Structured Streaming:Apache Spark的实时处理新纪元
需积分: 9 178 浏览量
更新于2024-09-07
收藏 1.3MB PDF 举报
"Spark Streaming与Structured Streaming的对比及Structured Streaming的核心设计"
Structured Streaming是Apache Spark为了克服Spark Streaming的局限性而引入的一种高级实时流处理框架。Spark Streaming虽然在实时计算领域取得了显著成果,但其基于微批处理的DStream API在灵活性、可扩展性和容错性方面存在不足。Structured Streaming,作为Spark 2.0引入的新特性,旨在提供一种声明式编程模型,简化实时数据处理,并实现与批处理相同的抽象。
Structured Streaming的核心设计包括以下几个方面:
1. **持续查询(Continuous Query)**:Structured Streaming将流处理视为一个持续运行的查询,它会持续接收输入数据并不断更新结果。这种模型允许开发者定义一个查询,该查询会在新数据到达时自动执行,而不是一次性处理整个数据流。
2. **无状态与有状态计算**:无状态计算只关心当前批次的数据,而有状态计算则需要维护和更新之前批次的信息。Structured Streaming支持这两种计算模式,允许开发者进行复杂的窗口和聚合操作。
3. **精确一次(Exactly-once)语义**:通过使用事务和检查点机制,Structured Streaming可以确保在故障恢复后,处理结果的正确性不会受到影响,从而提供精确一次的语义。
4. **时间窗口和触发器**:Structured Streaming支持处理时间窗口和事件时间窗口,处理延迟数据和乱序事件。触发器定义了查询的执行频率,可以基于时间、数据量或完成状态来触发。
5. **集成SQL和DataFrame/Dataset API**:Structured Streaming与Spark SQL紧密集成,允许用户使用SQL或DataFrame/Dataset API进行流数据查询,这使得开发更加直观且易于理解。
6. **源和接收器的灵活性**:Structured Streaming支持多种数据源和接收器,如Kafka、Flume、HDFS等,这使得数据集成变得更加便捷。
7. **动态资源分配**:在Spark的弹性分布式数据集(RDD)上,资源分配是静态的,而在Structured Streaming中,可以动态调整资源,以适应数据流的变化。
8. **容错性**:Structured Streaming通过将数据流处理转换为连续查询,能够更好地处理节点故障和数据丢失,确保系统的高可用性和可靠性。
对比Spark Streaming,Structured Streaming在编程模型上的优势在于其声明式特性,这使得开发者可以更专注于描述他们想做什么,而Spark会负责处理数据处理的复杂性。此外,Structured Streaming在处理延迟数据和乱序事件的能力上也有所增强,更适用于现代实时数据处理场景,如物联网(IoT)、日志分析和实时监控等应用。
Structured Streaming通过提供一个更强大、灵活且易于使用的API,提升了Spark在实时数据处理领域的竞争力,成为现代大数据处理架构中的重要组成部分。
Input 数据源必须是可以 replay 的,如 Kafka,这样节点 crash 的时候就可以重新读取
input 数据。常的数据源包括 Amazon Kinesis, Apache Kafka 和件系统。
Output sink 必须要持写是幂等的。这个很好解,如果 output 持幂等写,那
么致性语义就是 at-least-once 。另外对于某些 sink, Structured Streaming 还提供
原写来保证 exactly-once 语义。
API: Structured Streaming 代码编写完全复 Spark SQL 的 batch API,也就是对个或者多
个 stream 或者 table 进 query。query 的结果是 result table,可以以多种同的模式
(append, update, complete)输出到外部存储中。另外,Structured Streaming 还提供
些 Streaming 处特有的 API:Trigger, watermark, stateful operator。
Execution: 复 Spark SQL 的执引擎。Structured Streaming 默认使类似 Spark
Streaming 的 micro-batch 模式,有很多好处,如动态负载均衡、再扩展、错误恢复以及
straggler (straggler 指的是哪些执明显慢于其他 task 的 task)重试。除 micro-batch 模
式,Structured Streaming 还提供基于传统的 long-running operator 的 continuous 处模
式。
Operational Features: wal 和状态存储,开发者可以做到集中形式的 rollback 和错误恢
复。还有些其他 Operational 上的 feature,这就细说。
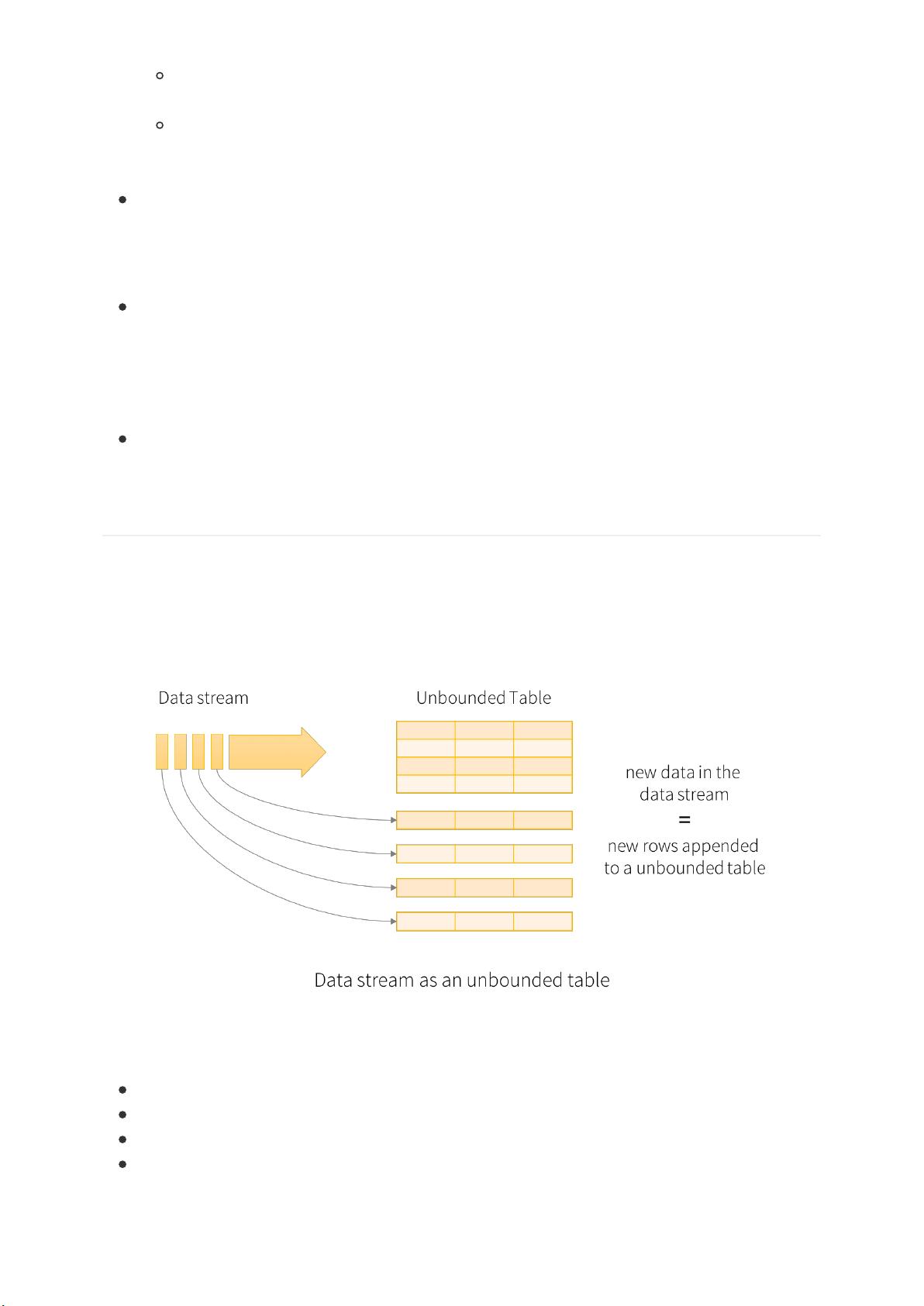
3. Structured Streaming
可能是受到 Google Dataflow 的批流统的思想的影响,Structured Streaming 将流式数据当成个
断增的 table,然后使和批处同套 API,都是基于 DataSet/DataFrame 的。如下图所示,
通过将流式数据解成张断增的表,从就可以像操作批的静态数据样来操作流数据。
在这个模型中,主要存在下个组成部分:
Input Unbounded Table: 流式数据的抽象表示
Query: 对 input table 的增式查询
Result Table: Query 产的结果表
Output: Result Table 的输出
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-01-26 上传
2014-05-16 上传
点击了解资源详情
2024-12-24 上传
2024-12-24 上传

charlesgranjor
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- SieveProject
- getmail-xoauth-git
- Java项目:共享自习室预约管理系统(java+SpringBoot+Thymeleaf+html+maven+mysql)
- Xshell+XFtp.zip
- MyYES ShopTool-crx插件
- AMQPStorm_Pool-1.0-py2.py3-none-any.whl.zip
- MySQL BIND SDB Driver-开源
- webscrap:网页的信息选择器
- lhyunited.github.io:主页
- hex转换成bin文件的工具
- AMQPStorm-2.4.0-py2.py3-none-any.whl.zip
- DistilBert:DistilBERT for Chinese 海量中文预训练蒸馏bert模型
- ProScheduler
- GoogleIABSampleApp
- aplica-o-de-transfer-ncias-banc-rias:.NET NET的紧急情况
- survey:AppSumo
