深度解析:迁移学习的领域划分与应用策略
迁移学习是一门研究如何在一个数据域(domain)中学习的知识或模型应用于另一个相关但不同的数据域的任务(task)中的计算机科学分支。本文档首先对迁移学习的基本概念进行了阐述。
数据域由特征空间χ和边缘概率分布P(X)构成,特征空间代表数据的特征表示,如在文本分类中,每个单词的二值特征表示(出现或不出现)。源数据域Ds与目标数据域Dt之间的差异可能体现在特征空间χ(如不同语言的文本)或边缘概率分布Ps(X)(如词汇使用的频率差异)上。
任务则是通过标签空间У和预测函数ƒ(X)来定义,如文本分类中的标签集合和文本分类的概率。源任务Ts与目标任务Tt的不匹配可能源于标签集合的差异、预测函数的要求不同(例如,源任务为二分类,而目标任务为多分类)或数据集中类别分布的不平衡。
迁移学习根据源和目标领域的相似性可分为几种类型:
1. 归纳式迁移学习:当源数据域拥有大量标签数据时,类似于多任务学习,可以利用已有的标签信息进行学习;若源数据域无标签,即为无标签源数据的自我学习,也称为半监督迁移学习。
2. 直推式迁移学习:针对特征空间χs与χt的不同(例如,不同的编码方式),或者特征空间相同但边缘分布不同(如Covariate Shift,数据分布变化),可以采用域适应或样本选择策略来调整模型。
3. 无监督迁移学习:在这种情况下,既没有标签信息也没有明确的特征空间差异,通常依赖于数据的内在结构或潜在的共享信息进行学习。
文档还提及了国内外迁移学习的发展现状,强调了归纳式迁移学习在大量标签数据支持下的应用价值,以及无监督迁移学习作为未来研究热点的前景。迁移学习是一个灵活且具有挑战性的领域,它旨在通过跨领域知识转移来提高目标任务的性能,尤其在数据稀缺的情况下,对提升机器学习模型的泛化能力具有重要意义。
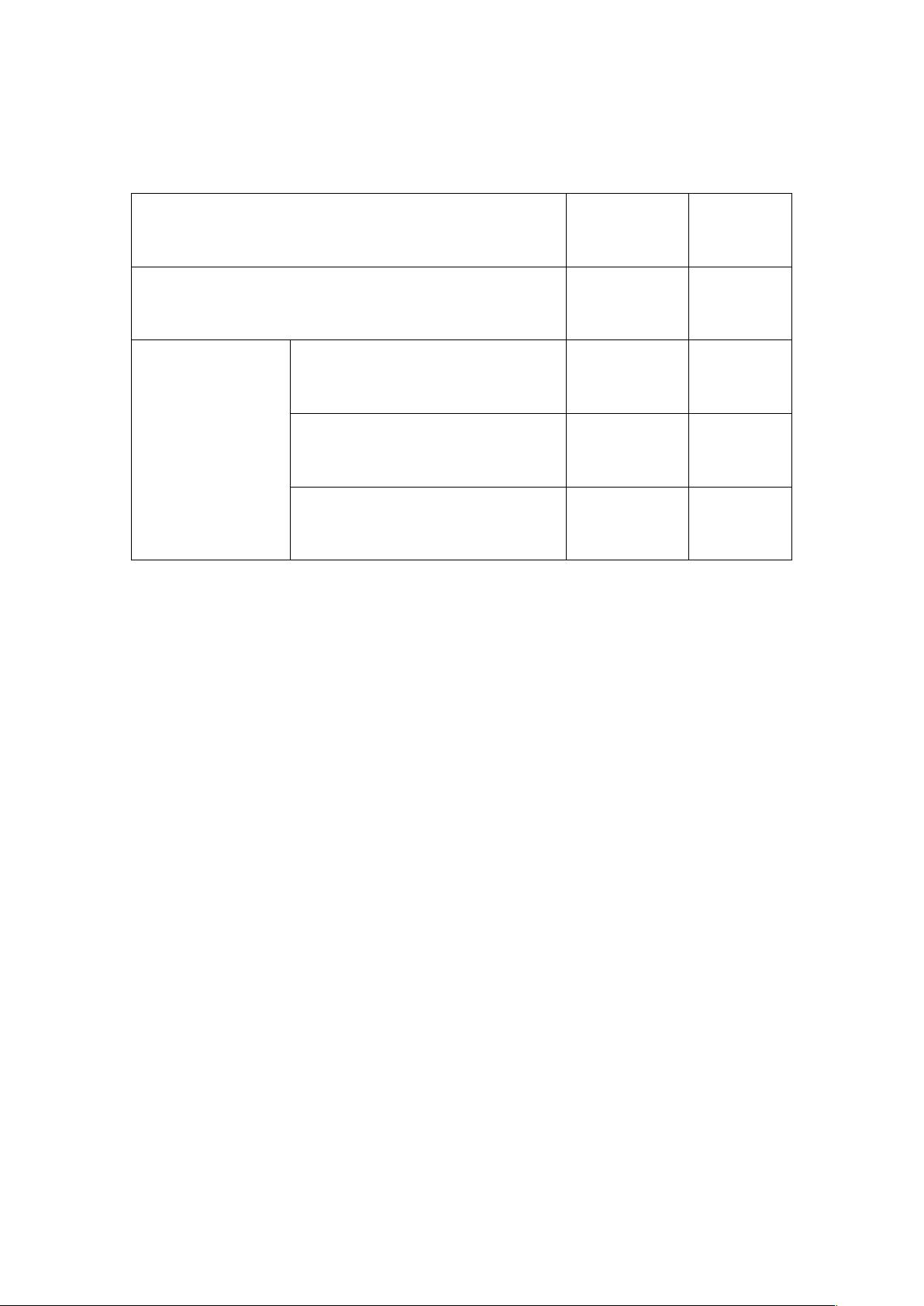
根据源领域和目标领域的相似度,可以将情况总结如下:
Ds&Dt Ts&Tt
传统机器学习 相同 相同
迁移学习 归纳式迁移学习 相同
/
相关 相关
无监督迁移学习 相关 相关
直推式迁移学习 相关 相同
根据每一种类型的迁移学习,又可根据标签数据的多少分情况讨论:
1.
归纳式迁移学习
a.
源数据域包含有大量标签数据,这时归纳式迁移学习和多任务学习类似。
b.
源数据域没有可用的标签数据,这时归纳式迁移学习相当于自我学习。
2.
直推式迁移学习
a.
特征空间不同
χs≠χt
b.
特征空间相同
χs=χt
但是边缘分布不同
Ps(X)≠Pt(X)
,此时可用域适应,样
本选择偏差和
Covariate Shift
。
剩余10页未读,继续阅读
275 浏览量
594 浏览量
451 浏览量
1502 浏览量
2196 浏览量
223 浏览量
176 浏览量
451 浏览量
1257 浏览量

xf__mao
- 粉丝: 843
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
