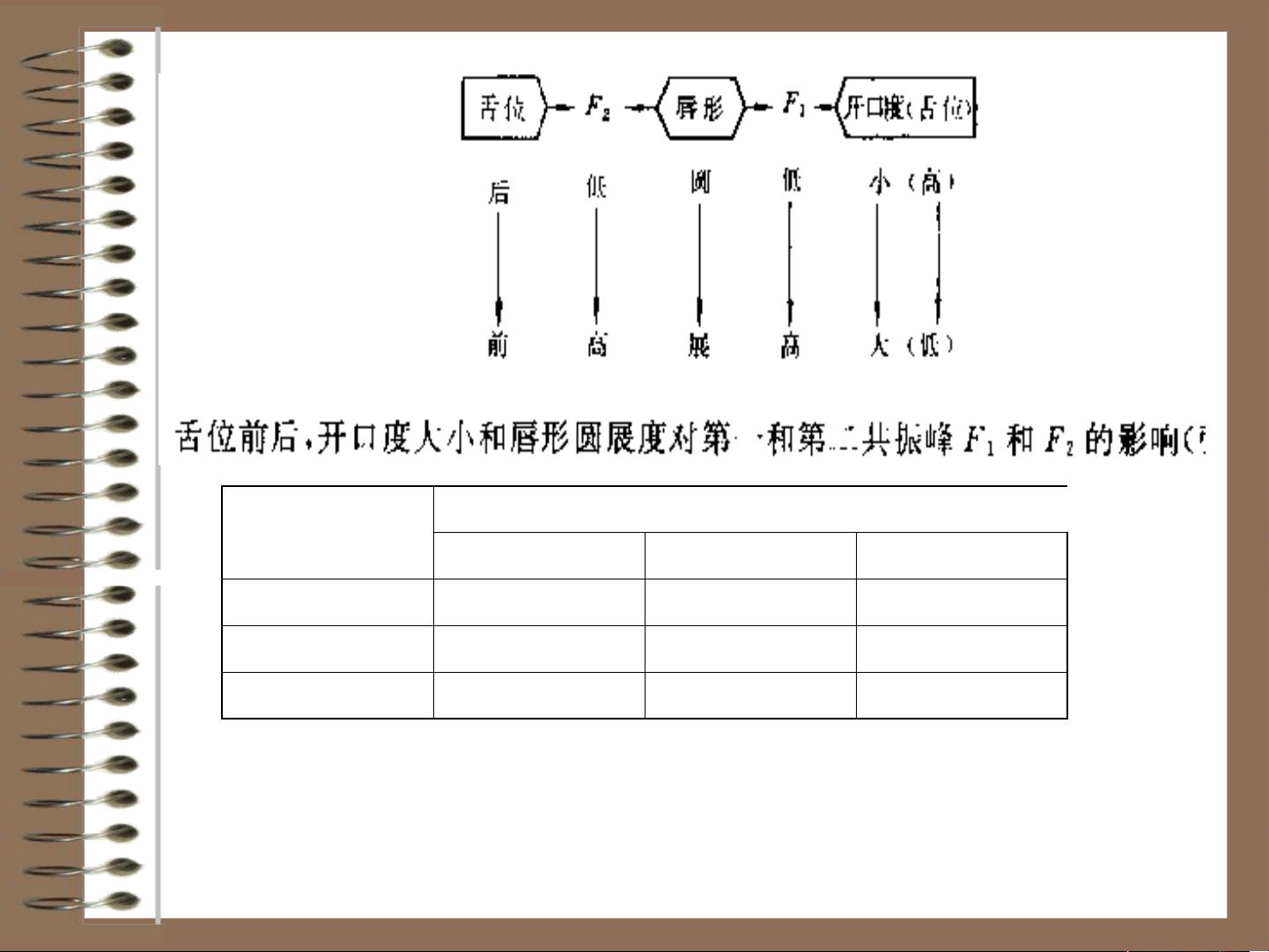
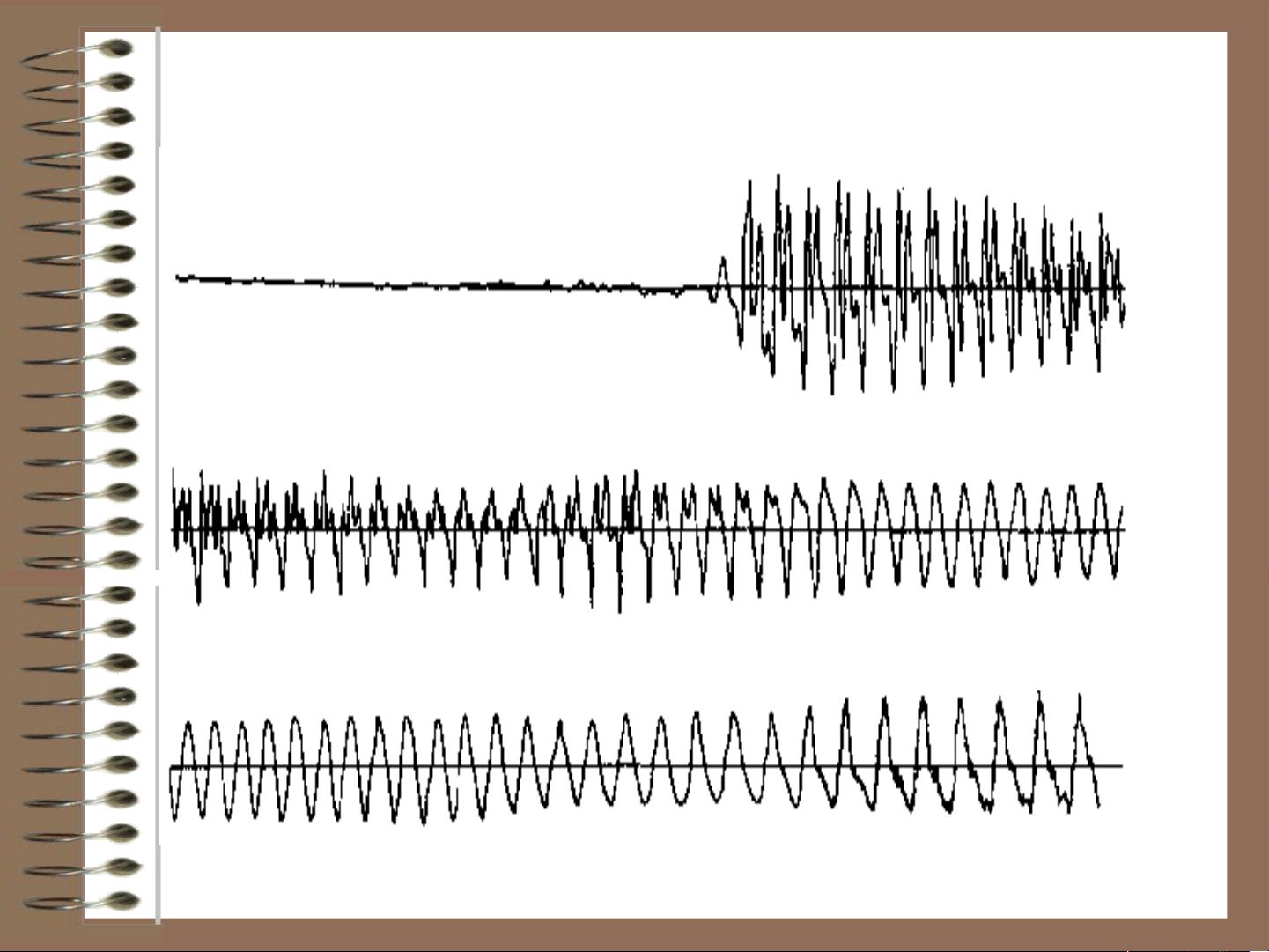
语音信号处理是一门重要的院定选修课,专注于利用数字信号处理技术对人类语音进行处理,其研究对象包括语言的声学表现。它是信号与信息处理领域中的一个热门交叉学科,涉及语言学、声学、认知学和心理学等多个学科,对于信息交换具有极高的实用价值,如语音编码(压缩)、语音合成(计算机语音生成)、语音识别(如语音输入设备)以及声纹识别等。 课程设置为期32学时,学分为2,旨在通过基础概念的建立和各种理论及算法的介绍,使学生对语音信号处理有一个全面的认识,为其未来在该领域的深入研究或实际应用奠定基础。语音信号处理的发展历程可以追溯到19世纪末的声码器,经过几十年的技术革新,如40年代的语谱仪、60年代的数字模型、70年代的LPC、80年代的VQ和HMM,以及90年代的神经网络技术,不断推动着该领域的进步。 第二章详述了语音信号处理的基础知识,首先,介绍了语音产生模型,如线性模型,以及语音学的三个核心阶段:发音(研究发音机制)、声学(解析信号的物理现象)和听觉(理解声音感知过程)。语音产生过程中,声带振动、声道共振频率(如第一至第三共振峰)起着关键作用,这些特征决定了语音的独特性,对于语音识别和合成有着不同的需求。 学习语音信号处理不仅有助于我们理解人类语音的物理机制,还能应用于通信、人工智能等领域,如智能助手的语音交互、语音转文字技术等。随着技术的不断发展,语音信号处理在未来将继续发挥重要作用,为人类生活带来更多便捷。
剩余63页未读,继续阅读