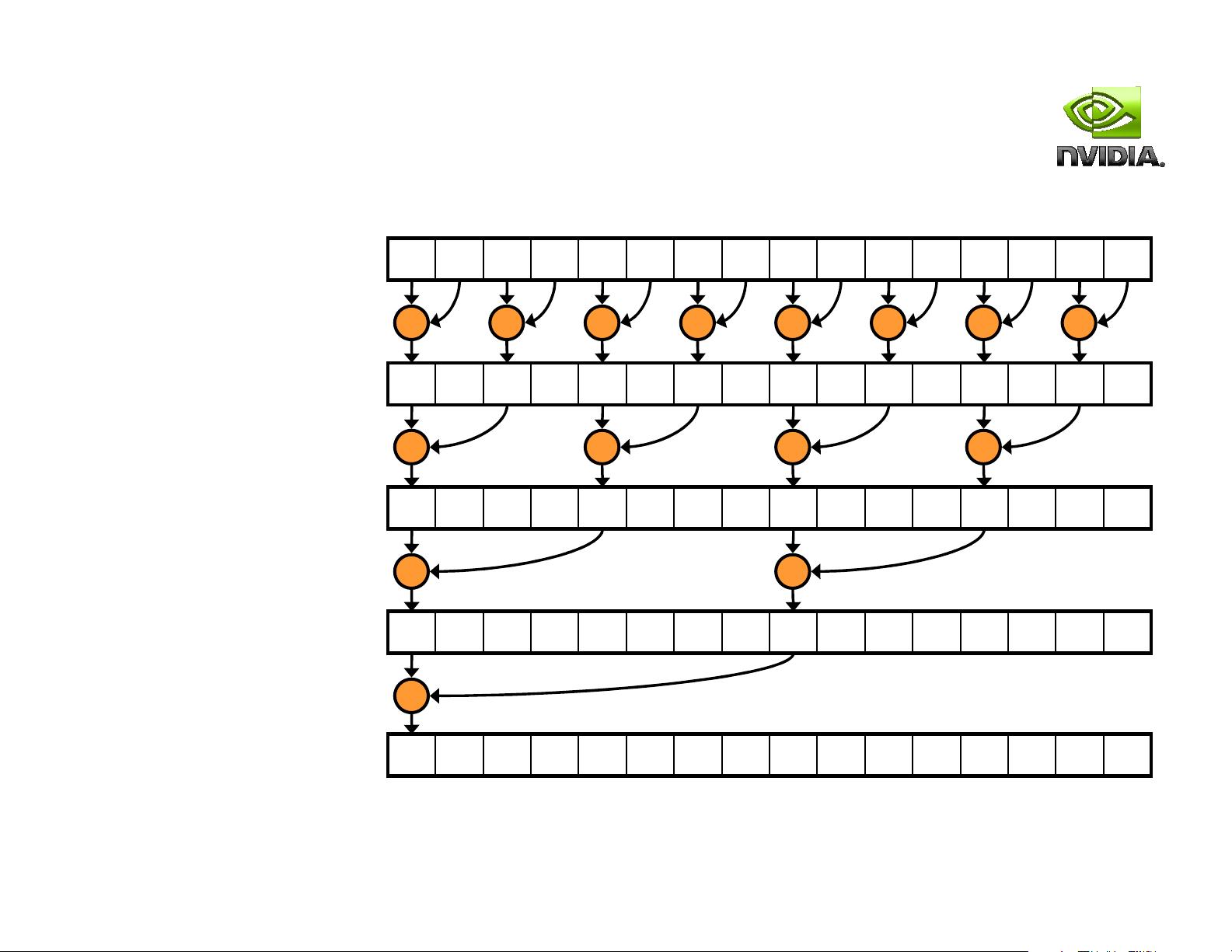
Reduction #1: Interleaved Addressing
Reduction #1: Interleaved Addressing
__global__ void reduce0(int *g_idata, int *g_odata) {
extern __shared__ int sdata[];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
剩余37页未读,继续阅读
2017-12-17 上传
2009-11-30 上传
2021-04-22 上传
2021-07-10 上传
2009-03-04 上传
2021-05-16 上传
2022-01-23 上传
2017-06-20 上传
2022-01-22 上传

Tiger-Li
- 粉丝: 1170
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- PythonLLVM:基于py2llvm的python的LLVM编译器
- 迷宫搜索游戏应用程序:简单的搜索视频游戏应用程序
- TaskTrackerApp
- DYL EXPRESS 中马集运仓-crx插件
- Security题库.zip
- Clip2VO:CA-Visual Object的Clipper兼容性库-开源
- 365步数运动宝v4.1.84
- ruscello:打字稿中的redux + react-redux
- Roman-Shchorba-KB20:ЛабораторніроботизДД“Базовіметодологіїтатехнологіїпрограмування”студентаакаееггрупиКІ
- PCAPFileAnalyzer:分析 PCAP 网络捕获文件
- 西安市完整矢量shp数据
- 泽邦集运代购和代运助手-crx插件
- python的tkinter库实现sqlite3数据库连接和操作样例源代码
- VC++2010学生版(离线安装包)
- basic-webpage
- flx:Emacs的模糊匹配...崇高的文字
