Python Scrapy+Django新闻系统详解:分布式爬虫与前后端架构
188 浏览量
更新于2024-09-01
3
收藏 1018KB PDF 举报
本文档详细介绍了基于Python的Scrapy分布式爬虫框架与Django前后端开发的综合信息系统项目。首先,作者强调了项目的特点,即使用Scrapy、Gerapy、NLP(自然语言处理)以及Django等成熟框架和技术进行构建,旨在实现新闻信息的高效抓取、处理和展示。
项目的主体部分分为以下几个关键环节:
1. **Scrapy爬虫框架与整体框架设置**:Scrapy是一个强大的网络爬虫框架,用于高效地抓取网页数据。在这里,开发者会介绍如何配置Scrapy,包括设置下载器、解析器等组件,以及如何定义规则来定位和提取所需的信息。
2. **Gerapy分布式部署与任务管理**:Gerapy作为Scrapy的补充,提供分布式爬虫功能,通过分布式架构可以提高爬取效率。这部分将涉及如何在多个节点上部署任务,管理和调度爬虫作业。
3. **原始数据处理流程与算法应用**:获取的数据经过清洗和预处理后,可能需要进行NLP算法的应用,如文本分类、情感分析等,以提取更有价值的信息。
4. **Django前后端分离系统与Web展现**:Django是Python的全栈Web框架,这里将展示如何设计并实现前后端分离的架构,包括后端API的开发和前端页面的渲染。
5. **Django内容管理与Web展示**:包括后台管理系统的设计,如用户权限管理、数据存储和编辑,以及前台展示页面的制作和功能实现,确保用户友好的交互体验。
6. **开发工具与环境**:文章提到了使用的开发工具(如Anaconda和PyCharm)以及开发环境(Windows10/CentOS7.x、Python3.6.5、Django3.x),以及相关的数据库(MySQL5.7和MongoDB3.4)和Python依赖库。
7. **成品展示**:最后,文档提供了各个阶段的成果展示,包括Scrapy爬虫脚本、Grapy部署、NLP应用示例、Django后台管理系统的截图或功能演示等。
阅读这份文档,读者可以深入了解一个实际的Python信息系统开发过程,涵盖了从底层爬虫技术到高级Web应用的全面内容。
Python信息系统(信息系统(Scrapy分布式分布式+Django前后端)前后端)-1.项目介绍篇项目介绍篇
原创不易,转载请标明出处,谢谢。原创不易,转载请标明出处,谢谢。
一、项目介绍一、项目介绍
基于基于基于基于Python基于基于Scrapy+Gerapy+NLP+Django搭建的新闻整套系统框架结构,都是使用现成的框架及算法等内容进行组合构建的整套系统。搭建的新闻整套系统框架结构,都是使用现成的框架及算法等内容进行组合构建的整套系统。
项目展示网址项目展示网址
二、二、 其中主要流程包括其中主要流程包括
Scrapy爬虫框架、整体框架设置
Gerapy分布式部署、任务管理
原始数据处理流程及算法应用
Django前后端分离系统及Web展现
相关说明
该项目全部内容Link
Python信息系统(Scrapy分布式+Django前后端)-1.项目介绍篇
Python信息系统(Scrapy分布式+Django前后端)-2.Scrapy配置篇
Python信息系统(Scrapy分布式+Django前后端)-3.Scrapy抓取篇
Python信息系统(Scrapy分布式+Django前后端)-4.Gerapy爬虫分布式部署
Python信息系统(Scrapy分布式+Django前后端)-5.数据清洗和处理篇
Python信息系统(Scrapy分布式+Django前后端)- 6.Django新闻系统展示篇
Python信息系统(Scrapy分布式+Django前后端)- 7.Django内容后台管理系统配置篇
Python信息系统(Scrapy分布式+Django前后端)- 8.Django内容后台管理系统管理模块篇
Python信息系统(Scrapy分布式+Django前后端)- 9.Django前台Web展示部署
Python信息系统(Scrapy分布式+Django前后端)- 10.Django前台HTML功能
三、成品展示三、成品展示
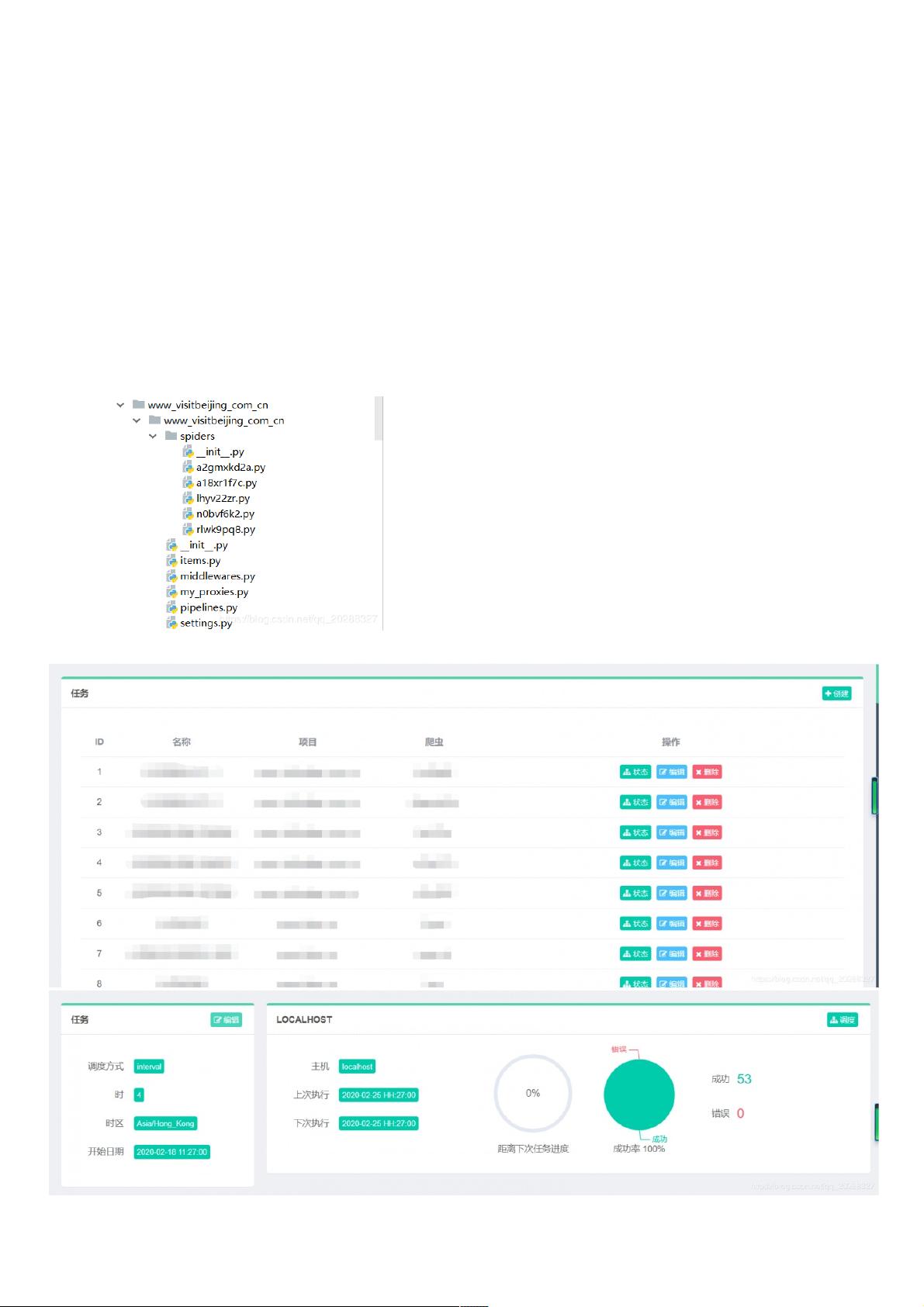
1.Scrapy部分(爬虫脚本)部分(爬虫脚本)
2.Grapy部署(爬虫部署)部署(爬虫部署)
3.NLP基础的应用(数据清洗和算法应用)基础的应用(数据清洗和算法应用)
下载后可阅读完整内容,剩余6页未读,立即下载
2019-09-18 上传
2021-02-04 上传
2024-09-14 上传
2023-04-04 上传
2024-10-26 上传
2024-11-09 上传
2023-05-22 上传
2024-06-16 上传

weixin_38669793
- 粉丝: 6
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | mtgpu-0.2.5-py3-none-any.whl
- endpoint-testing-afternoon:一个下午的项目,以帮助使用Postman巩固测试端点
- 经济中心
- z7-mybatis:针对mybatis框架的练习,目前主要技术栈包含springboot,mybatis,grpc,swgger2,redis,restful风格接口
- Cloudslides-Android:云幻灯同步演示应用-Android Client
- testingmk:做尼采河
- ecom-doc-static
- kindle-clippings-to-markdown:将Kindle的“剪贴”文件转换为Markdown文件,每本书一个
- 减去图像均值matlab代码-TVspecNET:深度学习的光谱总变异分解
- 自动绿色
- Alexa-Skills-DriveTime:该存储库旨在演示如何建立ALEXA技能,以帮助所有人了解当前流量中从源头到达目的地所花费的时间
- 灰色按钮克星易语言版.zip易语言项目例子源码下载
- HTML5:基本HTML5
- dubbadhar-light
- 使用Xamarin Forms创建离线移动密码管理器
- matlab对直接序列扩频和直接序列码分多址进行仿真实验源代码
